
_______ ________ __
/ | | | | |
| __| | __ | | |
\_ |_ | | _| | | |
__\ \ | |_| | | |_____
| | | | | |
|_______/ |_____/\_| |________|
SQL SERVER
sql.md 13/05/2025
ultimeccol.com
Sommaire
Definition
CHAPITRE 1 - Syntaxe TSQL
1.1. Avant de commencer
1.2. Modifications de la base
1.3. Requêtes <b>de base</b>
1.4. SQL Sous-requête
1.5. Jointure SQL
1.6. Traitement de masse
- INSERT SELECT
- Update Join
- Delete Join
- Données dans un champ XML
- Données dans un champ en JSON
- Pagination avec Regroupement
- Trie de donnée avec pagination
- Bulk insert
1.7. Arbres de donnees
1.8. Sécurisation de scripts
CHAPITRE 2 - SQL Avancé
2.1. Index SQL
2.2. SQL EXPLAIN
2.3. Modes de verrouillage
2.4. Le transactionnel
2.5. Les triggers, spécialités du C/S
2.6. Les procédures stockées, régals du C/S
2.7. Les curseurs
2.8. Le journal, particularité des SGBD C/S
2.9. Les vues
2.10. Impact du nombre de colonnes
2.11. Gestion de base de donnée
- Lister les index de table
- Afficher l'espace de données utilisé par chaque table
- Clés étrangères
- Connexion depuis un autre ordinateur a votre base SQL Server
- Copier une base vers une version antérieur de SQL Server
- Pour afficher les tables contenant une référence à la table
- Trouver les requettes les plus gourmandes en CPU
CHAPITRE 3 - Architecture
3.1. Architecture avec une base synchronisé en lecture seule
3.2. Architecture de la réplication
3.3. Transfer de journaux
3.4. Architecture du Miroir
Definition:
Le SQL est un langage de requêtes descriptif, standard pour toutes les bases de données qui suivent le modèle relationnel. Ce langage permet toutes les opérations sur les données dans tous les cas d'utilisation de la base. Avec Oracle, on peut associer au SQL un langage procédural, le PL/SQL, qui ajoute de nombreuses possibilités dans la manipulation des données.
CHAPITRE 1 - Syntaxe TSQL
1.1. Avant de commencer
Commentaires en SQL
Il peut être intéressant dinsérer des commentaires dans les requêtes SQL pour mieux sy retrouver lorsquil y a de grosses requêtes complexes. Il y a plusieurs façons de faire des commentaires dans le langage SQL, qui dépendent notamment du Système de Gestion de Base de Données utilisé (SGBD) et de sa version.
Ligne de commentaire :
Le double tiret permet de faire un commentaire jusquà la fin de la ligne.
Exemple
SELECT * -- tout sélectionner
FROM table1 -- dans la table "table1"
SELECT * # MySql tout sélectionner
FROM table1 # MySql dans la TABLE "table1"
Commentaire multi-lignes : /* et */
Le commentaire multi-ligne à lavantage de pouvoir indiquer où commence et où se termine le commentaire. Il est donc possible de lutiliser en plein milieu dune requête SQL sans problème.
Exemple
SELECT * /* tout sélectionner */
FROM table1 /* dans la table "table1" */
WHERE 1 = /* exemple en milieu de requete */ 1
Bug potentiel pour les commentaires sur une ligne
Attention, dans certains contextes, si vous utilisez un système qui va supprimer les retours à la ligne, votre requête sera uniquement sur une ligne. Dans une telle situation, un commentaire effectué avec « » dans une requête peut donc créer un bug.
Par conséquent il faut se méfier de librairies externes qui peuvent ré-écrire les requêtes SQL ou alors tout simplement se méfier de copier/coller.
Nom des tables et colonnes
la notation des noms de table est différente selon les SGBD, par ailleurs un nom de table ou colonne qui est aussi un mot clé du langage SQL du moteur doit être strictement nomé avec la notation propre au langage du SGBD.
-- MySQL
`name`
-- SQLServer
[name]
1.2. Modifications de la base
SQL CREATE DATABASE
La création dune base de données en SQL est possible en ligne de commande. Même si les systèmes de gestion de base de données (SGBD) sont souvent utilisés pour créer une base, il convient de connaître la commande à utiliser, qui est très simple.
Pour créer une base de données qui sera appelé « ma_base » il suffit dutiliser la requête suivante qui est très simple :
CREATE DATABASE ma_base
Base du même nom qui existe déjà
Avec MySQL, si une base de données porte déjà ce nom, la requête retournera une erreur. Pour éviter davoir cette erreur, il convient dutiliser la requête suivante pour MySQL :
CREATE DATABASE IF NOT EXISTS ma_base
Loption IF NOT EXISTS permet juste de ne pas retourner derreur si une base du même nom existe déjà. La base de données ne sera pas écrasée.
Options
Dans le standard SQL la commande CREATE DATABASE nexiste normalement pas. En conséquence il revient de vérifier la documentation des différents SGBD pour vérifier les syntaxes possibles pour définir des options. Ces options permettent selon les cas, de définir les jeux de caractères, le propriétaire de la base ou même les limites de connexion.
SQL DROP DATABASE
En SQL, la commande DROP DATABASE permet de supprimer totalement une base de données et tout ce quelle contient. Cette commande est à utiliser avec beaucoup dattention car elle permet de supprimer tout ce qui est inclus dans une base: les tables, les données, les index
Pour supprimer la base de données « ma_base », la requête est la suivante :
DROP DATABASE ma_base
Attention : cela va supprimer toutes les tables et toutes les données de cette base. Si vous nêtes pas sûr de ce que vous faites, nhésitez pas à effectuer une sauvegarde de la base avant de supprimer.
Ne pas afficher derreur si la base nexiste pas
Par défaut, si le nom de base utilisé nexiste pas, la requête retournera une erreur. Pour éviter dobtenir cette erreur si vous nêtes pas sûr du nom, il est possible dutiliser loption IF EXISTS. La syntaxe sera alors la suivante :
DROP DATABASE IF EXISTS ma_base
SQL CREATE SCHEMA
Un schéma est un support logique d'objet de base de données. Un schéma de base de données d'un système de base de données est sa structure décrite dans un langage formel pris en charge par le système de gestion de base de données. La définition formelle d'un schéma de base de données est un ensemble de formules (phrases) appelées contraintes d'intégrité imposées à une base de données. Ces contraintes d'intégrité assurent la compatibilité entre les différentes parties du schéma. Toutes les contraintes peuvent être exprimées dans le même langage.
La création de schémas peut s'avérer utile lorsque des objets ont des références circulaires, c'est-à-dire lorsque nous devons créer deux tables dont chacune possède une clé étrangère faisant référence à l'autre table. Les différentes implémentations traitent les schémas de manière légèrement différente.
CREATE SCHEMA schema1
Le schema par défaut que sqlserver est dbo, il est possible d'attribuer un schema particulier selon l'utilisateur connecté.
Apres la création d'un schema il est possible de créer des tables dans un schema. Pour y acceder il faudra obligatoirement préfixer le nom de la table avec le nom du schéma
A savoir : il est possible d'accéder à une table d'une autre base avec spécifiant son "chemin" complet qui est composé du nom de la base, du nom du schema puis du nom de la table, par exemple : ma_base.dbo.ma_table
CREATE TABLE schema1.table ( )
SELECT * FROM schema1.table
SQL CREATE TABLE
La commande CREATE TABLE permet de créer une table en SQL. Un tableau est une entité qui est contenu dans une base de données pour stocker des données ordonnées dans des colonnes. La création dune table sert à définir les colonnes et le type de données qui seront contenus dans chacune des colonne (entier, chaîne de caractères, date, valeur binaire ).
La syntaxe générale pour créer une table est la suivante :
CREATE TABLE nom_de_la_table
(
colonne1 type_donnees,
colonne2 type_donnees,
colonne3 type_donnees,
colonne4 type_donnees
)
Dans cette requête, 4 colonnes ont été définies. Le mot-clé « type_donnees » sera à remplacer par un mot-clé pour définir le type de données (INT, DATE, TEXT ). Pour chaque colonne, il est également possible de définir des options telles que (liste non-exhaustive) :
- NOT NULL : empêche denregistrer une valeur nulle pour une colonne.
- DEFAULT : attribuer une valeur par défaut si aucune données nest indiquée pour cette colonne lors de lajout dune ligne dans la table.
- PRIMARY KEY : indiquer si cette colonne est considérée comme clé primaire pour un index.
Exemple
Imaginons que lon souhaite créer une table utilisateur, dans laquelle chaque ligne correspond à un utilisateur inscrit sur un site web. La requête pour créer cette table peut ressembler à ceci :
CREATE TABLE utilisateur
(
id INT PRIMARY KEY NOT NULL,
nom VARCHAR(100),
prenom VARCHAR(100),
email VARCHAR(255),
date_naissance DATE,
pays VARCHAR(255),
ville VARCHAR(255),
code_postal VARCHAR(5),
nombre_achat INT
)
Voici des explications sur les colonnes créées :
- id : identifiant unique qui est utilisé comme clé primaire et qui nest pas NULL
- nom : nom de lutilisateur dans une colonne de type VARCHAR avec 100 caractères au maximum
- prenom : idem mais pour le prénom
- email : adresse email enregistrée sous 255 caractères au maximum
- date_naissance : date de naissance enregistrée au format AAAA-MM-JJ (ex : '1973-11-17T00:00:00.000')
- pays : nom du pays de lutilisateur sous 255 caractères au maximum
- ville : idem pour la ville
- code_postal : 5 caractères du code postal
- nombre_achat : nombre dachat de cet utilisateur sur le site
Concernant le stockage des données :
- toute ligne d'une table est pourvue d'une matrice de nullabilité qui occupe de la place : 1 octets si la table a moins de 8 colonnes, 2 jusqu'à 16 colonnes.
- les types de données de taille fixe (DATE, INT, CHAR...), occupent toujours la même place que la données existe ou pas (NULL)
- les types de données de taille variable (VARCHAR, VARBINARY) occupent la même place que précédemment (par exemple une colonne VARCHAR(32) contenant 'toto', elle prendra 6 octets : 4 pour la donnée, 2 pour la taille de la donnée)
- depuis la version 2008 édition Enterprise uniquement, l'option sparse permet de compresser les informations inexistantes pour certains types de données. Reste que cela n'a d'efficacité qu'à partir de quelques millions de lignes, donc pour des VLDB !
SQL ALTER TABLE
La commande ALTER TABLE en SQL permet de modifier une table existante. Il est ainsi possible dajouter une colonne, den supprimer une ou de modifier une colonne existante, par exemple pour changer le type.
Dune manière générale, la commande sutilise de la manière suivante :
ALTER TABLE nom_table
instruction
Le mot-clé « instruction » ici sert à désigner une commande supplémentaire, qui sera détaillée ci-dessous selon laction que lon souhaite effectuer : ajouter, supprimer ou modifier une colonne.
Ajouter une colonne
Lajout dune colonne dans une table est relativement simple et peut seffectuer à laide dune requête ressemblant à ceci :
ALTER TABLE nom_table
ADD nom_colonne type_donnees
Exemple
Pour ajouter une colonne qui correspond à une rue sur une table utilisateur, il est possible dutiliser la requête suivante :
ALTER TABLE utilisateur
ADD adresse_rue VARCHAR(255)
Supprimer une colonne
Une syntaxe permet également de supprimer une colonne pour une table. Il y a 2 manières totalement équivalentes pour supprimer une colonne :
ALTER TABLE nom_table
DROP nom_colonne
Ou (le résultat sera le même)
ALTER TABLE nom_table
DROP COLUMN nom_colonne
Modifier une colonne
Pour modifier une colonne, comme par exemple changer le type dune colonne, il y a différentes syntaxes selon le SGBD.
-- MySQL
ALTER TABLE nom_table MODIFY nom_colonne type_donnees
-- PostgreSQL
ALTER TABLE nom_table ALTER COLUMN nom_colonne TYPE type_donnees
Ici, le mot-clé « type_donnees » est à remplacer par un type de données tel que INT, VARCHAR, TEXT, DATE
Renommer une colonne
Pour renommer une colonne, il convient dindiquer lancien nom de la colonne et le nouveau nom de celle-ci.
Pour MySQL, il faut également indiquer le type de la colonne.
-- MySql
ALTER TABLE nom_table CHANGE colonne_ancien_nom colonne_nouveau_nom type_donnees
-- PostgreSQL
ALTER TABLE nom_table RENAME COLUMN colonne_ancien_nom TO colonne_nouveau_nom
Ici « type_donnees » peut correspondre par exemple à INT, VARCHAR, TEXT, DATE
Pour PostgreSQL la syntaxe est plus simple et ressemble à ceci (le type nest pas demandé) :
SQL DROP TABLE
La commande DROP TABLE en SQL permet de supprimer définitivement une table dune base de données. Cela supprime en même temps les éventuels index, trigger, contraintes et permissions associés à cette table.
**Attention : ** il faut utiliser cette commande avec attention car une fois supprimée, les données sont perdues. Avant de lutiliser sur une base importante il peut être judicieux deffectuer un backup (une sauvegarde) pour éviter les mauvaises surprises.
Pour supprimer une table « nom_table » il suffit simplement dutiliser la syntaxe suivante :
DROP TABLE nom_table
A savoir : sil y a une dépendance avec une autre table, il est recommandé de la supprimer avant de supprimer la table. Cest le cas par exemple sil y a des clés étrangères.
Intérêts
Il arrive quune table soit créée temporairement pour stocker des données qui nont pas vocation à être réutilisées. La suppression dune table non utilisée est avantageux sur plusieurs aspects :
- Libérer de la mémoire et alléger le poids des backups,
- éviter des erreurs dans le futur si une table porte un nom similaire ou qui porte à confusion,
- Lorsquun développeur ou administrateur de base de données découvre une application, il est plus rapide de comprendre le système sil ny a que les tables utilisées qui sont présentes.
Exemple de requête
Imaginons quune base de données possède une table « client_2009 » qui ne sera plus jamais utilisé et qui existe déjà dans un ancien backup. Pour supprimer cette table, il suffit deffectuer la requête suivante :
DROP TABLE client_2009
Lexécution de cette requête va permettre de supprimer la table.
SQL TRUNCATE TABLE
En SQL, la commande TRUNCATE permet de supprimer toutes les données dune table sans supprimer la table en elle-même. En dautres mots, cela permet de purger la table. Cette instruction diffère de la commande DROP qui a pour but de supprimer les données ainsi que la table qui les contient.
**A noter : ** linstruction TRUNCATE est semblable à linstruction DELETE sans utilisation de WHERE. Parmi les petites différences TRUNCATE est toutefois plus rapide et utilise moins de ressources. Ces gains en performance se justifient notamment parce que la requête nindiquera pas le nombre denregistrement supprimés et quil ny aura pas denregistrement des modifications dans le journal.
Cette instruction sutilise dans une requête SQL semblable à celle-ci :
TRUNCATE TABLE `table`
Dans cet exemple, les données de la table « table » seront perdues une fois cette requête exécutée.
Exemple
Pour montrer un exemple concret de lutilisation de cette commande, nous pouvons imaginer un système informatique contenant la liste des fournitures dune entreprise. Ces données seraient tout simplement stockées dans une table « fourniture ».
Table « fourniture » :
| id | nom | date_ajout |
|---|---|---|
| 1 | Ordinateur | 2013-04-05 |
| 2 | Chaise | 2013-04-14 |
| 3 | Bureau | 2013-07-18 |
| 4 | Lampe | 2013-09-27 |
Il est possible de supprimer toutes les données de cette table en utilisant la requête suivante :
TRUNCATE TABLE `fourniture`
Une fois la requête exécutée, la table ne contiendra plus aucun enregistrement. En dautres mots, toutes les lignes du tableau présenté ci-dessus auront été supprimées.
1.3. Requêtes de base
SQL SELECT
Lutilisation la plus courante de SQL consiste à lire des données issues de la base de données. Cela seffectue grâce à la commande SELECT, qui retourne des enregistrements dans un tableau de résultat. Cette commande peut sélectionner une ou plusieurs colonnes dune table. Lutilisation basique de cette commande seffectue de la manière suivante :
SELECT nom_du_champ
FROM nom_du_tableau
Cette requête va sélectionner (SELECT) le champ « nom_du_champ » provenant (FROM) du tableau appelé « nom_du_tableau ».
Exemple
Imaginons une base de données appelée « client » qui contient des informations sur les clients dune entreprise.
Table « client » :
| identifiant | prenom | nom | ville |
|---|---|---|---|
| 1 | Pierre | Dupond | Paris |
| 2 | Sabrina | Durand | Nantes |
| 3 | Julien | Martin | Lyon |
| 4 | David | Bernard | Marseille |
| 5 | Marie | Leroy | Grenoble |
Si lon veut avoir la liste des nom et prénom des clients, il suffit deffectuer la requête suivante :
SELECT prenom, nom
FROM client
Résultat :
| prenom | nom |
|---|---|
| Pierre | Dupond |
| Sabrina | Durand |
| Julien | Martin |
| David | Bernard |
| Marie | Leroy |
Il est possible de retourner automatiquement toutes les colonnes dun tableau sans avoir à connaître le nom de toutes les colonnes. Au lieu de lister toutes les colonnes, il faut simplement utiliser le caractère « * » (étoile). Cest un joker qui permet de sélectionner toutes les colonnes. Il sutilise de la manière suivante :
SELECT * FROM client
Cette requête retourne exactement les mêmes colonnes quil y a dans la base de données. Dans notre cas, le résultat sera donc :
| identifiant | prenom | nom | ville |
|---|---|---|---|
| 1 | Pierre | Dupond | Paris |
| 2 | Sabrina | Durand | Nantes |
| 3 | Julien | Martin | Lyon |
| 4 | David | Bernard | Marseille |
| 5 | Marie | Leroy | Grenoble |
Il est très utile également d'afficher en premier une ou plusieurs colonnes spécifique sur des table comprenant beaucoup de colonnes pour retrouver rapidement l'information recherchée, avant d'afficher toutes les informations.
SELECT ville, client.* FROM client
Ordre des commandes du SELECT
Cette commande SQL est relativement commune car il est très fréquent de devoir lire les données issues dune base de données. Il existe plusieurs commandes qui permettent de mieux gérer les données que lont souhaite lire. Voici un petit aperçu des fonctionnalités possibles qui sont abordées sur le reste du document:
- Joindre un autre tableau aux résultats
- Filtrer pour ne sélectionner que certains enregistrements
- Classer les résultats
- Grouper les résultats pour faire uniquement des statistiques (note moyenne, prix le plus élevé )
Un requête SELECT peut devenir assez longue. Juste à titre informatif, voici une requête SELECT qui possède presque toutes les commandes possibles :
SELECT *
FROM TABLE
WHERE condition
GROUP BY expression
HAVING condition
{ UNION | INTERSECT | EXCEPT }
ORDER BY expression
LIMIT COUNT
OFFSET START
A noter : cette requête imaginaire sert principalement daide-mémoire pour savoir dans quel ordre sont utilisées chacune des commandes au sein dune requête SELECT.
SQL DISTINCT
Lutilisation de la commande SELECT en SQL permet de lire toutes les données dune ou plusieurs colonnes. Cette commande peut potentiellement afficher des lignes en double. Pour éviter des redondances dans les résultats il faut simplement ajouter DISTINCT après le mot SELECT. Lutilisation basique de cette commande consiste alors à effectuer la requête suivante :
SELECT DISTINCT ma_colonne
FROM nom_du_tableau
Cette requête sélectionne le champ « ma_colonne » de la table « nom_du_tableau » en évitant de retourner des doublons.
Requête pour Oracle
Pour le Système de Gestion de Bases de Données (SGBD) Oracle, cette requête est remplacée par la commande « UNIQUE » :
SELECT UNIQUE ma_colonne
FROM nom_du_tableau
Exemple
Prenons le cas concret dune table « client » qui contient des noms et prénoms :
| identifiant | prenom | nom |
|---|---|---|
| 1 | Pierre | Dupond |
| 2 | Sabrina | Bernard |
| 3 | David | Durand |
| 4 | Pierre | Leroy |
| 5 | Marie | Leroy |
En utilisant seulement SELECT tous les noms sont retournés, or la table contient plusieurs fois le même prénom (cf. Pierre). Pour sélectionner uniquement les prénoms uniques il faut utiliser la requête suivante :
SELECT DISTINCT prenom
FROM client
Résultat :
| prenom |
|---|
| Pierre |
| Sabrina |
| David |
| Marie |
Ce résultat n'affiche volontairement quune seule fois le prénom « Pierre » grâce à lutilisation de la commande DISTINCT qui naffiche que les résultats distincts.
Intérêt Lutilisation de la commande DISTINCT est très pratique pour éviter les résultats en doubles. Cependant, pour optimiser les performances il est préférable dutiliser la commande SQL GROUP BY lorsque cest possible.
Quand on utilise la commande DISTINCT il peut être judicieux d'inclure une clé primaire parmis les champs retournés même si on en a pas besoin. Par exemple, dans le cas d'une jointure avec une autre table "facture" ou chacunes de ses lignes possède un id et un champ numeroFacture unique par rapport à l'id. Si dans le distinct on ne met pas l'id de la table "facture", mais uniquement le champ numeroFacture, SQL mettra beaucoup de temps.
Immaginons un échéancier de paiements. Chaque paiement à échéance peut encaisser une ou plusieurs factures
SELECT DISTINCT /*factures.Id*/, factures.numeroFacture, paiementSchedules.id
FROM paiementSchedules
INNER JOIN tickets ON tickets.scheduleId = paiementSchedules.Id
INNER JOIN acomptes ON acomptes.ticketId = tickets.Id
INNER JOIN factures ON factures.Id = acomptes.factureId
WHERE paiementSchedules.id IN (123, 124, 125)
Pour cette requette, sql server ne semble pas bien optimisé et prendra beaucoup de temps. Mais si on rajoute l'id dans le select, sql server optimisera correctement l'exécution.
SQL AS (alias)
Dans le langage SQL il est possible dutiliser des alias pour renommer temporairement une colonne ou une table dans une requête. Cette astuce est particulièrement utile pour faciliter la lecture des requêtes.
Alias sur une colonne
Permet de renommer le nom dune colonne dans les résultats dune requête SQL. Cest pratique pour avoir un nom facilement identifiable dans une application qui doit ensuite exploiter les résultats dune recherche.
Cas concrets dutilisations :
Une colonne qui sappelle normalement c_iso_3166 peut être renommée « code_pays » (cf. le code ISO 3166 correspond au code des pays), ce qui est plus simple à comprendre dans le reste du code par un développeur.
Une requête qui utilise la commande UNION sur des champs aux noms différents peut être ambigu pour un développeur. En renommant les champs avec un même nom il est plus simple de traiter les résultats.
Lorsquune fonction est utilisée, le nom dune colonne peut-être un peu complexe. Il est ainsi possible de renommer la colonne sur laquelle il y a une fonction SQL. Exemple : SELECT COUNT(*) AS nombre_de_resultats FROM table.
Lorsque plusieurs colonnes sont combinées il est plus simple de renommer la nouvelle colonne qui est une concaténation de plusieurs champs.
La syntaxe pour renommer une colonne de colonne1 à c1 est la suivante :
SELECT colonne1 AS c1, colonne2
FROM `table`
Cette syntaxe peut également safficher de la façon suivante :
SELECT colonne1 c1, colonne2
FROM `table`
> **A noter : ** à choisir il est préférable dutiliser la commande «AS» pour > que ce soit plus explicite (plus simple à lire quun simple espace), dautant > plus que cest recommandé dans le standard ISO pour concevoir une requête SQL.
Exemple
Imaginons une site de-commerce qui possède une table de produits. Ces produits sont disponibles dans une même table dans plusieurs langues , dont le français. Le nom du produit peut ainsi être disponible dans la colonne « nom_fr_fr », ou « nom_en_gb ». Pour utiliser lun ou lautre des titres dans le reste de lapplication sans avoir à se soucier du nom de la colonne, il est possible de renommer la colonne de son choix avec un nom générique. Dans notre cas, la requête pourra ressemble à ceci :
SELECT p_id AS id,
p_nom_fr_fr AS nom,
p_description_fr_fr AS description,
p_prix_euro AS prix
FROM `produit`
Résultat :
| id | nom | description | prix |
|---|---|---|---|
| 1 | Ecran | Ecran de grandes tailles. | 399.99 |
| 2 | Clavier | Clavier sans fil. | 27 |
| 3 | Souris | Souris sans fil. | 24 |
| 4 | Ordinateur portable | Grande autonomie | 700 |
Comme nous pouvons le constater les colonnes ont été renommées.
Alias sur une table
Permet dattribuer un autre nom à une table dans une requête SQL. Cela peut aider à avoir des noms plus court, plus simple et plus facilement compréhensible. Ceci est particulièrement vrai lorsquil y a des jointures.
La syntaxe pour renommer une table dans une requête est la suivante :
SELECT *
FROM `nom_table` AS t1
Cette requête peut également sécrire de la façon suivante :
SELECT *
FROM `table` t1
Exemple
Imaginons que les produits du site e-commerce soient répartis dans des catégories. Pour récupérer la liste des produits en même temps que la catégorie auquel il appartient il est possible dutiliser une requête SQL avec une jointure. Cette requête peut utiliser des alias pour éviter dutiliser à chaque fois le nom des tables. La requête ci-dessous renomme la table « produit » en « p » et la table « produit_categorie » en « pc » (plus court et donc plus rapide à écrire) :
SELECT p_id, p_nom_fr_fr, pc_id, pc_nom_fr_fr
FROM `produit` AS p
LEFT JOIN `produit_categorie` AS pc ON pc.pc_id = p.p_fk_category_id
Cette astuce est encore plus pratique lorsquil y a des noms de tables encore plus compliqués et lorsquil y a beaucoup de jointures.
SQL WHERE
La commande WHERE dans une requête SQL permet dextraire les lignes dune base de données qui respectent une condition. Cela permet dobtenir uniquement les informations désirées.
La commande WHERE sutilise en complément à une requête utilisant SELECT. La façon la plus simple de lutiliser est la suivante :
SELECT nom_colonnes
FROM nom_table
WHERE condition
Exemple
Imaginons une base de données appelée « client » qui contient le nom des clients, le nombre de commandes quils ont effectuées et leur ville :
| id | nom | nbr_commande | ville |
|---|---|---|---|
| 1 | Paul | 3 | paris |
| 2 | Maurice | 0 | rennes |
| 3 | Joséphine | 1 | toulouse |
| 4 | Gérard | 7 | paris |
Pour obtenir seulement la liste des clients qui habitent à Paris, il faut effectuer la requête suivante :
SELECT *
FROM client
WHERE ville = 'paris'
Résultat :
| id | nom | nbr_commande | nbr_commande |
|---|---|---|---|
| 1 | Paul | 3 | paris |
| 4 | Gérard | 7 | paris |
**Attention : ** dans notre cas tout est en minuscule donc il ny a pas eu de problème. Cependant, si une table est sensible à la casse, il faut faire attention aux majuscules et minuscules.
Opérateurs de comparaison
Il existe plusieurs opérateurs de comparaison. La liste ci-jointe présente quelques uns des opérateurs les plus couramment utilisés.
| Opérateur | Description |
|---|---|
| = | égal |
| <> | Pas égal |
| != | Pas égal |
| > | Supérieur à |
| < | Inférieur à |
| >= | Supérieur ou égal à |
| <= | Inférieur ou égal à |
| IN | Liste de plusieurs valeurs possibles |
| BETWEEN | Valeur comprise dans un intervalle donné (utile pour les nombres ou dates) |
| LIKE | Recherche en spécifiant le début, milieu ou fin d'un mot. |
| IS NULL | Valeur est nulle |
| IS NOT NULL | Valeur n'est pas nulle |
> **Attention : ** il y a quelques opérateurs qui nexistent pas dans des > vieilles versions de systèmes de gestion de bases de données (SGBD). De plus, > il y a de nouveaux opérateurs non indiqués ici qui sont disponibles avec > certains SGBD. Nhésitez pas à consulter la documentation de MySQL, PostgreSQL > ou autre pour voir ce quil vous est possible de faire.
SQL AND et OR
Une requête SQL peut être restreinte à laide de la condition WHERE. Les opérateurs logiques AND et OR peuvent être utilisés au sein de la commande WHERE pour combiner des conditions.
Les opérateurs sont à ajoutés dans la condition WHERE. Ils peuvent être combinés à linfini pour filtrer les données comme souhaité.
Lopérateur AND permet de sassurer que la condition1 ET la condition2 soient vraies :
SELECT nom_colonnes
FROM nom_table
WHERE condition1 AND condition2
Lopérateur OR vérifie quant à lui que la condition1 OU la condition2 est vraie :
SELECT nom_colonnes FROM nom_table
WHERE condition1 OR condition2
Ces opérateurs peuvent être combinés à linfini et mélangés. Lexemple ci-dessous filtre les résultats de la table « nom_table » si condition1 ET (condition2 OU condition3) est vrai :
SELECT nom_colonnes FROM nom_table
WHERE condition1 AND (condition2 OR condition3)
Attention : il faut penser à utiliser des parenthèses lorsque cest nécessaire. Cela permet déviter les erreurs et améliore la lecture dune requête par un humain.
Exemples de données
Pour illustrer les prochaines commandes, nous allons considérer la table « produit » suivante :
| id | nom | categorie | stock | prix |
|---|---|---|---|---|
| 1 | ordinateur | informatique | 5 | 950 |
| 2 | clavier | informatique | 32 | 35 |
| 3 | souris | informatique | 16 | 30 |
| 4 | crayon | fourniture | 147 | 2 |
Opérateur AND
Lopérateur AND permet de joindre plusieurs conditions dans une requête. En gardant la même table que précédemment et pour filtrer uniquement les produits informatique qui sont presque en rupture de stock (moins de 20 produits disponibles) il faut exécuter la requête suivante :
SELECT * FROM produit
WHERE categorie = 'informatique' AND stock < 20
Résultat :
| id | nom | categorie | stock | prix |
|---|---|---|---|---|
| 1 | ordinateur | informatique | 5 | 950 |
| 3 | souris | informatique | 16 | 30 |
Opérateur OR
Pour filtrer les données afin d'avoir uniquement celles sur les produits « ordinateur » ou « clavier » il faut effectuer la recherche suivante :
SELECT * FROM produit
WHERE nom = 'ordinateur' OR nom = 'clavier'
Résultats :
| id | nom | categorie | stock | prix |
|---|---|---|---|---|
| 1 | ordinateur | informatique | 5 | 950 |
| 2 | clavier | informatique | 32 | 35 |
Combiner AND et OR
Il ne faut pas oublier que les opérateurs peuvent être combinés pour effectuer de puissantes recherches. Il est possible de filtrer les produits « informatique » avec un stock inférieur à 20 et les produits « fourniture » avec un stock inférieur à 200 avec la recherche suivante :
SELECT * FROM produit
WHERE ( categorie = 'informatique' AND stock < 20 )
OR ( categorie = 'fourniture' AND stock < 200 )
Résultats :
| id | nom | categorie | stock | prix |
|---|---|---|---|---|
| 1 | ordinateur | informatique | 5 | 950 |
| 2 | clavier | informatique | 32 | 35 |
| 4 | crayon | fourniture | 147 | 2 |
SQL IN
Lopérateur logique IN dans SQLsutilise avec la commande WHERE pour vérifier si une colonne est égale à une des valeurs comprise dans un set de valeurs déterminées. Cest une méthode simple pour vérifier si une colonne est égale à une valeur OU une autre valeur OU une autre valeur et ainsi de suite, sans avoir à utiliser de multiple fois lopérateur OR.
Pour chercher toutes les lignes où la colonne « nom_colonne » est égale à valeur 1' OU valeur 2' ou valeur 3', il est possible dutiliser la syntaxe suivante :
``
SELECT nom_colonne
FROM TABLE
WHERE nom_colonne IN ( valeur1, valeur2, valeur3, ... )
> A savoir : il ny a pas de limite au nombre darguments.
Cette syntaxe peut être associée à lopérateur NOT pour rechercher toutes les lignes qui ne sont pas égales à lune des valeurs stipulées.
Simplicité de lopérateur IN
La syntaxe utilisée avec lopérateur est plus simple que dutiliser une succession dopérateurs OR. Pour le montrer concrètement avec un exemple, voici 2 requêtes qui retourneront les mêmes résultats, lune utilise lopérateur IN, tandis que lautre utilise plusieurs OR.
Requête équivalent à OR avec lopérateur IN
-- Requete avec OR
SELECT prenom
FROM utilisateur
WHERE prenom = 'Maurice' OR prenom = 'Marie' OR prenom = 'Thimoté'
-- Requete avec IN
SELECT prenom
FROM utilisateur
WHERE prenom IN ( 'Maurice', 'Marie', 'Thimoté' )
Exemple
Imaginons une table « adresse » qui contient une liste dadresses associées à des utilisateurs dune application.
| id | id_user | addr_rue | addr_code_postal | addr_ville |
|---|---|---|---|---|
| 1 | 23 | 35 Rue Madeleine Pelletier | 25250 | Bournois |
| 2 | 43 | 21 Rue du Moulin Collet | 75006 | Paris |
| 3 | 65 | 28 Avenue de Cornouaille | 27220 | Mousseaux-Neuville |
| 4 | 67 | 41 Rue Marcel de la Provoté | 76430 | Graimbouville |
| 5 | 68 | 18 Avenue de Navarre | 75009 | Paris |
Si lon souhaite obtenir les enregistrements des adresses de Paris et de Graimbouville, il est possible dutiliser la requête suivante :
SELECT *
FROM adresse
WHERE addr_ville IN (
'Paris', 'Graimbouville' )
Résultats :
| id | id_user | addr_rue | addr_code_postal | addr_ville |
|---|---|---|---|---|
| 2 | 43 | 21 Rue du Moulin Collet | 75006 | Paris |
| 4 | 67 | 41 Rue Marcel de la Provoté | 76430 | Graimbouville |
| 5 | 68 | 18 Avenue de Navarre | 75009 | Paris |
SQL BETWEEN
Lopérateur BETWEEN est utilisé dans une requête SQL pour sélectionner un intervalle de données dans une requête utilisant WHERE. Lintervalle peut être constitué de chaînes de caractères, de nombres ou de dates. Lexemple le plus concret consiste par exemple à récupérer uniquement les enregistrements entre 2 dates définies.
Lutilisation de la commande BETWEEN seffectue de la manière suivante :
SELECT *
FROM TABLE
WHERE nom_colonne BETWEEN 'valeur1' AND 'valeur2'
La requête suivante retournera toutes les lignes dont la valeur de la colonne « nom_colonne » sera comprise entre valeur1 et valeur2.
Exemple : filtrer entre 2 dates
Imaginons une table « utilisateur » qui contient les membres dune application en ligne.
| id | nom | date_inscription |
|---|---|---|
| 1 | Maurice | 2012-03-02 |
| 2 | Simon | 2012-03-05 |
| 3 | Chloé | 2012-04-14 |
| 4 | Marie | 2012-04-15 |
| 5 | Clémentine | 2012-04-26 |
Si lon souhaite obtenir les membres qui se sont inscrit entre le 1 avril 2012 et le 20 avril 2012 il est possible deffectuer la requête suivante :
SELECT *
FROM utilisateur
WHERE date_inscription BETWEEN 2012-04-01' AND 2012-04-20'
Résultat :
| id | nom | date_inscription |
|---|---|---|
| 3 | Chloé | 2012-04-14 |
| 4 | Marie | 2012-04-15 |
Exemple : filtrer entre 2 entiers
Si lon souhaite obtenir tous les résultats dont lidentifiant nest pas situé entre 4 et 10, il faudra alors utiliser la requête suivante :
SELECT *
FROM utilisateur
WHERE id NOT BETWEEN 4 AND 10
Résultat :
| id | nom | date_inscription |
|---|---|---|
| 1 | Maurice | 2012-03-02 |
| 2 | Simon | 2012-03-05 |
| 3 | Chloé | 2012-04-14 |
Lautre élément important à savoir cest que toutes les bases de données ne gèrent pas lopérateur BETWEEN de la même manière. Certains systèmes vont inclure les valeurs qui définissent lintervalle tandis que dautres systèmes considèrent ces valeurs sont exclues. Il est important de consulter la documentation officielle de la base de données que vous utilisez pour avoir une réponse exacte à ce sujet.
SQL LIKE
Lopérateur LIKE est utilisé dans la clause WHERE des requêtes SQL. Ce mot-clé permet deffectuer une recherche sur un modèle particulier. Il est par exemple possible de rechercher les enregistrements dont la valeur dune colonne commence par telle ou telle lettre. Les modèles de recherches sont multiple.
La syntaxe à utiliser pour utiliser lopérateur LIKE est la suivante :
SELECT *
FROM TABLE
WHERE colonne LIKE modele
Dans cet exemple le « modèle » na pas été défini, mais il ressemble très généralement à lun des exemples suivants :
- LIKE %a : le caractère « % » est un caractère joker qui remplace tous les autres caractères. Ainsi, ce modèle permet de rechercher toutes les chaines de caractères qui se terminent par un « a ».
- LIKE a% : ce modèle permet de rechercher toutes les lignes de « colonne» qui commencent par un « a ».
- LIKE %a% : ce modèle est utilisé pour rechercher les enregistrements qui utilisent le caractère « a ».
- LIKE pa%on : ce modèle permet de rechercher les chaines qui commence par « pa » et qui se terminent par « on », comme « pantalon » ou « pardon ».
- LIKE a_c : peu utilisé, le caractère « _ » (underscore) peut être remplacé par nimporte quel caractère, mais un seul caractère uniquement (alors que le symbole pourcentage « % » peut être remplacé par un nombre variable de caractères . Ainsi, ce modèle permet de retourner les lignes « aac », « abc » ou même « azc ».
Exemple
Imaginons une table « client » qui contienne les enregistrements dutilisateurs
| id | nom | ville |
|---|---|---|
| 1 | Léon | Lyon |
| 2 | Odette | Nice |
| 3 | Vivien | Nantes |
| 4 | Etienne | Lille |
Obtenir les résultats qui commencent par « N »
Si lon souhaite obtenir uniquement les clients des villes qui commencent par un « N », il est possible dutiliser la requête suivante :
SELECT *
FROM client
WHERE ville LIKE 'N%'
Avec cette requête, seul les enregistrements suivants seront retournés :
| id | nom | ville |
|---|---|---|
| 2 | Odette | Nice |
| 3 | Vivien | Nantes |
Obtenir les résultats terminent par « e »
Requête :
SELECT *
FROM client
WHERE ville LIKE '%e'
Résultat :
| id | nom | ville |
|---|---|---|
| 2 | Odette | Nice |
| 4 | Etienne | Lille |
SQL IS NULL / IS NOT NULL
Dans le langage SQL, lopérateur IS permet de filtrer les résultats qui contiennent la valeur NULL. Cet opérateur est indispensable car la valeur NULL est une valeur inconnue et ne peut par conséquent pas être filtrée par les opérateurs de comparaison (cf. égal, inférieur, supérieur ou différent).
Pour filtrer les résultats où les champs dune colonne sont à NULL il convient dutiliser la syntaxe suivante :
SELECT *
FROM `table`
WHERE nom_colonne IS NULL
A linverse, pour filtrer les résultats et obtenir uniquement les lignes qui ne sont pas NULL, il convient dutiliser la syntaxe suivante :
SELECT *
FROM `table`
WHERE nom_colonne IS NOT NULL
> A savoir : lopérateur IS retourne en réalité un booléen, cest à dire > une valeur TRUE si la condition est vraie ou FALSE si la condition nest pas > respectée. Cet opérateur est souvent utilisé avec la condition WHERE mais > peut aussi trouver son utilité lorsquune sous-requête est utilisée.
Exemple
Imaginons une application qui possède une table contenant les utilisateurs. Cette table possède 2 colonnes pour associer les adresses de livraison et de facturation à un utilisateur (grâce à une clé étrangère). Si cet utilisateur na pas dadresse de facturation ou de livraison, alors le champ reste à NULL
*
Table « utilisateur » :
| id | nom | date_inscription | fk_adresse_livraison_id | fk_adresse_facturation_id |
|---|---|---|---|---|
| 23 | Grégoire | 2013-02-12 | 12 | 12 |
| 24 | Sarah | 2013-02-17 | NULL | NULL |
| 25 | Anne | 2013-02-21 | 13 | 14 |
| 26 | Frédérique | 2013-03-02 | NULL | NULL |
Exemple 1 : utilisateurs sans adresse de livraison
Il est possible dobtenir la liste des utilisateurs qui ne possèdent pas dadresse de livraison en utilisant la requête SQL suivante :
SELECT *
FROM `utilisateur`
WHERE `fk_adresse_livraison_id` IS NULL
Résultat :
| id | nom | date_inscription | fk_adresse_livraison_id | fk_adresse_facturation_id |
|---|---|---|---|---|
| 24 | Sarah | 2013-02-17 | NULL | NULL |
| 26 | Frédérique | 2013-03-02 | NULL | NULL |
Les enregistrements montrent bien que seuls sont retournés les utilisateurs ayant la valeur NULL pour le champ de ladresse de livraison.
Exemple 2 : utilisateurs avec une adresse de livraison
Pour obtenir uniquement les utilisateurs qui possèdent une adresse de livraison il convient de lancer la requête SQL suivante :
SELECT *
FROM `utilisateur`
WHERE `fk_adresse_livraison_id` IS NOT NULL
Résultat :
| id | nom | date_inscription | fk_adresse_livraison_id | fk_adresse_facturation_id |
|---|---|---|---|---|
| 23 | Grégoire | 2013-02-12 | 12 | 12 |
| 25 | Anne | 2013-02-21 | 13 | 14 |
Les lignes retournées sont exclusivement celles qui nont pas une valeur NULL pour le champ de ladresse de livraison.
SQL GROUP BY
La commande GROUP BY est utilisée en SQL pour grouper plusieurs résultats et utiliser une fonction de totaux sur un groupe de résultat. Sur une table qui contient toutes les ventes dun magasin, il est par exemple possible de regrouper les ventes par clients identiques et dobtenir le coût total des achats pour chaque client.
De façon générale, la commande GROUP BY sutilise de la façon suivante :
SELECT colonne1, fonction(colonne2)
FROM TABLE
GROUP BY colonne1
> A noter : cette commande doit toujours sutiliser après la commande WHERE > et avant la commande HAVING.
Exemple dutilisation
Prenons en considération une table « achat » qui liste les ventes dune boutique
| id | client | tarif | date |
|---|---|---|---|
| 1 | Pierre | 102 | 2012-10-23 |
| 2 | Simon | 47 | 2012-10-27 |
| 3 | Marie | 18 | 2012-11-05 |
| 4 | Marie | 20 | 2012-11-14 |
| 5 | Pierre | 160 | 2012-12-03 |
Ce tableau contient une colonne qui sert didentifiant pour chaque ligne, une autre qui contient le nom du client, le coût de la vente et la date dachat.
Pour obtenir le coût total de chaque client en regroupant les commandes des mêmes clients, il faut utiliser la requête suivante :
SELECT client, SUM(tarif)
FROM achat
GROUP BY client
La fonction SUM() permet dadditionner la valeur de chaque tarif pour un même client. Le résultat sera donc le suivant :
| client | SUM(tarif) |
|---|---|
| Pierre | 262 |
| Simon | 47 |
| Marie | 38 |
La manière simple de comprendre le GROUP BY cest tout simplement dassimiler quil va éviter de présenter plusieurs fois les mêmes lignes. Cest une méthode pour éviter les doublons.
A titre informatif, voici ce quon obtient de la requête sans utiliser GROUP BY.
Requête :
SELECT client, SUM(tarif)
FROM achat
Résultat :
| client | SUM(tarif) |
|---|---|
| Pierre | 262 |
| Simon | 47 |
| Marie | 38 |
| Marie | 38 |
| Pierre | 262 |
Utilisation dautres fonctions de statistiques
Il existe plusieurs fonctions qui peuvent être utilisées pour manipuler plusieurs enregistrements, il sagit des fonctions dagrégation statistiques, les principales sont les suivantes :
- AVG() pour calculer la moyenne dun set de valeur. Permet de connaître le prix du panier moyen pour de chaque client
- COUNT() pour compter le nombre de lignes concernées. Permet de savoir combien dachats a été effectué par chaque client
- MAX() pour récupérer la plus haute valeur. Pour savoir lachat le plus cher.
- MIN() pour récupérer la plus petite valeur. Utile par exemple pour connaître la date du premier achat dun client
- SUM() pour calculer la somme de plusieurs lignes. Permet par exemple de connaître le total de tous les achats dun client
Ces petites fonctions se révèlent rapidement indispensables pour travailler sur des données.
Utilisation de Group By pour concatener des chaines
Il est possible d'utiliser une fonction de concaténation de donnée, par exemple sur SQLServer
-- SQLServer 2005
CREATE TABLE #YourTable ([ID] INT, [Name] CHAR(1), [VALUE] INT)
INSERT INTO #YourTable ([ID],[Name],[VALUE]) VALUES (1,'A',4)
INSERT INTO #YourTable ([ID],[Name],[VALUE]) VALUES (1,'B',8)
INSERT INTO #YourTable ([ID],[Name],[VALUE]) VALUES (2,'C',9)
SELECT
[ID],
STUFF((
SELECT ', ' + [Name] + ':' + CAST([VALUE] AS VARCHAR(MAX))
FROM #YourTable
WHERE (ID = Results.ID)
FOR XML PATH(''),TYPE).value('(./text())[1]','VARCHAR(MAX)')
,1,2,'') AS NameValues
FROM #YourTable Results
GROUP BY ID
DROP TABLE #YourTable
-- SQL Server 2017 or SQL Server Vnext, SQL Azure
SELECT id, STRING_AGG(CONCAT(name, ':', [VALUE]), ', ')
FROM #YourTable
GROUP BY id
Avec une table de détail
DECLARE @spo TABLE ( Id BIGINT, N BIGINT )
DECLARE @nSpo BIGINT = (SELECT MIN(N) FROM @spo)
DECLARE @LENGTH INT = 1000
-- SQLServer 2005
SELECT a.id, STUFF((
SELECT ','+CONVERT(VARCHAR(10), d.Reference) FROM TabDetails d
WHERE d.SPO_Id = a.Id
FOR XML PATH(''),TYPE).value('(./text())[1]','VARCHAR(MAX)'),1,1,''
) AS REFERENCES
FROM @spo a
WHERE a.N >= @nSpo AND a.N < (@nSpo + @LENGTH)
GROUP BY a.Id
-- SQL Server 2017 or SQL Server Vnext, SQL Azure
SELECT a.id, STRING_AGG(d.Reference, ',') AS REFERENCES
FROM @spo a
INNER JOIN TabDetails d ON d.SPO_Id = a.Id
WHERE a.N >= @nSpo AND a.N < (@nSpo + @LENGTH)
GROUP BY a.Id
Il n'est pas possible d'inclure la colonne non agrégée dans la liste de sélection lorsque vous utilisez une clause "group by" dans SQL Server. Pour afficher les colonnes non agrégée tout en conservant le regroupement, voir le paragraphe SQL SELF JOIN.
SQL HAVING
La condition HAVING en SQL est presque similaire à WHERE à la seule différence que HAVING permet de filtrer en utilisant des fonctions telles que SUM(), COUNT(), AVG(), MIN() ou MAX().?
Lutilisation de HAVING sutilise de la manière suivante :
SELECT colonne1, SUM(colonne2)
FROM nom_table
GROUP BY colonne1
HAVING fonction(colonne2) operateur valeur
Cela permet donc de SELECTIONNER les colonnes de la table « nom_table » en GROUPANT les lignes qui ont des valeurs identiques sur la colonne « colonne1 » et que la condition de HAVING soit respectée.
Important : HAVING est très souvent utilisé en même temps que GROUP BY bien que ce ne soit pas obligatoire.
Exemple
Pour utiliser un exemple concret, imaginons une table « achat » qui contient les achats de différents clients avec le coût du panier pour chaque achat.
| id | client | tarif | date_achat |
|---|---|---|---|
| 1 | Pierre | 102 | 2012-10-23 |
| 2 | Simon | 47 | 2012-10-27 |
| 3 | Marie | 18 | 2012-11-05 |
| 4 | Marie | 20 | 2012-11-14 |
| 5 | Pierre | 160 | 2012-12-03 |
Si dans cette table on souhaite récupérer la liste des clients qui ont commandé plus de 40? ??, toutes commandes confondues alors il est possible dutiliser la requête suivante :
SELECT client, SUM(tarif)
FROM achat
GROUP BY client
HAVING SUM(tarif) > 40
Résultat :
| client | SUM(tarif) |
|---|---|
| Pierre | 162 |
| Simon | 47 |
La cliente « Marie » a cumulée 38 dachat (un achat de 18 et un autre de 20) ce qui est inférieur à la limite de 40 imposée par HAVING. En conséquent cette ligne nest pas affichée dans le résultat.
SQL ORDER BY
La commande ORDER BY permet de trier les lignes dans un résultat dune requête SQL. Il est possible de trier les données sur une ou plusieurs colonnes, par ordre ascendant ou descendant.
Une requête où lon souhaite filtrer lordre des résultats utilise la commande ORDER BY de la sorte :
SELECT colonne1, colonne2
FROM TABLE
ORDER BY colonne1
Par défaut les résultats sont classés par ordre ascendant, toutefois il est possible dinverser lordre en utilisant le suffixe DESC après le nom de la colonne. Par ailleurs, il est possible de trier sur plusieurs colonnes en les séparant par une virgule. Une requête plus élaborée ressemblerait alors cela :
``
SELECT colonne1, colonne2, colonne3
FROM TABLE
ORDER BY colonne1 DESC, colonne2 ASC
> **A noter : ** il nest pas obligatoire dutiliser le suffixe « ASC » sachant > que les résultats sont toujours classés par ordre ascendant par défaut. > Toutefois, cest plus pratique pour mieux sy retrouver, surtout si on a > oublié lordre par défaut.
Exemple
Pour lensemble de nos exemples, nous allons prendre une base « utilisateur » de test, qui contient les données suivantes :
| id | nom | prenom | date_inscription | tarif_total |
|---|---|---|---|---|
| 1 | Durand | Maurice | 2012-02-05 | 145 |
| 2 | Dupond | Fabrice | 2012-02-07 | 65 |
| 3 | Durand | Fabienne | 2012-02-13 | 90 |
| 4 | Dubois | Chloé | 2012-02-16 | 98 |
| 5 | Dubois | Simon | 2012-02-23 | 27 |
Pour récupérer la liste de ces utilisateurs par ordre alphabétique du nom de famille, il est possible dutiliser la requête suivante :
SELECT *
FROM utilisateur
ORDER BY nom
Résultat :
| id | nom | prenom | date_inscription | tarif_total |
|---|---|---|---|---|
| 4 | Dubois | Chloé | 2012-02-16 | 98 |
| 5 | Dubois | Simon | 2012-02-23 | 27 |
| 2 | Dupond | Fabrice | 2012-02-07 | 65 |
| 1 | Durand | Maurice | 2012-02-05 | 145 |
| 3 | Durand | Fabienne | 2012-02-13 | 90 |
En utilisant deux méthodes de tri, il est possible de retourner les utilisateurs par ordre alphabétique ET pour ceux qui ont le même nom de famille, les trier par ordre décroissant de date dinscription. La requête serait alors la suivante :
SELECT *
FROM utilisateur
ORDER BY nom, date_inscription DESC
Résultat :
| id | nom | prenom | date_inscription | tarif_total |
|---|---|---|---|---|
| 5 | Dubois | Simon | 2012-02-23 | 27 |
| 4 | Dubois | Chloé | 2012-02-16 | 98 |
| 2 | Dupond | Fabrice | 2012-02-07 | 65 |
| 3 | Durand | Fabienne | 2012-02-13 | 90 |
| 1 | Durand | Maurice | 2012-02-05 | 145 |
SQL LIMIT
La clause LIMIT est à utiliser dans une requête SQL pour spécifier le nombre maximum de résultats que lon souhaite obtenir. Cette clause est souvent associée à un OFFSET, cest-à-dire effectuer un décalage sur le jeu de résultat. Ces 2 clauses permettent par exemple deffectuer des systèmes de pagination (exemple : récupérer les 10 articles de la page 4).
*
ATTENTION : selon le système de gestion de base de données, la syntaxe ne sera pas pareille. Ce tutoriel va donc présenter la syntaxe pour MySQL et pour PostgreSQL.
La syntaxe commune aux principaux systèmes de gestion de bases de données est :
SELECT *
FROM TABLE
LIMIT 10
Cette requête permet de récupérer seulement les 10 premiers résultats dune table. Bien entendu, si la table contient moins de 10 résultats, alors la requête retournera toutes les lignes.
**Bon à savoir : ** la bonne pratique lorsque lon utilise LIMIT consiste à utiliser également la clause ORDER BY pour sassurer que quoi quil en soit ce sont toujours les bonnes données qui sont présentées. En effet, si le système de tri est non spécifié, alors il est en principe inconnu et les résultats peuvent être imprévisible.
Limit et Offset avec PostgreSQL
Loffset est une méthode simple de décaler les lignes à obtenir. La syntaxe pour utiliser une limite et un offset est la suivante :
SELECT *
FROM TABLE
LIMIT 10 OFFSET 5
Cette requête permet de récupérer les résultats 6 à 15 (car lOFFSET commence toujours à 0). A titre dexemple, pour récupérer les résultats 16 à 25 il faudrait donc utiliser: LIMIT 10 OFFSET 15
A noter : Utiliser OFFSET 0 revient au même que domettre lOFFSET.
Limit et Offset avec MySQL
La syntaxe avec MySQL est légèrement différente :
SELECT *
FROM TABLE
LIMIT 5, 10;
Cette requête retourne les enregistrements 6 à 15 dune table. Le premier nombre est lOFFSET tandis que le suivant est la limite.
**Bon à savoir : ** pour une bonne compatibilité, MySQL accepte également la syntaxe LIMIT nombre OFFSET nombre. En conséquent, dans la conception dune application utilisant MySQL il est préférable dutiliser cette syntaxe car cest potentiellement plus facile de migrer vers un autre système de gestion de base de données sans avoir à ré-écrire toutes les requêtes.
Performance
Ce dernier chapitre est destiné à un public averti. Il nest pas nécessaire de le comprendre entièrement, mais simplement davoir compris les grandes lignes.
Certains développeurs pensent à tort que lutilisation de LIMIT permet de réduire le temps dexécution dune requête. Or, le temps dexécution est sensiblement le même car la requête va permettre de récupérer toutes les lignes (donc temps dexécution identique) PUIS seulement les résultats définis par LIMIT et OFFSET seront retournés. Au mieux, utiliser LIMIT permet de réduire le temps daffichage car il y a moins de lignes à afficher.
SQL CASE
Dans le langage SQL, la commande « CASE WHEN » permet dutiliser des conditions de type « si / sinon » (cf. if / else) similaire à un langage de programmation pour retourner un résultat disponible entre plusieurs possibilités. Le CASE peut être utilisé dans nimporte quelle instruction ou clause, telle que SELECT, UPDATE, DELETE, WHERE, ORDER BY ou HAVING.
Lutilisation du CASE est possible de 2 manières différentes :
- Comparer une colonne à un set de résultat possible
- élaborer une série de conditions booléennes pour déterminer un résultat
Comparer une colonne à un set de résultat
Voici la syntaxe nécessaire pour comparer une colonne à un set denregistrement:
CASE a
WHEN 1 THEN 'un'
WHEN 2 THEN 'deux'
WHEN 3 THEN 'trois'
ELSE 'autre'
END
Dans cet exemple les valeurs contenues dans la colonne « a » sont comparées à 1, 2 ou 3. Si la condition est vraie, alors la valeur située après le THEN sera retournée.
> A noter : la condition ELSE est facultative et sert de ramasse-miettes. > Si les conditions précédentes ne sont pas respectées alors ce sera la valeur > du ELSE qui sera retournée par défaut.
élaborer une série de conditions booléennes pour déterminer un résultat
Il est possible détablir des conditions plus complexes pour récupérer un résultat ou un autre. Cela seffectue en utilisant la syntaxe suivante :
CASE
WHEN a=b THEN 'A égal à B'
WHEN a>b THEN 'A supérieur à B'
ELSE 'A inférieur à B'
END
Dans cet exemple les colonnes « a », « b » et « c » peuvent contenir des valeurs numériques. Lorsquelles sont respectées, les conditions booléennes permettent de rentrer dans lune ou lautre des conditions.
Il est possible de reproduire le premier exemple présenté sur cette page en utilisant la syntaxe suivante :
CASE
WHEN a=1 THEN 'un'
WHEN a=2 THEN 'deux'
WHEN a=3 THEN 'trois'
ELSE 'autre'
END
Exemples
Pour présenter le CASE dans le langage SQL il est possible dimaginer une base de données utilisées par un site de vente en ligne. Dans cette base il y a une table contenant les achats, cette table contient le nom des produits, le prix unitaire, la quantité achetée et une colonne consacrée à une marge fictive sur certains produits.
Table « achat » :
| id | nom | surcharge | prix_unitaire | quantite |
|---|---|---|---|---|
| 1 | Produit A | 1.3 | 6 | 3 |
| 2 | Produit B | 1.5 | 8 | 2 |
| 3 | Produit C | 0.75 | 7 | 4 |
| 4 | Produit D | 1 | 15 | 2 |
Afficher un message selon une condition
Il est possible deffectuer une requête qui va afficher un message personnalisé en fonction de la valeur de la marge. Le message sera différent selon que la marge sera égale à 1, supérieure à 1 ou inférieure à 1. La requête peut se présenter de la façon suivante :
`
SELECT id, nom, marge_pourcentage, prix_unitaire, quantite,
CASE
WHEN marge_pourcentage=1 THEN 'Prix ordinaire'
WHEN marge_pourcentage>1 THEN 'Prix supérieur à la normale'
ELSE 'Prix inférieur à la normale'
END
FROM `achat`
Résultat :
| id | nom | surcharge | prix_unitaire | quantite | CASE |
|---|---|---|---|---|---|
| 1 | Produit A | 1.3 | 6 | 3 | Prix supérieur à la normale |
| 2 | Produit B | 1.5 | 8 | 2 | Prix supérieur à la normale |
| 3 | Produit C | 0.75 | 7 | 4 | Prix inférieur à la normale |
| 4 | Produit D | 1 | 15 | 2 | Prix ordinaire |
Ce résultat montre quil est possible dafficher facilement des messages personnalisés selon des conditions simples.
Afficher un prix unitaire différent selon une condition
Avec un CASE il est aussi possible dutiliser des requêtes plus élaborées. Imaginons maintenant que nous souhaitions multiplier le prix unitaire par 2 si la marge est supérieure à 1, la diviser par 2 si la marge est inférieure à 1 et laisser le prix unitaire tel quel si la marge est égale à 1. Cest possible grâce à la requête SQL :
``
SELECT id, nom, marge_pourcentage, prix_unitaire, quantite,
CASE
WHEN marge_pourcentage=1 THEN prix_unitaire
WHEN marge_pourcentage>1 THEN prix_unitaire*2
ELSE prix_unitaire/2
END
FROM `achat`
Résultat :
| id | nom | surcharge | prix_unitaire | quantite | CASE |
|---|---|---|---|---|---|
| 1 | Produit A | 1.3 | 6 | 3 | 12 |
| 2 | Produit B | 1.5 | 8 | 2 | 16 |
| 3 | Produit C | 0.75 | 7 | 4 | 3.5 |
| 4 | Produit D | 1 | 15 | 2 | 15 |
Comparer un champ à une valeur donnée
Imaginons maintenant que lapplication propose des réductions selon le nombre de produits achetés :
- 1 produit acheté permet dobtenir une réduction de -5% pour le prochain achat
- 2 produits achetés permettent dobtenir une réduction de -6% pour le prochain achat
- 3 produits achetés permettent dobtenir une réduction de -8% pour le prochain achat
- Pour plus de produits achetés il y a un réduction de -10% pour le prochain achat
Pour effectuer une telle procédure, il est possible de comparer la colonne « quantite » aux différentes valeurs spécifiées et dafficher un message personnalisé en fonction du résultat. Cela peut être réalisé avec cette requête SQL :
SELECT id, nom, marge_pourcentage, prix_unitaire, quantite,
CASE quantite
WHEN 0 THEN 'Erreur'
WHEN 1 THEN 'Offre de -5% pour le prochain achat'
WHEN 2 THEN 'Offre de -6% pour le prochain achat'
WHEN 3 THEN 'Offre de -8% pour le prochain achat'
ELSE 'Offre de -10% pour le prochain achat'
END
FROM `achat`
Résultat :
| id | nom | surcharge | prix_unitaire | quantite | CASE |
|---|---|---|---|---|---|
| 1 | Produit A | 1.3 | 6 | 3 | Offre de -8% pour le prochain achat |
| 2 | Produit B | 1.5 | 8 | 2 | Offre de -6% pour le prochain achat |
| 3 | Produit C | 0.75 | 7 | 4 | Offre de -10% pour le prochain achat |
| 4 | Produit D | 1 | 15 | 2 | Offre de -6% pour le prochain achat |
Astuce : la condition ELSE peut parfois être utilisée pour gérer les erreurs.
UPDATE avec CASE
Comme cela a été expliqué au début, il est aussi possible dutiliser le CASE à la suite de la commande SET dun UPDATE pour mettre à jour une colonne avec une donnée spécifique selon une règle. Imaginons par exemple que lon souhaite offrir un produit pour tous les achats qui ont une surcharge inférieure à 1 et que lon souhaite retirer un produit pour tous les achats avec une surcharge supérieure à 1. Il est possible dutiliser la requête SQL suivante :
UPDATE `achat`
SET `quantite` = (
CASE
WHEN `surcharge` < 1 THEN `quantite` + 1
WHEN `surcharge` > 1 THEN `quantite` - 1
ELSE quantite
END
)
SQL UNION
La commande UNION de SQL permet de mettre bout-à-bout les résultats de plusieurs requêtes utilisant elles-mêmes la commande SELECT. Cest donc une commande qui permet de concaténer les résultats de 2 requêtes ou plus. Pour lutiliser il est nécessaire que chacune des requêtes à concaténer retourne le même nombre de colonnes, avec les mêmes types de données et dans le même ordre.
A savoir : par défaut, les enregistrements exactement identiques ne seront pas répétés dans les résultats. Pour effectuer une union dans laquelle même les lignes dupliquées sont affichées il faut plutôt utiliser la commande UNION ALL.
La syntaxe pour unir les résultats de 2 tableaux sans afficher les doublons est la suivante :
SELECT * FROM table1
UNION
SELECT * FROM table2
Schéma explicatif
Lunion de 2 ensembles A et B est un concept qui consiste à obtenir tous les éléments qui correspondent à la fois à lensemble A ou à lensemble B. Cela se résume très simplement par un petit schéma où la zone en bleu correspond à la zone que lon souhaite obtenir (dans notre cas : tous les éléments).
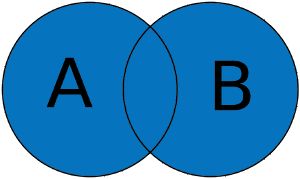
Union de 2 ensembles
Exemple
Imaginons une entreprise qui possède plusieurs magasins et dans chacun de ces magasins il y a une table qui liste les clients. La table du magasin n°1 sappelle « magasin1_client » et contient les données suivantes :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Léon | Dupuis | Paris | 1983-03-06 | 135 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Sophie | Dupond | Marseille | 1986-02-22 | 27 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
La table du magasin n°2 sappelle « magasin2_client » et contient ces données :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Marion | Leroy | Lyon | 1982-10-27 | 285 |
| Paul | Moreau | Lyon | 1976-04-19 | 133 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
Sachant que certains clients sont présents dans les 2 tables, pour éviter de retourner plusieurs fois les mêmes enregistrements, il convient dutiliser la requête UNION. La requête SQL est alors la suivante :
SELECT * FROM magasin1_client
UNION
SELECT * FROM magasin2_client
Résultat :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Léon | Dupuis | Paris | 1983-03-06 | 135 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Sophie | Dupond | Marseille | 1986-02-22 | 27 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
| Marion | Leroy | Lyon | 1982-10-27 | 285 |
| Paul | Moreau | Lyon | 1976-04-19 | 133 |
Le résultat de cette requête montre bien que les enregistrements des 2 requêtes sont mis bout-à-bout mais sans inclure plusieurs fois les mêmes lignes.
SQL UNION ALL
La commande UNION ALL de SQL est très similaire à la commande UNION. Elle permet de concaténer les enregistrements de plusieurs requêtes, à la seule différence que cette commande permet dinclure tous les enregistrements, même les doublons. Ainsi, si un même enregistrement est présent normalement dans les résultats des 2 requêtes concaténées, alors lunion des 2 requêtes avec UNION ALL retournera 2 fois ce même résultat.
**A savoir : ** tout comme la commande UNION, il convient que les 2 requêtes retournent exactement le même nombre de colonnes, avec les mêmes types de données et dans le même ordre.
La syntaxe de la requête SQL pour unir les résultats des 2 tables est :
SELECT * FROM table1
UNION ALL
SELECT * FROM table2
Exemple
Imaginons une entreprise qui possède des bases de données dans chacun de ses magasins. Sur ces bases de données il y a une table de la liste des clients avec quelques informations et le total des achats dans lentreprise.
La table « magasin1_client » correspond au premier magasin :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Léon | Dupuis | Paris | 1983-03-06 | 135 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Sophie | Dupond | Marseille | 1986-02-22 | 27 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
La table « magasin2_client » correspond au deuxième magasin :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Marion | Leroy | Lyon | 1982-10-27 | 285 |
| Paul | Moreau | Lyon | 1976-04-19 | 133 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
Pour concaténer les tous les enregistrements de ces tables, il est possible deffectuer une seule requête utilisant la commande UNION ALL, comme lexemple ci-dessous :
SELECT * FROM magasin1_client
UNION ALL
SELECT * FROM magasin2_client
Résultat :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Léon | Dupuis | Paris | 1983-03-06 | 135 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Sophie | Dupond | Marseille | 1986-02-22 | 27 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
| Marion | Leroy | Lyon | 1982-10-27 | 285 |
| Paul | Moreau | Lyon | 1976-04-19 | 133 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
Le résultat de cette requête montre quil y a autant denregistrements que dans les 2 tables réunies. A savoir, il y a quelques clients qui étaient présents dans les 2 tables dorigines, par conséquent ils sont présents 2 fois dans le résultat de cette requête SQL.
SQL INTERSECT
La commande SQL INTERSECT permet dobtenir lintersection des résultats de deux requêtes. Cette commande permet donc de récupérer les enregistrements communs à 2 requêtes. Cela peut savérer utile lorsquil faut trouver sil y a des données similaires sur 2 tables distinctes.
> **A savoir : ** pour lutiliser convenablement il faut que les 2 requêtes > retournent le même nombre de colonnes, avec les mêmes types et dans le même ordre.
La syntaxe à adopter pour utiliser cette commande est la suivante :
SELECT * FROM table1
INTERSECT
SELECT * FROM table2
Dans cet exemple, il faut que les 2 tables soient similaires (mêmes colonnes, mêmes types et même ordre). Le résultat correspondra aux enregistrements qui existent dans table1 et dans table2.
Schéma explicatif
Lintersection de 2 ensembles A et B correspond aux éléments qui sont présent dans A et dans B, et seulement ceux-là. Cela peut être représenté par un schéma explicatif simple ou lintersection de A et B correspond à la zone en bleu.
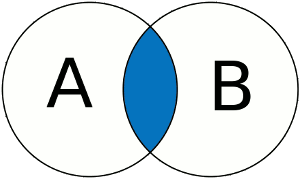
? Intersection de 2 ensembles
Exemple
Prenons lexemple de 2 magasins qui appartiennent au même groupe. Chaque magasin possède sa table de clients.
La table du magasin n°1 est « magasin1_client » :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Léon | Dupuis | Paris | 1983-03-06 | 135 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Sophie | Dupond | Marseille | 1986-02-22 | 27 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
La table du magasin n°2 est « magasin2_client » :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Marion | Leroy | Lyon | 1982-10-27 | 285 |
| Paul | Moreau | Lyon | 1976-04-19 | 133 |
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
Pour obtenir la liste des clients qui sont présents de façon identiques dans ces 2 tables, il est possible dutiliser la commande INTERSECT de la façon suivante :
SELECT * FROM magasin1_client
INTERSECT
SELECT * FROM magasin2_client
Résultat :
| prenom | nom | ville | date_naissance | total_achat |
|---|---|---|---|---|
| Marie | Bernard | Paris | 1993-07-03 | 75 |
| Marcel | Martin | Paris | 1976-11-24 | 39 |
Le résultat présente 2 enregistrements, il sagit des clients qui sont à la fois dans la table « magasin1_client » et dans la table « magasin2_client ». Sur certains systèmes une telle requête permet de déceler des erreurs et denregistrer seulement à un seul endroit la même information.
SQL EXCEPT / MINUS
Dans le langage SQL la commande EXCEPT sutilise entre 2 instructions pour récupérer les enregistrements de la première instruction sans inclure les résultats de la seconde requête. Si un même enregistrement devait être présent dans les résultats des 2 syntaxes, ils ne seront pas présent dans le résultat final.
> **A savoir : ** cette commande sappelle différemment selon les Systèmes de > Gestion de Base de Données (SGBD) :
- EXCEPT : PostgreSQL et SQLServer
- MINUS : MySQL et Oracle
Dès lors, il faut remplacer tout le reste de ce cours par MINUS pour les SGBD correspondants.
La syntaxe dune requête SQL est toute simple :
SELECT * FROM table1
EXCEPT
SELECT * FROM table2
Cette requête permet de lister les résultats du table 1 sans inclure les enregistrements de la table 1 qui sont aussi dans la table 2.
> **Attention : ** les colonnes de la première requête doivent être similaires > entre la première et la deuxième requête (même nombre, même type et même > ordre).
Schéma explicatif
Cette commande permet de récupérer les éléments de lensemble A sans prendre en compte les éléments de A qui sont aussi présent dans lensemble B. Dans le schéma ci-dessous seule la zone bleu sera retournée grâce à la commande EXCEPT (ou MINUS).
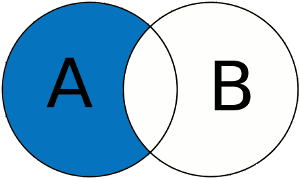
? Sélection dun ensemble avec exception
Exemple
Imaginons un système informatique dune entreprise. Ce système contient 2 tables contenant des listes de clients :
Une table « clients_inscrits » qui contient les prénoms, noms et date dinscription de clients
Une table « clients_refus_email » qui contient les informations des clients qui ne souhaitent pas être contactés par email
Cet exemple aura pour objectif de sélectionner les utilisateurs pour envoyer un email dinformation. Les utilisateurs de la deuxième table ne devront pas apparaître dans les résultats.
Table « clients_inscrits » :
| id | prenom | nom | date_inscription |
|---|---|---|---|
| 1 | Lionel | Martineau | 2012-11-14 |
| 2 | Paul | Cornu | 2012-12-15 |
| 3 | Sarah | Schmitt | 2012-12-17 |
| 4 | Sabine | Lenoir | 2012-12-18 |
Table « clients_refus_email » :
| id | prenom | nom | date_inscription |
|---|---|---|---|
| 1 | Paul | Cornu | 2013-01-27 |
| 2 | Manuel | Guillot | 2013-01-27 |
| 3 | Sabine | Lenoir | 2013-01-29 |
| 4 | Natalie | Petitjean | 2013-02-03 |
Pour pouvoir sélectionner uniquement le prénom et le nom des utilisateurs qui acceptent de recevoir des emails informatifs. La requête SQL à utiliser est la suivante :
SELECT prenom, nom FROM clients_inscrits
EXCEPT
SELECT prenom, nom FROM clients_refus_email
Résultats :
| prenom | nom |
|---|---|
| Lionel | Martineau |
| Sarah | Schmitt |
Ce tableau de résultats montre bien les utilisateurs qui sont dans inscrits et qui ne sont pas présents dans le deuxième tableau. Par ailleurs, les résultats du deuxième tableau ne sont pas présents sur ce résultat final.
SQL INSERT INTO
Linsertion de données dans une table seffectue à laide de la commande INSERT INTO. Cette commande permet au choix dinclure une seule ligne à la base existante ou plusieurs lignes dun coup.
Insertion dune ligne à la fois
Pour insérer des données dans une base, il y a 2 syntaxes principales :
- Insérer une ligne en indiquant les informations pour chaque colonne existante (en respectant lordre)
- Insérer une ligne en spécifiant les colonnes que vous souhaiter compléter. Il est possible dinsérer une ligne en renseignant seulement une partie des colonnes
Insérer une ligne en spécifiant toutes les colonnes
La syntaxe pour remplir une ligne avec cette méthode est la suivante :
INSERT INTO TABLE
VALUES ('valeur 1', 'valeur 2', ...)
Cette syntaxe possède les avantages et inconvénients suivants :
- Obligation de remplir toutes les données, en respectant lordre des colonnes
- Il ny a pas le nom de colonne, donc les fautes de frappe sont limitées. Par ailleurs, les colonnes peuvent être renommées sans avoir à changer la requête
- Lordre des colonnes doit rester identique sinon certaines valeurs prennent le risque dêtre complétées dans la mauvaise colonne.
Insérer une ligne en spécifiant seulement les colonnes souhaitées
Cette deuxième solution est très similaire, excepté quil faut indiquer le nom des colonnes avant « VALUES ». La syntaxe est la suivante :
INSERT INTO TABLE
(nom_colonne_1, nom_colonne_2, ...)
VALUES ('valeur 1', 'valeur 2', ...)
> A noter : il est possible de ne pas renseigner toutes les colonnes. De > plus, lordre des colonnes nest pas important.
Insertion de plusieurs lignes à la fois
Il est possible dajouter plusieurs lignes à un tableau avec une seule requête. Pour ce faire, il convient dutiliser la syntaxe suivante :
INSERT INTO client (prenom, nom, ville, age)
VALUES
('Rébecca', 'Armand', 'Saint-Didier-des-Bois', 24),
('Aimée', 'Hebert', 'Marigny-le-Châtel', 36),
('Marielle', 'Ribeiro', 'Maillères', 27),
('Hilaire', 'Savary', 'Conie-Molitard', 58);
**A noter : ** lorsque le champ à remplir est de type VARCHAR ou TEXT il faut indiquer le texte entre guillemet simple. En revanche, lorsque la colonne est un numérique tel que INT ou BIGINT il ny a pas besoin dutiliser de guillemet, il suffit juste dindiquer le nombre.
Un tel exemple sur une table vide va créer le tableau suivant :
| id | prenom | nom | ville | age |
|---|---|---|---|---|
| 1 | Rébecca | Armand | Saint-Didier-des-Bois | 24 |
| 2 | Aimée | Hebert | Marigny-le-Châtel | 36 |
| 3 | Marielle | Ribeiro | Maillères | 27 |
| 4 | Hilaire | Savary | Conie-Molitard | 58 |
Insertion avec les index
SET IDENTITY_INSERT nomTable ON / OFF
Active, désactive l'insertion automatique de colonne auto incrémentées (identity) dans la table spécifiée.
Exemple : insertion de lignes dont la clef est spécifiée dans une table données pourvue d'un auto incrément :
CREATE TABLE T_CLIENT
(CLI_ID INTEGER IDENTITY NOT NULL PRIMARY KEY,
CLI_NOM VARCHAR(32))
SET IDENTITY_INSERT T_CLIENT ON
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (325, 'DUPONT')
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (987, 'MARTIN')
SET IDENTITY_INSERT T_CLIENT OFF
INSERT INTO T_CLIENT (CLI_ID, CLI_NOM) VALUES (512, 'LEVY')
=> Serveur: Msg 544, Niveau 16, État 1, Ligne 1
Impossible d'insérer une valeur explicite dans la colonne identité de la
table 'T_CLIENT' quand IDENTITY_INSERT
est défini à OFF.
SQL ON DUPLICATE KEY UPDATE
Linstruction ON DUPLICATE KEY UPDATE est une fonctionnalité de MySQL qui permet de mettre à jour des données lorsquun enregistrement existe déjà dans une table. Cela permet de navoir quune seule requête SQL pour effectuer selon la convenance un INSERT ou un UPDATE. Cette commande seffectue au sein de la requête INSERT INTO avec la syntaxe suivante :
INSERT INTO TABLE (a, b,c)
VALUES (1, 20, 68)
ON DUPLICATE KEY UPDATE a=a+1
A noter : cette requête se traduit comme suit :
- insérer les données a, b et c avec les données respectives de 1, 20 et 68
- Si la clé primaire existe déjà pour ces valeurs alors seulement faire une mise à jour de a = a+1
Exemple avec la commande WHERE
Grâce à la commande « ON DUPLICATE KEY » Il est possible denregistrer la date à laquelle la données est insérée pour la première fois et la date de dernière mise à jour, comme le montre la commande ci-dessous :
INSERT INTO TABLE (a, b,c, date_insert)
VALUES (1, 20, 1, NOW())
ON DUPLICATE KEY UPDATE date_update=NOW
WHERE c=1
A noter : cette requête se traduit comme suit :
- insérer les données a, b, c et date_insert, avec les données respectives de 1, 20, 1 ainsi que la date et lheure actuelle
- Si la clé primaire existe déjà pour ces valeurs alors mettre à jour la date et lheure du champ « date_update »
- Effectuer la mise à jour uniquement sur les champs où c = 1
Exemple
Imaginons une application qui laisse les utilisateurs voter pour les produits quils préfèrent. Le système de vote est très simple et est basé sur des +1. La table des votes contient le nombre de votes par produit avec la date du premier vote et la date du dernier vote.
Table vote :
| id | produit_id | vote_count | vote_first_date | vote_last_date |
|---|---|---|---|---|
| 1 | 46 | 2 | 2012-04-25 17:45:24 | 2013-02-16 09:47:02 |
| 2 | 39 | 4 | 2012-04-28 16:54:44 | 2013-02-14 21:04:35 |
| 3 | 49 | 1 | 2012-04-25 19:11:09 | 2013-01-06 20:32:57 |
Pour nutiliser quune seule ligne qui permet dajouter des votes dans cette table, sans se préoccuper de savoir sil faut faire un INSERT ou un UPDATE, il est possible dutiliser la requête SQL suivante :
INSERT INTO vote (produit_id, vote_count, vote_first_date, vote_last_date)
VALUES (50, 1, NOW(), NOW())
ON DUPLICATE KEY UPDATE vote_count = vote_count+1, vote_last_date = NOW()
Dans cette requête la date et lheure sont générées automatiquement avec la fonction NOW().
Résultat après la première exécution de la requête :
| id | produit_id | vote_count | vote_first_date | vote_last_date |
|---|---|---|---|---|
| 1 | 46 | 2 | 2012-04-25 17:45:24 | 2013-02-16 09:47:02 |
| 2 | 39 | 4 | 2012-04-28 16:54:44 | 2013-02-14 21:04:35 |
| 3 | 49 | 1 | 2012-04-25 19:11:09 | 2013-01-06 20:32:57 |
| 4 | 55 | 1 | 2013-04-02 15:06:34 | 2013-04-02 15:06:34 |
Ce résultat montre bien lajout dune ligne en fin de table, donc la requête a été utilisé sous la forme dun INSERT. Après une deuxième exécution de cette même requête le lendemain, les données seront celles-ci:
| id | produit_id | vote_count | vote_first_date | vote_last_date |
|---|---|---|---|---|
| 1 | 46 | 2 | 2012-04-25 17:45:24 | 2013-02-16 09:47:02 |
| 2 | 39 | 4 | 2012-04-28 16:54:44 | 2013-02-14 21:04:35 |
| 3 | 49 | 1 | 2012-04-25 19:11:09 | 2013-01-06 20:32:57 |
| 4 | 55 | 2 | 2013-04-02 15:06:34 | 2013-04-03 08:14:57 |
Ces résultats montrent bien quil y a eu un vote supplémentaire et que la date du dernier vote a été mis à jour.
Insérer une ligne ou ne rien faire
Dans certains cas il est intéressant dutiliser un INSERT mais de ne rien faire si la commande a déjà été insérée précédemment. Malheureusement, si la clé primaire existe déjà la requête retournera une erreur. Et sil ny a rien à mettre à jour, la commande ON DUPLICATE KEY UPDATE (ODKU) ne semble pas convenir. Toutefois il y a une astuce qui consiste à utiliser une requête de ce type :
INSERT INTO TABLE (a, b,c)
VALUES (1, 45, 6)
ON DUPLICATE KEY UPDATE id = id
Cette requête insère les données et ne produit aucune erreur si lenregistrement existait déjà dans la table.
> **A savoir : ** théoriquement il aurait été possible dutiliser INSERT IGNORE > mais malheureusement cela empêche de retourner des erreurs telles que des > erreurs de conversions de données.
Compatibilité
Pour le moment cette fonctionnalité nest possible quavec MySQL depuis la version 4.1 (date de 2003). Les autres Systèmes de Gestion de Bases de Données (SGBD) nintègrent pas cette fonctionnalité. Pour simuler cette fonctionnalité il y a quelques alternatives :
- **PostgreSQL : ** il y a une astuce en utilisant une fonction. Lastuce est expliquée dans la documentation officielle : fonction INSERT/UPDATE.
**Oracle : ** il est possible dutiliser la commande MERGE pour effectuer la même chose.
SQL Server : il est possible dutiliser une procédure.
SQL UPDATE
La commande UPDATE permet deffectuer des modifications sur des lignes existantes. Très souvent cette commande est utilisée avec WHERE pour spécifier sur quelles lignes doivent porter la ou les modifications.
La syntaxe basique dune requête utilisant UPDATE est la suivante :
UPDATE TABLE
SET nom_colonne_1 = 'nouvelle valeur'
WHERE condition
Cette syntaxe permet dattribuer une nouvelle valeur à la colonne nom_colonne_1 pour les lignes qui respectent la condition stipulée avec WHERE. Il est aussi possible dattribuer la même valeur à la colonne nom_colonne_1 pour toutes les lignes dune table si la condition WHERE nétait pas utilisée.
A noter, pour spécifier en une seule fois plusieurs modifications, il faut séparer les attributions de valeurs par des virgules. Ainsi la syntaxe deviendrait la suivante :
UPDATE TABLE
SET colonne_1 = 'valeur 1', colonne_2 = 'valeur 2', colonne_3 = 'valeur 3'
WHERE condition
Exemple
| id | nom | rue | ville | code_postal | pays |
|---|---|---|---|---|---|
| 1 | Chantal | 12 Av du Petit Trianon | Puteaux | 92800 | France |
| 2 | Pierre | 18 Rue de l'Allier | Ponthion | 51300 | France |
| 3 | Romain | 3 Chemin du Chiron | Trévérien | 35190 | France |
Imaginons une table « client » qui présente les coordonnées de clients.
Pour modifier ladresse du client Pierre, il est possible dutiliser la requête suivante :
UPDATE client
SET rue = '49 Rue Ameline',
ville = 'Saint-Eustache-la-Forêt',
code_postal = '76210'
WHERE id = 2
Résultat :
| id | nom | rue | ville | code_postal | pays |
|---|---|---|---|---|---|
| 1 | Chantal | 12 Av du Petit Trianon | Puteaux | 92800 | France |
| 2 | Pierre | 49 Rue Ameline | Saint-Eustache-la-Forêt | 76210 | France |
| 3 | Romain | 3 Chemin du Chiron | Trévérien | 35190 | France |
SQL DELETE
La commande DELETE en SQL permet de supprimer des lignes dans une table. En utilisant cette commande associée à WHERE il est possible de sélectionner les lignes concernées qui seront supprimées.
**Attention : ** Avant dessayer de supprimer des lignes, il est recommandé deffectuer une sauvegarde de la base de données, ou tout du moins de la table concernée par la suppression. Ainsi, sil y a une mauvaise manipulation il est toujours possible de restaurer les données.
La syntaxe pour supprimer des lignes est la suivante :
DELETE FROM TABLE
WHERE condition
Attention : sil ny a pas de condition WHERE alors toutes les lignes seront supprimées et la table sera alors vide. La commande DELETE peut générer l'écriture de beaucoup de log. Si le but est de vider la table préférez la commande TRUNCATE qui ne générera pas de log.
Exemple
Imaginons une table « utilisateur » qui contient des informations sur les utilisateurs dune application.
| id | nom | prenom | date_inscription |
|---|---|---|---|
| 1 | Bazin | Daniel | 2012-02-13 |
| 2 | Favre | Constantin | 2012-04-03 |
| 3 | Clerc | Guillaume | 2012-04-12 |
| 4 | Ricard | Rosemonde | 2012-06-24 |
| 5 | Martin | Natalie | 2012-07-02 |
Si lon souhaite supprimer les utilisateurs qui se sont inscrit avant le « 10/04/2012 », il va falloir effectuer la requête suivante :
DELETE FROM utilisateur
WHERE date_inscription < '2012-04-10'
La requête permettra alors de supprimer les utilisateurs « Daniel » et « Constantin ». La table contiendra alors les données suivantes :
| id | nom | prenom | date_inscription |
|---|---|---|---|
| 3 | Clerc | Guillaume | 2012-04-12 |
| 4 | Ricard | Rosemonde | 2012-06-24 |
| 5 | Martin | Natalie | 2012-07-02 |
Il ne faut pas oublier quil est possible dutiliser dautres conditions pour sélectionner les lignes à supprimer.
SQL MERGE
Dans le langage SQL, la commande MERGE permet dinsérer ou de mettre à jour des données dans une table. Cette commande permet déviter deffectuer plusieurs requêtes pour savoir si une donnée est déjà dans la base de données et ainsi adapter lutilisation dune requête pour ajouter ou une autre pour modifier la donnée existante. Cette commande peut aussi sappeler « upsert ».
Attention : bien que linstruction ait été ajoutée dans le standard SQL:2003 les différentes SGBD nutilisent pas toutes les mêmes méthodes pour effectuer un upsert.
La syntaxe standard pour effectuer un merge consiste à utiliser une requête SQL semblable à celle ci-dessous :
MERGE INTO table1
USING table_reference
ON (conditions)
WHEN MATCHED THEN
UPDATE SET table1.colonne1 = valeur1, table1.colonne2 = valeur2
DELETE WHERE conditions2
WHEN NOT MATCHED THEN
INSERT (colonnes1, colonne3)
VALUES (valeur1, valeur3)
Voici les explications détaillées de cette requête :
- MERGE INTO permet de sélectionner la table à modifier
- USING et ON permet de lister les données sources et la condition de correspondance
- WHEN MATCHED permet de définir la condition de mise à jour lorsque la condition est vérifiée
- WHEN NOT MATCHED permet de définir la condition dinsertion lorsque la condition nest pas vérifiée
Compatibilité
Les systèmes de gestion de bases de données peuvent implémenter cette fonctionnalité soit de façon standard, en utilisant une commande synonyme ou en utilisant une syntaxe non standard.
- Syntaxe standard : SQL Server, Oracle, DB2, Teradata et EXASOL
- Utilisation du terme UPSERT : Microsoft SQL Azure et MongoDB
- Utilisation non standard : MySQL, SQLite, Firebird, IBM DB2 et Microsoft SQL
1.4. SQL Sous-requête
Dans le langage SQL une sous-requête (aussi appelé « requête imbriquée » ou « requête en cascade ») consiste à exécuter une requête à lintérieur dune autre requête. Une requête imbriquée est souvent utilisée au sein dune clause WHERE ou de HAVING pour remplacer une ou plusieurs constantes.
Il y a plusieurs façons dutiliser les sous-requêtes. De cette façon il y a plusieurs syntaxes envisageables pour utiliser des requêtes dans des requêtes.
Requête imbriquée qui retourne un seul résultat
Lexemple ci-dessous est une exemple typique dune sous-requête qui retourne un seul résultat à la requête principale.
SELECT *
FROM `table`
WHERE `nom_colonne` = (
SELECT `valeur`
FROM `table2`
LIMIT 1
)
Cet exemple montre une requête interne (celle sur « table2? ) qui renvoie une seule valeur. La requête externe quant à elle, va chercher les résultats de « table » et filtre les résultats à partir de la valeur retournée par la requête interne.
> A noter : il est possible dutiliser nimporte quel opérateur dégalité > tel que =, >, <, >=, <= ou <>.
Requête imbriquée qui retourne une colonne
Une requête imbriquée peut également retourner une colonne entière. Dès lors, la requête externe peut utiliser la commande IN pour filtrer les lignes qui possèdent une des valeurs retournées par la requête interne. Lexemple ci-dessous met en évidence un tel cas de figure :
SELECT *
FROM `table`
WHERE `nom_colonne` IN (
SELECT `colonne`
FROM `table2`
WHERE `cle_etrangere` = 36
)
Exemple
Imaginons un site web qui permet de poser des questions et dy répondre. Un tel site possède une base de données avec une table pour les questions et une autre pour les réponses.
Table « question » :
| q_id | q_date_ajout | q_titre | q_contenu |
|---|---|---|---|
| 1 | 2013-03-24 12:54:32 | Comment réparer un ordinateur? | Bonjour, j'ai mon ordinateur de cassé, comment puis-je procéder pour le réparer? |
| 2 | 2013-03-26 19:27:41 | Comment changer un pneu? | Quel est la meilleure méthode pour changer un pneu facilement ? |
| 3 | 2013-04-18 20:09:56 | Que faire si un appareil est cassé? | Est-il préférable de réparer les appareils électriques ou d'en acheter de nouveaux? |
| 4 | 2013-04-22 17:14:27 | Comment faire nettoyer un clavier d'ordinateur? | Bonjour, sous mon clavier d'ordinateur il y a beaucoup de poussière, comment faut-il procéder pour le nettoyer? Merci. |
Table « reponse » :
| r_id | r_fk_question_id | r_date_ajout | r_contenu |
|---|---|---|---|
| 1 | 1 | 2013-03-27 07:44:32 | Bonjour. Pouvez-vous expliquer ce qui ne fonctionne pas avec votre ordinateur? Merci. |
| 2 | 1 | 2013-03-28 19:27:11 | Bonsoir, le plus simple consiste à faire appel à un professionnel pour réparer un ordinateur. Cordialement, |
| 3 | 2 | 2013-05-09 22:10:09 | Des conseils sont disponibles sur internet sur ce sujet. |
| 4 | 3 | 2013-05-24 09:47:12 | Bonjour. ça dépend de vous, de votre budget et de vos préférence vis-à-vis de l'écologie. Cordialement, |
Requête imbriquée qui retourne un seul résultat
Avec une telle application, il est peut-être utile de connaître la question liée à la dernière réponse ajoutée sur lapplication. Cela peut être effectué via la requête SQL suivante :
SELECT *
FROM `question`
WHERE q_id = (
SELECT r_fk_question_id
FROM `reponse`
ORDER BY r_date_ajout DESC
LIMIT 1
)
Une telle requête va retourner la ligne suivante :
| q_id | q_date_ajout | q_titre | q_contenu |
|---|---|---|---|
| 3 | 2013-04-18 20:09:56 | Que faire si un appareil est cassé ? | Est-il préférable de réparer les appareils électriques ou d'en acheter de nouveaux ? |
Ce résultat démontre que la question liée à la dernière réponse sur le forum est bien trouvée à partir de ce résultat.
Requête imbriquée qui retourne une colonne
Imaginons maintenant que lon souhaite obtenir les questions liées à toutes les réponses comprises entre 2 dates. Ces questions peuvent être récupérées par la requête SQL suivante :
SELECT *
FROM `question`
WHERE q_id IN (
SELECT r_fk_question_id
FROM `reponse`
WHERE r_date_ajout BETWEEN '2013-01-01' AND '2013-12-31'
)
Résultats :
| q_id | q_date_ajout | q_titre | q_contenu |
|---|---|---|---|
| 1 | 2013-03-24 12:54:32 | Comment réparer un ordinateur ? | Bonjour, j'ai mon ordinateur de cassé, comment puis-je procéder pour le réparer ? |
| 2 | 2013-03-26 19:27:41 | Comment changer un pneu ? | Quelle est la meilleure méthode pour changer un pneu facilement ? |
| 3 | 2013-04-18 20:09:56 | Que faire si un appareil est cassé ? | Est-il préférable de réparer les appareils électriques ou d'en acheter de nouveaux ? |
Une telle requête permet donc de récupérer les questions qui ont eu des réponses entre 2 dates. Cest pratique dans notre cas pour éviter dobtenir des questions qui nont pas eu de réponses du tout ou pas de nouvelles réponses depuis longtemps.
SQL EXISTS
**A noter : ** cette commande nest pas à confondre avec la clause IN. La commande EXISTS vérifie si la sous-requête retourne un résultat ou non, tandis que IN vérifie la concordance dune à plusieurs données.
Lutilisation basique de la commande EXISTS consiste à vérifier si une sous-requête retourne un résultat ou non, en utilisant EXISTS dans la clause conditionnelle. La requête externe sexécutera uniquement si la requête interne retourne au moins un résultat.
SELECT nom_colonne1
FROM `table1`
WHERE EXISTS (
SELECT nom_colonne2
FROM `table2`
WHERE nom_colonne3 = 10
)
Dans lexemple ci-dessus, sil y a au moins une ligne dans table2 dont nom_colonne3 contient la valeur 10, alors la sous-requête retournera au moins un résultat. Dès lors, la condition sera vérifiée et la requête principale retournera les résultats de la colonne nom_colonne1 de table1.
Exemple
Dans le but de montrer un exemple concret dapplication, imaginons un système composé dune table qui contient des commandes et dune table contenant des produits.
Table commande :
| c_id | c_date_achat | c_produit_id | c_quantite_produit |
|---|---|---|---|
| 1 | 2014-01-08 | 2 | 1 |
| 2 | 2014-01-24 | 3 | 2 |
| 3 | 2014-02-14 | 8 | 1 |
| 4 | 2014-03-23 | 10 | 1 |
Table produit :
| p_id | p_nom | p_date_ajout | p_prix |
|---|---|---|---|
| 2 | Ordinateur | 2013-11-17 | 799.9 |
| 3 | Clavier | 2013-11-27 | 49.9 |
| 4 | Souris | 2013-12-04 | 15 |
| 5 | Ecran | 2013-12-15 | 250 |
Il est possible deffectuer une requête SQL qui affiche les commandes pour lesquelles il y a effectivement un produit. Cette requête peut être interprétée de la façon suivante :
SELECT *
FROM commande
WHERE EXISTS (
SELECT *
FROM produit
WHERE c_produit_id = p_id
)
Résultat :
| c_id | c_date_achat | c_produit_id | c_quantite_produit |
|---|---|---|---|
| 1 | 2014-01-08 | 2 | 1 |
| 2 | 2014-01-24 | 3 | 2 |
Le résultat démontre bien que seules les commandes n°1 et n°2 ont un produit qui se trouve dans la table produit (cf. la condition c_produit_id = p_id). Cette requête est intéressante sachant quelle ninfluence pas le résultat de la requête principale, contrairement à lutilisation dune jointure qui va concaténer les colonnes des 2 tables jointes.
SQL ALL
Dans le langage SQL, la commande ALL permet de comparer une valeur dans lensemble de valeurs dune sous-requête. En dautres mots, cette commande permet de sassurer quune condition est « égale », « différente », « supérieure », « inférieure », « supérieure ou égale » ou « inférieure ou égale» pour tous les résultats retourné par une sous-requête.
Cette commande sutilise dans une clause conditionnelle entre lopérateur de condition et la sous-requête. Lexemple ci-dessous montre un exemple basique :
SELECT *
FROM table1
WHERE condition > ALL (
SELECT *
FROM table2
WHERE condition2
)
A savoir : les opérateurs conditionnels peuvent être les suivants : =, <, >, <>, !=, <=, >=, !> ou !<.
Exemple
Imaginons une requête similaire à la syntaxe de base présentée précédemment :
SELECT colonne1
FROM table1
WHERE colonne1 > ALL (
SELECT colonne1
FROM table2
)
Avec cette requête, si nous supposons que dans table1 il y a un résultat avec la valeur 10, voici les différents résultats de la conditions selon le contenu de table2 :
- La condition est vraie (cf. TRUE) si table2 contient {-5,0,+5} car toutes les valeurs sont inférieures à 10
- La condition est fausse (cf. FALSE) si table2 contient {12,6,NULL,-100} car au moins une valeur est inférieure à 10
- La condition est non connue (cf. UNKNOW) si table2 est vide
SQL ANY / SOME
Dans le langage SQL, la commande ANY (ou SOME) permet de comparer une valeur avec le résultat dune sous-requête. Il est ainsi possible de vérifier si une valeur est « égale », « différente », « supérieure », « supérieure ou égale », « inférieure » ou « inférieure ou égale » pour au moins une des valeurs de la sous-requête.
> A noter : le mot-clé SOME est un alias de ANY, lun ou lautre des termes > peut être utilisé.
Cette commande sutilise dans une clause conditionnelle juste après un opérateur conditionnel et juste avant une sous-requête. Lexemple ci-dessous démontre une utilisation basique de ANY dans une requête SQL :
SELECT *
FROM table1
WHERE condition > ANY (
SELECT *
FROM table2
WHERE condition2
)
Cette requête peut se traduire de la façon suivante : sélectionner toutes les colonnes de table1, où la condition est supérieure à nimporte quel résultat de la sous-requête.
Exemple
En se basant sur lexemple relativement simple présenté ci-dessus, il est possible deffectuer une requête concrète qui utilise la commande ANY :
SELECT colonne1
FROM table1
WHERE colonne1 > ANY (
SELECT colonne1
FROM table2
)
Supposons que la table1 possède un seul résultat dans lequel colonne1 est égal à 10.
- La condition est vraie (cf. TRUE) si table2 contient {21,14,7} car il y a au moins une valeur inférieure à 10
- La condition est fausse (cf. FALSE) si table2 contient {20,10} car aucune valeur est strictement inférieure à 10
- La condition est non connue (cf. UNKNOW) si table2 est vide
Astuce : La commande IN est équivalente à lopérateur = suivi de ANY.
1.5. Jointure SQL
Les jointures en SQL permettent dassocier plusieurs tables dans une même requête. Cela permet dexploiter la puissance des bases de données relationnelles pour obtenir des résultats qui combinent les données de plusieurs tables de manière efficace.
Exemple
En général, les jointures consistent à associer des lignes de 2 tables en associant légalité des valeurs dune colonne dune première table par rapport à la valeur dune colonne dune seconde table. Imaginons quune base de données possède une table « utilisateur » et une autre table « adresse » qui contient les adresses de ces utilisateurs. Avec une jointure, il est possible dobtenir les données de lutilisateur et de son adresse en une seule requête.
On peut aussi imaginer quun site web possède une table pour les articles (titre, contenu, date de publication ) et une autre pour les rédacteurs (nom, date dinscription, date de naissance ). Avec une jointure il est possible deffectuer une seule recherche pour afficher un article et le nom du rédacteur. Cela évite davoir à afficher le nom du rédacteur dans la table « article ».
Il y a dautres cas de jointure, incluant des jointures sur la même table ou des jointures dinégalité. Ces cas étant assez particuliers et pas si simple à comprendre, ils ne seront pas élaborés dans ce document.
Types de jointures
Il y a plusieurs méthodes pour associer 2 tables ensemble. Voici la liste des différentes techniques qui sont utilisées :
INNER JOIN : jointure interne pour retourner les enregistrements quand la condition est vraie dans les 2 tables. Cest lune des jointures les plus communes.
CROSS JOIN : jointure croisée permettant de faire le produit cartésien de 2 tables. En dautres mots, permet de joindre chaque ligne dune table avec chaque ligne dune seconde table. Attention, le nombre de lignes résultant est en général très élevé.
**LEFT JOIN (ou LEFT OUTER JOIN) : ** jointure externe pour retourner tous les enregistrements de la table de gauche (LEFT = gauche) même si la condition nest pas vérifiée dans lautre table.
**RIGHT JOIN (ou RIGHT OUTER JOIN) : ** jointure externe pour retourner tous les enregistrements de la table de droite (RIGHT = droite) même si la condition nest pas vérifiée dans lautre table.
**FULL JOIN (ou FULL OUTER JOIN) : ** jointure externe pour retourner les résultats quand la condition est vraie dans au moins une des 2 tables.
**SELF JOIN : ** permet deffectuer une jointure dune table avec elle-même comme si cétait une autre table.
**NATURAL JOIN : ** jointure naturelle entre 2 tables sil y a au moins une colonne qui porte le même nom entre les 2 tables SQL
UNION JOIN : jointure dunion
SQL INNER JOIN
Dans le langage SQL la commande INNER JOIN, aussi appelée EQUIJOIN, est un type de jointure très communes pour lier plusieurs tables entre-elles. Cette commande retourne les enregistrements lorsquil y a au moins une ligne dans chaque colonne qui correspond à la condition.
Pour utiliser ce type de jointure il convient dutiliser une requête SQL avec cette syntaxe :
SELECT *
FROM table1
INNER JOIN table2 ON table1.id = table2.fk_id
La syntaxe ci-dessus stipule quil faut sélectionner les enregistrements des tables table1 et table2 lorsque les données de la colonne « id » de table1 sont égales aux données de la colonne fk_id de table2.
La jointure SQL peux aussi être écrite de la façon suivante :
SELECT *
FROM table1
INNER JOIN table2
WHERE table1.id = table2.fk_id
La syntaxe avec la condition WHERE est une manière alternative de faire la jointure mais qui possède linconvénient dêtre moins facile à lire sil y a déjà plusieurs conditions dans le WHERE.
Exemple
Imaginons une application qui possède une table utilisateur ainsi quune table commande qui contienne toutes les commandes effectuées par les utilisateurs.
Table utilisateur :
| id | prenom | nom | ville | |
|---|---|---|---|---|
| 1 | Aimée | Marechal | aime.marechal@example.com | Paris |
| 2 | Esmée | Lefort | esmee.lefort@example.com | Lyon |
| 3 | Marine | Prevost | m.prevost@example.com | Lille |
| 4 | Luc | Rolland | lucrolland@example.com | Marseille |
Table commande :
| utilisateur_id | date_achat | num_facture | prix_total |
|---|---|---|---|
| 1 | 2013-01-23 | A00103 | 203.14 |
| 1 | 2013-02-14 | A00104 | 124.00 |
| 2 | 2013-02-17 | A00105 | 149.45 |
| 2 | 2013-02-21 | A00106 | 235.35 |
| 5 | 2013-03-02 | A00107 | 47.58 |
Pour afficher toutes les commandes associées aux utilisateurs, il est possible dutiliser la requête suivante :
SELECT id, prenom, nom, date_achat, num_facture, prix_total
FROM utilisateur
INNER JOIN commande ON utilisateur.id = commande.utilisateur_id
Résultats :
| id | prenom | nom | date_achat | num_facture | prix_total |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | 2013-01-23 | A00103 | 203.14 |
| 1 | Aimée | Marechal | 2013-02-14 | A00104 | 124.00 |
| 2 | Esmée | Lefort | 2013-02-17 | A00105 | 149.45 |
| 2 | Esmée | Lefort | 2013-02-21 | A00106 | 235.35 |
Le résultat de la requête montre parfaitement la jointure entre les 2 tables. Les utilisateurs 3 et 4 ne sont pas affichés puisquil ny a pas de commande associée à ces utilisateurs.
*
Attention : il est important de noter que si un utilisateur à été supprimé, alors on ne verra pas ses commandes dans la liste puisque INNER JOIN retourne uniquement les résultats où la condition est vraie dans les 2 tables.
SQL CROSS JOIN
Dans le langage SQL, la commande CROSS JOIN est un type de jointure sur 2 tables SQL qui permet de retourner le produit cartésien. Autrement dit, cela permet de retourner chaque ligne dune table avec chaque ligne dune autre table. Ainsi effectuer le produit cartésien dune table A qui contient 30 résultats avec une table B de 40 résultats va produire 1200 résultats (30 x 40 = 1200). En général la commande CROSS JOIN est combinée avec la commande WHERE pour filtrer les résultats qui respectent certaines conditions.
Attention, le nombre de résultat peut facilement être très élevé. Sil est effectué sur des tables avec beaucoup denregistrements, cela peut ralentir sensiblement le serveur.
Pour effectuer un jointure avec CROSS JOIN, il convient deffectuer une requête SQL respectant la syntaxe suivante :
SELECT *
FROM table1
CROSS JOIN table2
Méthode alternative pour retourner les mêmes résultats :
SELECT *
FROM table1, table2
Lune ou lautre de ces syntaxes permettent dassocier tous les résultats de table1 avec chacun des résultats de table2.
Exemple
Imaginons une application de recettes de cuisines qui contient 2 tables dingrédients, la table legume et la table fruit.
Table legume :
| l_id | l_nom_fr_fr | l_nom_en_gb |
|---|---|---|
| 45 | Carotte | Carott |
| 46 | Oignon | Onion |
| 47 | Poireau | Leek |
Table fruit :
| f_id | f_nom_fr_fr | f_nom_en_gb |
|---|---|---|
| 87 | Banane | Banana |
| 88 | Kiwi | Kiwi |
| 89 | Poire | Pear |
Pour une raison quelconque lapplication doit associer tous les légumes avec tous les fruits. Toutes les combinaisons doivent être affichées. Pour cela il convient deffectuer lune ou lautre des requêtes suivantes :
``
SELECT l_id, l_nom_fr_fr, f_id, f_nom_fr_fr
FROM legume
CROSS JOIN fruit
ou :
SELECT l_id, l_nom_fr_fr, f_id, f_nom_fr_fr
FROM legume, fruit
Résultats :
| l_id | l_nom_fr_fr | f_id | f_nom_fr_fr |
|---|---|---|---|
| 45 | Carotte | 87 | Banane |
| 45 | Carotte | 88 | Kiwi |
| 45 | Carotte | 89 | Poire |
| 46 | Oignon | 87 | Banane |
| 46 | Oignon | 88 | Kiwi |
| 46 | Oignon | 89 | Poire |
| 47 | Poireau | 87 | Banane |
| 47 | Poireau | 88 | Kiwi |
| 47 | Poireau | 89 | Poire |
Le résultat montre bien que chaque légume est associé à chaque fruit. Avec 3 fruits et 3 légumes, il y a donc 9 lignes de résultat (3x3 = 9).
SQL LEFT JOIN
Dans le langage SQL, la commande LEFT JOIN (aussi appelée LEFT OUTER JOIN) est un type de jointure entre 2 tables. Cela permet de lister tous les résultats de la table de gauche (left = gauche) même sil ny a pas de correspondance dans la deuxième table.
Pour lister les enregistrements de table1, même sil ny a pas de correspondance avec table2, il convient deffectuer une requête SQL utilisant la syntaxe suivante.
SELECT *
FROM table1
LEFT JOIN table2 ON table1.id = table2.fk_id
La requête peut aussi sécrire de la façon suivante :
SELECT *
FROM table1
LEFT OUTER JOIN table2 ON table1.id = table2.fk_id
Cette requête est particulièrement intéressante pour récupérer les informations de table1 tout en récupérant les données associées, même sil ny a pas de correspondance avec table2. A savoir, sil ny a pas de correspondance, les colonnes de table2 vaudront toutes NULL.
Exemple
Imaginons une application contenant des utilisateurs et des commandes pour chacun de ces utilisateurs. La base de données de cette application contient une table pour les utilisateurs et sauvegarde leurs achats dans une seconde table. Les 2 tables sont reliées grâce à la colonne utilisateur_id de la table des commandes. Cela permet dassocier une commande à un utilisateur.
Table utilisateur :
| id | prenom | nom | ville | |
|---|---|---|---|---|
| 1 | Aimée | Marechal | aime.marechal@example.com | Paris |
| 2 | Esmée | Lefort | esmee.lefort@example.com | Lyon |
| 3 | Marine | Prevost | m.prevost@example.com | Lille |
| 4 | Luc | Rolland | lucrolland@example.com | Marseille |
Table commande :
| utilisateur_id | date_achat | num_facture | prix_total |
|---|---|---|---|
| 1 | 2013-01-23 | A00103 | 203.14 |
| 1 | 2013-02-14 | A00104 | 124.00 |
| 2 | 2013-02-17 | A00105 | 149.45 |
| 2 | 2013-02-21 | A00106 | 235.35 |
| 5 | 2013-03-02 | A00107 | 47.58 |
Pour lister tous les utilisateurs avec leurs commandes et afficher également les utilisateurs qui nont pas effectué dachat, il est possible dutiliser la requête suivante :
``
SELECT *
FROM utilisateur
LEFT JOIN commande ON utilisateur.id = commande.utilisateur_id
Résultats :
| id | prenom | nom | date_achat | num_facture | prix_total |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | 2013-01-23 | A00103 | 203.14 |
| 1 | Aimée | Marechal | 2013-02-14 | A00104 | 124.00 |
| 2 | Esmée | Lefort | 2013-02-17 | A00105 | 149.45 |
| 2 | Esmée | Lefort | 2013-02-21 | A00106 | 235.35 |
| 3 | Marine | Prevost | NULL | NULL | NULL |
| 4 | Luc | Rolland | NULL | NULL | NULL |
Les dernières lignes montrent des utilisateurs qui nont effectué aucune commande. La ligne retourne la valeur NULL pour les colonnes concernant les achats quils nont pas effectués.
Filtrer sur la valeur NULL
Attention, la valeur NULL nest pas une chaîne de caractère. Pour filtrer sur ces caractères il faut utiliser la commande IS NULL. Par exemple, pour lister les utilisateurs qui nont pas effectué dachat il est possible dutiliser la requête suivante.
SELECT id, prenom, nom, utilisateur_id
FROM utilisateur
LEFT JOIN commande ON utilisateur.id = commande.utilisateur_id
WHERE utilisateur_id IS NULL
Résultats :
| id | prenom | nom | utilisateur_id |
|---|---|---|---|
| 3 | Marine | Prevost | NULL |
| 4 | Luc | Rolland | NULL |
SQL RIGHT JOIN
En SQL, la commande RIGHT JOIN (ou RIGHT OUTER JOIN) est un type de jointure entre 2 tables qui permet de retourner tous les enregistrements de la table de droite (right = droite) même sil ny a pas de correspondance avec la table de gauche. Sil y a un enregistrement de la table de droite qui ne trouve pas de correspondance dans la table de gauche, alors les colonnes de la table de gauche auront NULL pour valeur.
Lutilisation de cette commande SQL seffectue de la façon suivante :
SELECT *
FROM table1
RIGHT JOIN table2 ON table1.id = table2.fk_id
La syntaxe de cette requête SQL peut aussi sécrire de la façon suivante :
SELECT *
FROM table1
RIGHT OUTER JOIN table2 ON table1.id = table2.fk_id
Cette syntaxe stipule quil faut lister toutes les lignes du tableau table2 (tableau de droite) et afficher les données associées du tableau table1 sil y a une correspondance entre ID de table1 et FK_ID de table2. Sil ny a pas de correspondance, lenregistrement de table2 sera affiché et les colonnes de table1 vaudront toutes NULL.
Exemple
Prenons lexemple dune base de données qui contient des utilisateurs et un historique dachat de ces utilisateurs. Ces deux tables sont reliées entre elles grâce à la colonne utilisateur_id de la table des commandes. Cela permet de savoir à quel utilisateur est associé un achat.
Table utilisateur :
| id | prenom | nom | ville | actif | |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | aime.marechal@example.com | Paris | 1 |
| 2 | Esmée | Lefort | esmee.lefort@example.com | Lyon | 0 |
| 3 | Marine | Prevost | m.prevost@example.com | Lille | 1 |
| 4 | Luc | Rolland | lucrolland@example.com | Marseille | 1 |
Table commande :
| utilisateur_id | date_achat | num_facture | prix_total |
|---|---|---|---|
| 1 | 2013-01-23 | A00103 | 203.14 |
| 1 | 2013-02-14 | A00104 | 124.00 |
| 2 | 2013-02-17 | A00105 | 149.45 |
| 3 | 2013-02-21 | A00106 | 235.35 |
| 5 | 2013-03-02 | A00107 | 47.58 |
Pour afficher toutes les commandes avec le nom de lutilisateur correspondant il est normalement habituel dutiliser INNER JOIN en SQL. Malheureusement, si lutilisateur a été supprimé de la table, alors cela ne retourne pas lachat. Lutilisation de RIGHT JOIN permet de retourner tous les achats et dafficher le nom de lutilisateur sil existe. Pour cela il convient dutiliser cette requête :
SELECT id, prenom, nom, utilisateur_id, date_achat, num_facture
FROM utilisateur
RIGHT JOIN commande ON utilisateur.id = commande.utilisateur_id
Résultats :
| id | prenom | nom | utilisateur_id | date_achat | num_facture |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | 1 | 2013-01-23 | A00103 |
| 1 | Aimée | Marechal | 1 | 2013-02-14 | A00104 |
| 2 | Esmée | Lefort | 2 | 2013-02-17 | A00105 |
| 3 | Marine | Prevost | 3 | 2013-02-21 | A00106 |
| NULL | NULL | NULL | 5 | 2013-03-02 | A00107 |
Ce résultat montre que la facture A00107 est liée à lutilisateur numéro 5. Or, cet utilisateur nexiste pas ou nexiste plus. Grâce à RIGHT JOIN, lachat est tout de même affiché mais les informations liées à lutilisateur sont remplacées par NULL.
SQL FULL JOIN
Dans le langage SQL, la commande FULL JOIN (ou FULL OUTER JOIN) permet de faire une jointure entre 2 tables. Lutilisation de cette commande permet de combiner les résultats des 2 tables, de les associer entre eux grâce à une condition et de remplir avec des valeurs NULL si la condition nest pas respectée.
Pour retourner les enregistrements de table1 et table2, il convient dutiliser une requête SQL avec une syntaxe telle que celle-ci :
SELECT *
FROM table1
FULL JOIN table2 ON table1.id = table2.fk_id
Cette requête peut aussi être conçue de cette façon :
SELECT *
FROM table1
FULL OUTER JOIN table2 ON table1.id = table2.fk_id
La condition présentée ici consiste à lier les tables sur un identifiant, mais la condition peut être définie sur dautres champs.
Exemple
Prenons lexemple dune base de données qui contient une table utilisateur ainsi quune table commande qui contient toutes les ventes.
Table utilisateur :
| id | prenom | nom | ville | actif | |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | aime.marechal@example.com | Paris | 1 |
| 2 | Esmée | Lefort | esmee.lefort@example.com | Lyon | 0 |
| 3 | Marine | Prevost | m.prevost@example.com | Lille | 1 |
| 4 | Luc | Rolland | lucrolland@example.com | Marseille | 1 |
Table commande :
| utilisateur_id | date_achat | num_facture | prix_total |
|---|---|---|---|
| 1 | 2013-01-23 | A00103 | 203.14 |
| 1 | 2013-02-14 | A00104 | 124.00 |
| 2 | 2013-02-17 | A00105 | 149.45 |
| 3 | 2013-02-21 | A00106 | 235.35 |
| 5 | 2013-03-02 | A00107 | 47.58 |
Il est possible dutiliser FULL JOIN pour lister tous les utilisateurs ayant effectué ou non une vente, et de lister toutes les ventes qui sont associées ou non à un utilisateur. La requête SQL est la suivante :
SELECT id, prenom, nom, utilisateur_id, date_achat, num_facture
FROM utilisateur
FULL JOIN commande ON utilisateur.id = commande.utilisateur_id
Résultat :
| id | prenom | nom | utilisateur_id | date_achat | num_facture |
|---|---|---|---|---|---|
| 1 | Aimée | Marechal | 1 | 2013-01-23 | A00103 |
| 1 | Aimée | Marechal | 1 | 2013-02-14 | A00104 |
| 2 | Esmée | Lefort | 2 | 2013-02-17 | A00105 |
| 3 | Marine | Prevost | 3 | 2013-02-21 | A00106 |
| 4 | Luc | Rolland | NULL | NULL | NULL |
| NULL | NULL | 5 | 2013-03-02 | A00107 |
Ce résultat affiche bien lutilisateur numéro 4 qui na effectué aucun achat. Le résultat retourne également la facture A00107 qui est associée à un utilisateur qui nexiste pas (ou qui nexiste plus). Dans les cas où il ny a pas de correspondance avec lautre table, les valeurs des colonnes valent NULL.
SQL NATURAL JOIN
Dans le langage SQL, la commande NATURAL JOIN permet de faire une jointure naturelle entre 2 tables. Cette jointure seffectue à la condition quil y ait des colonnes du même nom et de même type dans les 2 tables. Le résultat dune jointure naturelle est la création dun tableau avec autant de lignes quil y a de paires correspondant à lassociation des colonnes de même nom.
> **A noter : ** puisquil faut le même nom de colonne sur les 2 tables, cela > empêche dutiliser certaines règles de nommages pour le nom des colonnes. Il > nest par exemple pas possible de préfixer le nom des colonnes sous peine > davoir malheureusement 2 noms de colonne différents.
La jointure naturelle de 2 tables peut seffectuer facilement, comme le montre la requête SQL suivante :
SELECT *
FROM table1
NATURAL JOIN table2
Lavantage dun NATURAL JOIN cest quil ny a pas besoin dutiliser la clause ON.
Exemple
Une utilisation classique dune telle jointure pourrait être lutilisation dans une application qui utilise une table utilisateur et une table pays. Si la table utilisateur contient une colonne pour lidentifiant du pays, il sera possible deffectuer une jointure naturelle.
*
Table « utilisateur » :
| user_id | user_prenom | user_ville | pays_id |
|---|---|---|---|
| 1 | Jérémie | Paris | 1 |
| 2 | Damien | Montréal | 2 |
| 3 | Sophie | Marseille | NULL |
| 4 | Yann | Lille | 9999 |
| 5 | Léa | Paris | 1 |
Table « pays » :
| pays_id | pays_nom |
|---|---|
| 1 | France |
| 2 | Canada |
| 3 | Belgique |
| 4 | Suisse |
Pour avoir la liste de tous les utilisateurs avec le pays correspondant, il est possible deffectuer une requête SQL similaire à celle-ci :
SELECT *
FROM utilisateur
NATURAL JOIN pays
Cette requête retournera le résultat suivant :
| pays_id | user_id | user_prenom | user_ville | pays_nom |
|---|---|---|---|---|
| 1 | 1 | Jérémie | Paris | France |
| 2 | 2 | Damien | Montréal | Canada |
| NULL | 3 | Sophie | Marseille | NULL |
| 9999 | 4 | Yann | Lille | NULL |
| 1 | 5 | Léa | Paris | France |
Cet exemple montre quil y a bien eu une jointure entre les 2 tables grâce à la colonne « pays_id » qui se trouve dans lune et lautre des tables.
SQL SELF JOIN
En SQL, un SELF JOIN correspond à une jointure dune table avec elle-même. Ce type de requête nest pas si commun mais très pratique dans le cas où une table lie des informations avec des enregistrements de la même table.
Pour effectuer un SELF JOIN, la syntaxe de la requête SQL est la suivante :
SELECT `t1`.`nom_colonne1`, `t1`.`nom_colonne2`, `t2`.`nom_colonne1`, `t2`.`nom_colonne2`
FROM `table` AS `t1`
LEFT OUTER JOIN `table` AS `t2` ON `t2`.`fk_id` = `t1`.`id`
Ici la jointure est effectuée avec un LEFT JOIN, mais il est aussi possible de leffectuer avec dautres types de jointures.
Exemple
Un exemple potentiel pourrait être une application dun intranet dentreprise qui possède la table des employés avec la hiérarchie entre eux. Les employés peuvent être dirigés par un supérieur direct qui se trouve lui-même dans la table.
Table utilisateur :
| id | prenom | nom | manager_id | |
|---|---|---|---|---|
| 1 | Sebastien | Martin | s.martin@example.com | NULL |
| 2 | Gustave | Dubois | g.dubois@example.com | NULL |
| 3 | Georgette | Leroy | g.leroy@example.com | 1 |
| 4 | Gregory | Roux | g.roux@example.com | 2 |
Les enregistrements de la table ci-dessus montre bien des employés. Les premiers employés nont pas de supérieur, tandis que les employés n°3 et n°4 ont respectivement pour supérieur lemployé n°1 et lemployé n°2.
Il est possible de lister sur une même ligne les employés avec leurs supérieurs directs, grâce à une requête telle que celle-ci :
SELECT `u1`.`u_id`, `u1`.`u_nom`, `u2`.`u_id`, `u2`.`u_nom`
FROM `utilisateur` AS `u1`
LEFT OUTER JOIN `utilisateur` AS `u2` ON `u2`.`u_manager_id` = `u1`.`u_id`
Résultat :
| u1_id | u1_prenom | u1_nom | u1_email | u1_manager_id | u2_prenom | u2_nom |
|---|---|---|---|---|---|---|
| 1 | Sebastien | Martin | s.martin@example.com | NULL | NULL | NULL |
| 2 | Gustave | Dubois | g.dubois@example.com | NULL | NULL | NULL |
| 3 | Georgette | Leroy | g.leroy@example.com | 1 | Sebastien | Martin |
| 4 | Gregory | Roux | g.roux@example.com | 2 | Gustave | Dubois |
Il n'est pas possible d'inclure la colonne non agrégée dans la liste de sélection lorsque vous utilisez une clause "group by" dans SQL Server.
Si on a besoin de remonter les données d'une colonne d'une table regroupé et dont la colonne ne fait pas partie du regroupement. On ne peut pas employer de fonction d'agregat sur la donnée. Dans ce cas on fait une jointure avec la même table. Par exemple pour remonter la derniere opération enregistrée de chaques comptes de toto.
SELECT Montant, DATE, gpoper.noCompte
FROM operations
INNER JOIN
( SELECT
noCompte
MAX(id) AS maxId
FROM operations
GROUP BY noCompte) AS gpoper
ON operations.Id = gpoper.maxId
WHERE operations.noCompte
IN (SELECT noComptes FROM comptes WHERE name = 'toto')
SQL OVER
Nous devons générer un rapport qui affiche le nombre total d'employés par département. Nous devons également afficher le salaire total, le salaire moyen, le salaire minimum et le salaire maximum par département. Nous devons également afficher les valeurs non agrégées (nom et salaire) dans le rapport avec les valeurs agrégées, comme le montre l'image ci-dessous. Cela signifie que nous devons générer un rapport comme ci-dessous.
| Name | Salary | Dept | DeptTotal | TotSalary | AvgSalary | MinSalary | MaxSalary |
|---|---|---|---|---|---|---|---|
| Rasol | 15000 | HR | 4 | 152000 | 38000 | 15000 | 67000 |
| Taylor | 67000 | HR | 4 | 152000 | 38000 | 15000 | 67000 |
| David | 96000 | IT | 1 | 96000 | 96000 | 96000 | 96000 |
SELECT Name, Salary, Employees.Department AS Dept,
Departments.DepartmentTotals AS DeptTotal,
Departments.TotalSalary AS TotSalary,
Departments.AvgSalary,
Departments.MinSalary,
Departments.MaxSalary
FROM Employees
INNER JOIN
( SELECT Department, COUNT(*) AS DepartmentTotals,
SUM(Salary) AS TotalSalary,
AVG(Salary) AS AvgSalary,
MIN(Salary) AS MinSalary,
MAX(Salary) AS MaxSalary
FROM Employees
GROUP BY Department) AS Departments
ON Departments.Department = Employees.Department
La même requette en utilisant OVER :
SELECT Name,
Salary,
Department AS Dept,
COUNT(Department) OVER(PARTITION BY Department) AS DepartmentTotals AS DeptTotal,
SUM(Salary) OVER(PARTITION BY Department) AS TotSalary,
AVG(Salary) OVER(PARTITION BY Department) AS AvgSalary,
MIN(Salary) OVER(PARTITION BY Department) AS MinSalary,
MAX(Salary) OVER(PARTITION BY Department) AS MaxSalary
FROM Employees
réf: How to use Over Clause in SQL Server?
https://dotnettutorials.net/lesson/over-clause-sql-server/
1.6. Traitement de masse
Pour mesurer la performante in faux vider le cache à chaque essais avec
DBCC DROPCLEANBUFFERS;
INSERT SELECT
-- Insertion multiples manuellement ou par programmation
INSERT INTO TABLE (name, age)
VALUES
('toto','2010-01-01'),
('tata','2010-01-01')
-- En utilisant une table temporaire
DECLARE @tempTable TABLE (name VARCHAR(80), age dateTime);
INSERT INTO @tempTable ...
INSERT INTO dbtable (name, age)
SELECT name, age FROM @tempTable
pour récupérer les id d'un bulkinsert
-- pour recuperer les id d'un bulkinsert
DECLARE @tablevar TABLE (ID INT);
INSERT INTO tableA
OUTPUT INSERTED.ID INTO @tablevar
VALUES (1,2), (3,4), (4,5), ....
Update Join
Cette fonction est très utile pour remplacer les curseurs.
UPDATE
Patient.LotOfInvoice
SET
Patient.LotOfInvoice.statusLotOfInvoice =
t.status
FROM
Patient.LotOfInvoice c
INNER JOIN @TableUpdateStatus t
ON c.idLotOfInvoice = t.idLot;
réf:
https://www.sqlservertutorial.net/sql-server-basics/sql-server-update-join/
Delete Join
DELETE P
FROM Product P
LEFT JOIN OrderItem I ON P.Id = I.ProductId
WHERE I.Id IS NULL
Données dans un champ XML
Attention aux champs nullables qui se traduisent en XML par un champ vide.
<Appointments>
<Appointment>
<orderId>1</orderId>
<link>f4d392d5-94ed-47d3-85a3-90772e833057</link>
<idDoctolib>4316809099</idDoctolib>
<idVeasy />
<creationDateAppointment>2023-01-12T23:12:55</creationDateAppointment>
<RefRowJadeRdv />
</Appointment>
</Appointments>
SELECT
XMLtable1.appointment.value('(orderId)[1]', 'INT') AS orderId,
CASE
WHEN XMLtable1.appointment.value('(RefRowJadeRdv)[1]', 'varchar(max)')= ''
THEN NULL
ELSE XMLtable1.appointment.value('(RefRowJadeRdv)[1]', 'varchar(max)')
END AS RefRowJadeRdv,
XMLtable1.appointment.value('(creationDateAppointment)[1]', 'datetime')
AS creationDateAppointment,
idDoctolib.value('(./text())[1]', 'BIGINT') AS idDoctolib
FROM (SELECT id, CAST(json AS xml) AS XML_DATA FROM [Calendar].[DoctolibSync]) AS SYNC
CROSS Apply SYNC.XML_DATA.nodes('/Appointments/Appointment') AS XMLtable1(appointment)
CROSS Apply appointment.nodes('idDoctolib') AS idDoctolib(idDoctolib)
WHERE idDoctolib IS NOT NULL AND idDoctolib.value('(./text())[1]', 'BIGINT') NOT IN (SELECT idSyncDocto FROM @tableDoctoAppoint) AND ID IN (SELECT id FROM @table_Id)
ORDER BY id
Données dans un champ en JSON
Pour les versions SQLServer2006 et ultérieur on peut utiliser la fonction OPENJSON, qui a de bonnes performances.
-- Minimum compatibility level
ALTER DATABASE database_name SET COMPATIBILITY_LEVEL = 130
SELECT idDoctolib, idVeasy, CONVERT(datetime, [creationDateAppointment], 126)
FROM Calendar.DoctolibSync
CROSS APPLY OPENJSON(json, '$.appointments') WITH (
idDoctolib BIGINT,
idVeasy INT,
creationDateAppointment VARCHAR(19)
)
WHERE idDoctolib IS NOT NULL)
réf: JSON in SQL Server: The Ultimate Guide - Database Star
https://www.databasestar.com/json-sql-server/
Autrement il est possible d'utiliser une fonction pour cela comme parseJSON disponible sur ce lien:
SELECT * FROM parseJSON('{ "Person":
{
"firstName": "John",
"lastName": "Smith",
"age": 25,
"Address":
{
"streetAddress":"21 2nd Street",
"city":"New York",
"state":"NY",
"postalCode":"10021"
},
"PhoneNumbers":
{
"home":"212 555-1234",
"fax":"646 555-4567"
}
}
}
')
réf: sql server - Parse JSON in TSQL - Stack Overflow
https://stackoverflow.com/questions/2867501/parse-json-in-tsql
Si le formattage du JSON est connu, que les champs sont toujours présents, il est également possible de remonter certains champs ciblés de la donnée JSON avec les fonctions SQL SUBSTRING et CHARINDEX. Cela est plus performant que d'utiliser une fonction complexe comme parseJSON
INSERT INTO tablejson(jsontext)
VALUES ('"patient": {"first_name":"toto","last_name":"donald","maiden_name":null}');
SELECT SUBSTRING(jsontext,
CHARINDEX('"first_name":', jsontext)+14,
CHARINDEX('"last_name":', jsontext)-3-CHARINDEX('"first_name":', jsontext)+13) AS first_name
FROM tablejson
WHERE CHARINDEX('"patient"', jsontext) <> 0
Pagination avec Regroupement
Pour cela vous devez appliquer rownumber aux résultats groupés.
WITH cteresults AS
(
SELECT DISTINCT MAX(i.id) AS ID,
i.itemlookupcode,
MAX(CAST(i.notes AS VARCHAR(MAX))) AS Notes,
MAX(CONVERT(VARCHAR(30), i.price, 1)) AS Price,
MAX(i.picturename) AS PictureName
FROM item AS i
LEFT JOIN nitroasl_pamtable AS n ON i.id = n.itemid
WHERE ( i.id LIKE '%hdmi%'
OR i.itemlookupcode LIKE '%hdmi%'
OR i.notes LIKE '%hdmi%'
OR i.description LIKE '%hdmi%'
OR i.extendeddescription LIKE '%hdmi%'
OR n.manufacturerpartnumber LIKE '%hdmi%'
OR n.pam_keywords LIKE '%hdmi%' )
AND (i.webitem = 0 AND i.price > 0)
GROUP BY i.itemlookupcode
)
,ctepagination AS
(
SELECT *, ROW_NUMBER() OVER(ORDER BY itemlookupcode) AS RowID
FROM cteresults
)
SELECT *
FROM ctepagination
WHERE rowid BETWEEN 1 AND 15
Trie de donnée avec pagination
Passage d'un ordre dynamique par dans une procédure stockée
CREATE TABLE t1 (id INT, name VARCHAR(50), dt DATE);
INSERT t1 VALUES
(1, 'Chihiro Ogino','2009-02-08'),
(2, 'Spirit of the Kohaku River','2008-02-08'),
(3, 'Yubaba','2012-02-08');
DECLARE @sortColumn VARCHAR(50) = 'dt'
DECLARE @sortOrder VARCHAR(50) = 'ASC'
SELECT *
FROM t1
ORDER BY
CASE
WHEN @sortOrder <> 'ASC' THEN 0
WHEN @sortColumn = 'id' THEN id
END ASC
, CASE
WHEN @sortOrder <> 'ASC' THEN ''
WHEN @sortColumn = 'name' THEN name
END ASC
, CASE
WHEN @sortOrder <> 'ASC' THEN ''
WHEN @sortColumn = 'dt' THEN name
END ASC
, CASE
WHEN @sortOrder <> 'DESC' THEN 0
WHEN @sortColumn = 'id' THEN id
END DESC
, CASE
WHEN @sortOrder <> 'DESC' THEN ''
WHEN @sortColumn = 'name' THEN name
END DESC
, CASE
WHEN @sortOrder <> 'DESC' THEN ''
WHEN @sortColumn = 'dt' THEN name
END DESC
Bulk Insert
Bulk Insert est une methode du SGBDR permettant d'inserrer des lignes en masse, dans une table à partir de données à plat (dataSet, csv, ...) Comparatif des 4 méthodes testées en millisecondes pour un jeu de données allant de 100 à 1 000 000 déléments.
| method | 10 | 10000 | 100000 | 1000000 |
|---|---|---|---|---|
| INSERT | 49 | 42023 | > 5min | xx |
| INSERT SELECT | 4 | 1428 | 14336 | > 2min |
| BULK INSERT | 2 | 75 | 658 | 6776 |
1.7. Arbres de donnees
Habituellement, une hiérarchie se représente en utilisant une autoréférence, c'est-à-dire à l'aide d'une clef étrangère provenant de la clef même de la table. Les données de cette table peuvent se représenter de la sorte :
ALL |--SEA | |--SUBMARINE | |--BOAT |--EARTH | |--CAR | |--TWO WHEELS | | |--MOTORCYCLE | | |--BICYCLE | |--TRUCK |--AIR |--ROCKET |--PLANE
Exemple
-- creation de la table
CREATE TABLE T_VEHICULE
(VHC_ID INTEGER NOT NULL PRIMARY KEY,
VHC_ID_FATHER INTEGER FOREIGN KEY REFERENCES T_VEHICULE (VHC_ID),
VHC_NAME VARCHAR(16))
-- population
INSERT INTO T_VEHICULE VALUES (1, NULL, 'ALL')
INSERT INTO T_VEHICULE VALUES (2, 1, 'SEA')
INSERT INTO T_VEHICULE VALUES (3, 1, 'EARTH')
INSERT INTO T_VEHICULE VALUES (4, 1, 'AIR')
INSERT INTO T_VEHICULE VALUES (5, 2, 'SUBMARINE')
INSERT INTO T_VEHICULE VALUES (6, 2, 'BOAT')
INSERT INTO T_VEHICULE VALUES (7, 3, 'CAR')
INSERT INTO T_VEHICULE VALUES (8, 3, 'TWO WHEELS')
INSERT INTO T_VEHICULE VALUES (9, 3, 'TRUCK')
INSERT INTO T_VEHICULE VALUES (10, 4, 'ROCKET')
INSERT INTO T_VEHICULE VALUES (11, 4, 'PLANE')
INSERT INTO T_VEHICULE VALUES (12, 8, 'MOTORCYCLE')
INSERT INTO T_VEHICULE VALUES (13, 8, 'BICYCLE');
--Sélectionnez
WITH tree (DATA, id, level, pathstr)
AS (SELECT VHC_NAME, VHC_ID, 0,
CAST('' AS VARCHAR(MAX))
FROM T_VEHICULE
WHERE VHC_ID_FATHER IS NULL
UNION ALL
SELECT VHC_NAME, VHC_ID, t.level + 1, t.pathstr + V.VHC_NAME
FROM T_VEHICULE V
INNER JOIN tree t
ON t.id = V.VHC_ID_FATHER)
SELECT SPACE(level) + DATA AS DATA, id, level, pathstr
FROM tree
ORDER BY pathstr, id
DROP TABLE T_VEHICULE
Résultats :
data id level pathstr ------------------ ----------- ----------- -------------------------------- ALL 1 0 AIR 4 1 AIR PLANE 11 2 AIRPLANE ROCKET 10 2 AIRROCKET EARTH 3 1 EARTH, CAR 7 2 EARTHCAR TRUCK 9 2 EARTHTRUCK TWO WHEEL S 8 2 EARTHTWO WHEELS BICYCLE 13 3 EARTHTWO WHEELSBICYCLE MOTORCYCLE 12 3 EARTHTWO WHEELSMOTORCYCLE SEA 2 1 SEA BOAT 6 2 SEABOAT SUBMARINE 5 2 SEASUBMARINE
réf: Requêtes récursives avec les CTE
https://sqlpro.developpez.com/cours/sqlserver/cte-recursives/
1.8. Sécurisation de scripts
Je recommande de nommer les contraintes créés, ainsi que les clé étrangères.
ALTER TABLE [MaTable] DROP CONSTRAINT [DF__MaTable__numer__0DB9F9A8]
GO
ALTER TABLE MaTable ALTER COLUMN numeroIdentification VARCHAR(10)
GO
ALTER TABLE [MaTable] ADD CONSTRAINT [DF__MaTable__numer__0DB9F9A8]
DEFAULT ('') FOR [numeroIdentification]
GO
CREATE nonclustered INDEX [IDX_MaTableNumeroIdentification]
ON Patient.LotOfInvoice (numeroIdentification)
GO
Securisation script de création de table
IF NOT EXISTS (SELECT * FROM INFORMATION_SCHEMA.TABLES WHERE TABLE_SCHEMA
= 'Common' AND TABLE_NAME = 'MaTable')
BEGIN
CREATE TABLE Common.MaTable
(
...
END
GO
Securisation script ajout de colonne
--IF COL_LENGTH('Common.MaTable', 'isActiveA') IS NULL
IF NOT EXISTS ( SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA
= 'Common' AND TABLE_NAME = 'MaTable' AND COLUMN_NAME = 'isActiveA')
BEGIN
ALTER TABLE Common.MaTable ADD
isActiveA bit NOT NULL CONSTRAINT [DF_MaTable_isActiveA] DEFAULT(0),
isActiveB bit NOT NULL CONSTRAINT [DF_MaTable_isActiveB] DEFAULT(0);
END
GO
Securisation script de création d'index
IF 0 = (SELECT COUNT(*) FROM sys.indexes WHERE name='IDX_MaTable_name'
AND object_id = OBJECT_ID('[Common].[MaTable]'))
CREATE NONCLUSTERED INDEX [IDX_MaTable_name] ON [Common].[MaTable]
(
[name] ASC
)WITH (PAD_INDEX = OFF, STATISTICS_NORECOMPUTE = OFF,
SORT_IN_TEMPDB = OFF, DROP_EXISTING = OFF, ONLINE = OFF, ALLOW_ROW_LOCKS = ON,
ALLOW_PAGE_LOCKS = ON, OPTIMIZE_FOR_SEQUENTIAL_KEY = OFF) ON [PRIMARY]
GO
Securisation script suppression de colonne
-- verifier l'integrite entre deux tables pour rajouter une cle etrangere
SELECT COUNT(*) FROM [Common].[MaTable] master WHERE NOT EXISTS (
SELECT 1
FROM [Common].[Extern]
WHERE [Common].[Extern].idExtern = master.idExtern
)
-- creation de la cle etrangele
ALTER TABLE [Common].[MaTable] WITH CHECK ADD CONSTRAINT [FK_MaTable_Extern]
FOREIGN KEY([idExtern])
REFERENCES [Common].[Extern] ([idExtern])
ON DELETE CASCADE
-- suppression de la colonne avec une cle etrangere
IF EXISTS ( SELECT * FROM INFORMATION_SCHEMA.COLUMNS WHERE TABLE_SCHEMA
= 'Common' AND TABLE_NAME = 'MaTable' AND COLUMN_NAME = 'idExtern')
BEGIN
-- suppression des references a la cle etrangere
-- TODO
-- suppression de la cle etrangere en premier
ALTER TABLE Common.MaTable DROP CONSTRAINT FK_MaTable_Extern
-- suppression de la colonne
ALTER TABLE Common.MaTable DROP COLUMN idExtern
END
GO
CHAPITRE 2 - SQL Avancé
2.1. Index SQL
En SQL, les index sont des ressources très utiles qui permettent daccéder plus rapidement aux données. Cette page explique le fonctionnement des index et leur intérêt pour accroître les performances de lecture des données.
Définition d'un index SQL
Un index, dans une base de données se base sur le même principe quun index dans un livre. Avec un index placé sur une ou plusieurs colonnes, la base de données peut rechercher les données dabord sur lindex qui lui donnera l'emplacement des enregistrements concernés.
Plus précisément, un index est une structure de données redondante qui permet dordonner les données indexées afin de retrouver le plus vite possible les données que lon index. Pour ce qui est des structures de stockage des index il en existe différentes, mais la plus utilisée est un arbre dit équilibré (on sarrange pour que le niveau des feuilles de larbre soit constant).
Lidée de lindex cluster est de faire une pierre deux coups : mélanger lindex et la table. On sévite ainsi une redondance et les lignes de la table sont physiquement triées selon lordre de la clef dindex.
Ainsi, une table dotée des colonnes Nom, Prénom, DateNaissance, Sexe, si elle est dotée dun index cluster sur Nom est physiquement triée sur les valeurs des noms des personnes. Les autres colonnes nétant pas triées. On séconomise ainsi une redondance de données.
Évidemment on ne peut avoir quun seul index cluster dans une table car en fait lindex cluster cest la table elle même !
Ces petites ressources ont toutefois leurs inconvénients car cela occupe de lespace supplémentaire dans la base de données. Par ailleurs, linsertion de données est plus long car les index sont mis à jour à chaque fois que des données sont insérées.
Généralement, un index pourra être utilisé dans les requêtes utilisant les clauses WHERE, GROUP BY ou ORDER BY. Lorsquune base de données possède un grand nombre denregistrements (exemple : plusieurs milliers ou plusieurs millions de lignes) un index permet de gagner un temps précieux pour la lecture de données.
Un index est systématiquement défini sur la clé primaire de chaque table.
SQL CREATE INDEX
En SQL, la commande CREATE INDEX permet de créer un index. Lindex est utile pour accélérer lexécution dune requête SQL qui lit des données et ainsi améliorer les performances dune application utilisant une base de données.
Créer un index ordinaire
La syntaxe basique pour créer un index est la suivante :
CREATE INDEX index_nom ON matable;
Il est également possible de créer un index sur une seule colonne en précisant la colonne sur laquelle doit sappliquer lindex :
CREATE INDEX index_nom ON matable (colonne1);
Lexemple ci-dessus va donc insérer lindex intitulé « index_nom » sur la table nommée « table » uniquement sur la colonne « colonne1? . Pour insérer un index sur plusieurs colonnes il est possible dutiliser la syntaxe suivante :
CREATE INDEX index_nom ON matable (colonne1, colonne2);
Lexemple ci-dessus permet dinsérer un index sur les 2 colonnes : colonne1 et colonne2.
Créer un index unique
Un index unique permet de spécifier quune ou plusieurs colonnes doivent contenir des valeurs uniques à chaque enregistrement. Le système de base de données retournera une erreur si une requête tente dinsérer des données qui feront doublon sur la clé dunicité. Pour insérer un tel index il suffit dexécuter une requête SQL respectant la syntaxe suivante :
CREATE UNIQUE INDEX `index_nom` ON `table` (`colonne1`);
Dans cet exemple un index unique sera créé sur la colonne nommée colonne1. Cela signifie quil ne peut pas y avoir plusieurs fois la même valeur sur 2 enregistrements distincts contenus dans cette table.
Il est également possible de créer un index dunicité sur 2 colonnes, en respectant la syntaxe suivante :
CREATE UNIQUE INDEX `index_nom` ON `table` (`colonne1`, `colonne2`);s
Inclure une colonne dans un index
Le fait d'inclure des colonnes dans les index permet d'éviter, lorsque l'index est utilisé, de devoir aller chercher des données complémentaires dans la table sous jacente.
CREATE TABLE PERSONNE(
per_id INT NOT NULL PRIMARY KEY
,per_nom VARCHAR(50)
,per_prenom VARCHAR(50)
)
CREATE INDEX IX_PERSONNE_NOM ON PERSONNE(per_nom)
SELECT COUNT(*) FROM PERSONNE WHERE per_nom = 'Dupont'
SELECT per_nom, per_prenom FROM PERSONNE WHERE per_nom = 'Dupont'sq
Ainsi, une requête count(*) utilisera l'index. En revanche, pour la requête remontant les champs per_nom et per_prenom, l'index pourrait encore être utilisé pour trouver les lignes qui vérifient la condition de filtre, mais il faudra ensuite ouvrir la table pour y trouver les prénoms. Passé un certain ratio de cardinalités, ces aller-retour deviennent trop couteux, et le moteur préférera scanner la table complète, mais une seule fois. Vous pouvez remplacer votre index par celui-ci :
CREATE INDEX IX_PERSONNE_NOM ON PERSONNE(per_nom, per_prenom)
Mais le tri sur la colonne prénom est inutile dans votre cas. Vous pouvez donc simplement mettre la colonne prenom en colonne incluse à l'index. Ainsi, l'index couvre votre requête, et il n'est plus nécessaire de lire des données dans la table.
CREATE INDEX IX_PERSONNE_NOM ON PERSONNE(per_nom) INCLUDE (per_prenom)
Convention de nommage
Il nexiste pas de convention de nommage spécifique sur le nom des index, juste des suggestions de quelques développeurs et administrateurs de bases de données. Voici une liste de suggestions de préfixes à utiliser pour nommer un index :
- Préfixe « PK_ » pour Primary Key (traduction : clé primaire)
- Préfixe « FK_ » pour Foreign Key (traduction : clé étrangère)
- Préfixe « UK_ » pour Unique Key (traduction : clé unique)
- Préfixe « UX_ » pour Unique Index (traduction : index unique)
- Préfixe « IX_ » pour chaque autre IndeX
Fragmentation de l'index
Limpact de la fragmentation des index sur SQL Server peut aller dune simple baisse de lefficacité des requêtes jusquà la décision par SQL Server de ne plus utiliser les index et se remettre à faire des lectures complètes des tables (full table scans) quelle que soit la requête. Comme mentionné précédemment, les full table scans vont avoir un impact direct et important sur les performances de SQL Server.
Pour vérifier la fragmentation des index sous sqlServer
-- listing de la fragmentation de tous les index
SELECT avg_fragmentation_in_percent AS FragmentationInPercent,
OBJECT_SCHEMA_NAME (Stats.object_id) AS SchemaName,
OBJECT_NAME (Stats.object_id) AS TableName,
Indexes.name
FROM sys.dm_db_index_physical_stats(DB_ID(), OBJECT_ID('dbo.T_CLIENT_CLI') , NULL, NULL , 'LIMITED') AS Stats
INNER JOIN sys.indexes AS Indexes ON Stats.object_id = Indexes.object_id AND Stats.index_id = Indexes.index_id
ORDER BY avg_fragmentation_in_percent DESC
-- historique de fragmentation d'un index en particulier
SELECT * FROM [dba].[dbo].[dba_indexDefragLog]
WHERE indexName='[IDX_indexName]'
ORDER BY [indexDefrag_id] DESC
Actions selon le pourcentage de fragmentation :
- moins de 10% : pas de défragmentation requise
- de 10% à 30% : il est suggéré deffectuer une réorganisation de lindex
- au dessus des 30% : il est suggéré de reconstruire lindex
La réorganisation remet l'index existant en ordre sans vérouiller la table. La reconstruction dun index supprime et recréé l'index mais vérouille la table.
Pour réorganiser l'index
ALTER INDEX ALL ON [NomDuSchema].[NomDeLaTable]
REORGANIZE ;
GO
ALTER INDEX IX_MonIndex
ON [NomDuSchema].[NomDeLaTable]
REORGANIZE ;
GO
Pour reconstruire l'index
ALTER INDEX ALL ON [NomDuSchema].[NomDeLaTable]
REBUILD ;
GO
ALTER INDEX IX_MonIndex
ON [NomDuSchema].[NomDeLaTable]
REBUILD ;
GO
réf: sql-server-quand-reconstruire-vos-index
https://blogs.infinitesquare.com/posts/divers/sql-server-quand-reconstruire-vos-index
réf: reconstruire-et-reorganiser-des-indexes-dans-sql-server
https://solutioncenter.apexsql.com/fr/pourquoi-quand-et-comment-reconstruire-et-reorganiser-des-indexes-dans-sql-server/
2.2. SQL EXPLAIN
Dans le langage SQL, linstruction EXPLAIN est à utiliser juste avant un SELECT et permet dafficher le plan dexécution dune requête SQL. Cela permet de savoir de quelle manière le Système de Gestion de Base de Données (SGBD) va exécuter la requête et sil va utiliser des index et lesquels.
En utilisant cette commande la requête ne renverra pas les résultats du SELECT mais plutôt une analyse de cette requête.
A noter : le résultat de cette instruction est différent selon les SGBD, tel que MySQL ou PostgreSQL. Par ailleurs, le nom de cette instruction diffère pour certains SGBD :
- MySQL : EXPLAIN
- PostgreSQL : EXPLAIN
- Oracle : EXPLAIN PLAN
- SQLite : EXPLAIN QUERY PLAN
- SQL Server : SET SHOWPLAN_ALL ON : informations estimées dune requête SQL, affichées au format textuel détaillé SET SHOWPLAN_TEXT ON : informations estimées dune requête SQL, affichées au format textuel simple SET SHOWPLAN_XML ON : informations estimées dune requête SQL, affichées au format XML SET STATISTICS PROFILE ON : statistiques sur lexécution dune requête SQL, affichées au format textuel SET STATISTICS XML ON : statistiques sur lexécution dune requête SQL, affichées au format XML
- Firebird : SET PLANONLY ON; puis lexécution de la requête SQL à analyser
La syntaxe ci-dessous représente une requête SQL utilisant la commande EXPLAIN pour MySQL ou PostgreSQL :
EXPLAIN SELECT *
FROM `user`
ORDER BY `id` DESC
> Rappel : dans cet exemple, la requête retournera des informations sur le > plan dexécution, mais naffichera pas les « vrais » résultats de la requête.
Exemple
Pour expliquer concrètement le fonctionnement de linstruction EXPLAIN nous allons prendre une table des fuseaux horaires en PHP. Cette table peut être créée à partir de la requête SQL suivante :
CREATE TABLE IF NOT EXISTS `timezones` (
`timezone_id` INT(10) UNSIGNED NOT NULL AUTO_INCREMENT,
`timezone_groupe_fr` VARCHAR(50) DEFAULT NULL,
`timezone_groupe_en` VARCHAR(50) DEFAULT NULL,
`timezone_detail` VARCHAR(100) DEFAULT NULL,
PRIMARY KEY (`timezone_id`)
) ENGINE=InnoDB DEFAULT CHARSET=utf8 AUTO_INCREMENT=698;
La requête ci-dessous permet de mieux comprendre la structure et les index de cette table. Imaginons que lon souhaite compter le nombre de fuseaux horaires par groupe, pour cela il est possible dutiliser la requête SQL suivante :
SELECT timezone_groupe_fr, COUNT(timezone_detail) AS total_timezone
FROM `timezones`
GROUP BY timezone_groupe_fr
ORDER BY timezone_groupe_fr ASC
Analyse de la requête SQL sans index
Nous allons voir dans notre exemple comment MySQL va exécuter cette requête. Pour cela, il faut utiliser linstruction EXPLAIN :
EXPLAIN SELECT timezone_groupe_fr, COUNT(timezone_detail) AS total_timezone
FROM `timezones`
GROUP BY timezone_groupe_fr
ORDER BY timezone_groupe_fr ASC
Le retour de cette requête SQL est le suivant :
| Id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | timezones | ALL | NULL | NULL | NULL | NULL | 421 | Using temporary: Using filesort |
Dans cet exemple on constate les champs suivants :
- id : identifiant de SELECT
- select_type : type de cause SELECT (exemple : SIMPLE, PRIMARY, UNION, DEPENDENT UNION, SUBQUERY, DEPENDENT SUBSELECT ou DERIVED)
- table : table à laquelle la ligne fait référence
- type : le type de jointure utilisé (exemple : system, const, eq_ref, ref, ref_or_null, index_merge, unique_subquery, index_subquery, range, index ou ALL)
- possible_keys : liste des index que MySQL pourrait utiliser pour accélérer lexécution de la requête. Dans notre exemple, aucun index nest disponible pour accélérer lexécution de la requête SQL
- key : cette colonne présente les index que MySQL a décidé dutiliser pour lexécution de la requête
- key_len : indique la taille de la clé qui sera utilisée. Sil ny a pas de clé, cette colonne renvois NULL
- ref : indique quelle colonne (ou constante) est utilisée avec les lignes de la table
- rows : estimation du nombre de lignes que MySQL va devoir analyser examiner pour exécuter la requête
- Extra : information additionnelle sur la façon dont MySQL va résoudre la requête. Si cette colonne retourne des résultats, cest quil y a potentiellement des index à utiliser pour optimiser les performances de la requête SQL. Le message « using temporary » permet de savoir que MySQL va devoir créer une table temporaire pour exécuter la requête. Le message « using filesort » indique quant à lui que MySQL va devoir faire un autre passage pour retourner les lignes dans le bon ordre
Ajout dun index
Il est possible dajouter un index sur la colonne « timezone_groupe_fr » à la table qui nen avait pas.
ALTER TABLE `timezones` ADD INDEX ( `timezone_groupe_fr` );
Lajout de cet index va changer la façon dont MySQL peut exécuter une requête SQL. En effectuant la même requête que tout à lheure, les résultats seront différents.
| Id | select_type | table | type | possible_keys | key | key_len | ref | rows | Extra |
|---|---|---|---|---|---|---|---|---|---|
| 1 | SIMPLE | timezones | index | NULL | index_timezone_groupe_fr | 153 | NULL | 471 |
Dans ce résultat il est possible de constater que MySQL va utiliser un lindex « index_timezone_groupe_fr » et quil ny a plus aucune information complémentaire dindiquée dans la colonne « Extra ».
réf: Cours SQL
2.3. Modes de verrouillage
a) Verrouillage pessimiste:
Lorsque quun utilisateur désire modifier une donnée, le SGBD tente de poser un verrou en écriture. Soit lopération est effective (et donc le verrou est posé), soit lopération échoue parce quun autre utilisateur a déjà posé un verrou. Si lopération est positive, pendant toute la durée de la modification, le verrou est actif pour cet utilisateur jusquà ce que lutilisateur valide ses modifications ou les annule. Dans ces deux cas le verrou est libéré.
b) Verrouillage optimiste
Lorsque quun utilisateur désire modifier une donnée, le SGBD relève le numéro de version de lenregistrement et ne pose aucun verrou. Plusieurs utilisateurs peuvent faire de même sans aucune limite. Le premier utilisateur qui valide ses modifications, incrémente le numéro de version de lenregistrement. Tous les autres se voient refuser leur modification, car le numéro de version quils ont relevé au début de la session de modification des données nest pas le même que celui quils peuvent lire à la fin de cette session.
Lorsque lon utilise la technique du verrouillage pessimiste, le SGBD effectue une boucle dattente en tentant de poser le verrou pendant n secondes. Cest comme cela que fonctionne la quasi-totalité des SGBD à base de fichiers (dBase, Paradox, FoxPro, Access ).
Effectuer une boucle dattente qui interroge un fichier, monopolise dramatiquement le réseau. Cest pourquoi la quasi-totalité des SGBD C/S fonctionne en verrouillage optimiste, car dans ce mode, léchange de données entre la base et le poste client est rapide et bref
De plus si nous prenons en compte lintégrité référentielle et que la structure de la base permet de modifier des clefs existantes en répercutant leurs valeurs dans lensemble des tables filles, alors dans le cas dun SGBD fichier ont peut obtenir un trafic réseau important, tandis que dans le cas du client serveur, lopération sera menée au sein du SGBD donc sans aucune influence sur la charge du réseau.
2.4. Le transactionnel
Le transactionnel permet de regrouper de multiples commandes SQL comme sil sagissait dune instruction de type atomique, cest à dire sexécutant en totalité ou aucunement.
Cela suppose de donner un point de départ à la transaction un point darrivée et de contrôler si lensemble des commandes SQL ont été réalisées avec succès. Dans le cas ou lune des commandes SQL na pas été traitée correctement, alors le point final de la transaction permet de revenir en arrière sur lensemble des opérations déjà effectuées. La transaction se présente alors comme une seule instruction de type tout ou rien.
Cela nest possible que sur des serveurs capables denregistrer lensemble des insertions, modifications et suppressions effectuées sur les enregistrements des tables dune base (historisation des modifications).
Supposons que les commerciaux sont dotés de PC portables et que, chaque semaine, ils viennent au siège de la société pour remplir la base centrale des nouveaux clients et des commandes quils ont saisies sur leur portable.
Pour réaliser ce recollement dinformation, linformaticien a réalisé la transaction suivante :
BEGIN TRANSACTION
INSERT INTO CENTRAL_CLIENT (NO_CLI, NOM_CLI, ADRESSE_CLI)
SELECT PC.NO_CLI, PC.NOM_CLI, PC.ADRESSE_CLI
FROM PORTABLE_CLIENT PC
INSERT INTO CENTRAL_COMMANDE (NO_CLI, NO_COM, MONTANT_COM)
SELECT PC.NO_CLI, PC.NO_COM, PC.MONTANT_COM
FROM PORTABLE_COMMANDE PC
IF ERROR
THEN
ROLLBACK
ELSE
COMMIT
ENDIF
Sil navait fait quenchaîner les deux requêtes, il aurait été possible que les clients soit insérés sans que les commandes le soit, et vice versa. Mais tous les bons SGBD, quils soient C/S ou fichier, savent gérer les intégrités référentielles et auraient empêché la moindre insertion dans la table des commandes sans avoir la référence du client préalablement insérée dans la table des clients
2.5. Les triggers, spécialités du C/S
Les triggers font correspondre aux événements dun SGBD du code.
Soit une table CLIENT liée à 3 tables filles (FACT, LIGNFACT, BONLIV). On veut modifier les tables filles lors de la suppression dun enregistrement de CLIENT:
Dans les SGBD à base de fichiers il faut rajouter du code dans tous les éléments qui effectuent la suppression dans la table mère
Dans une base de données C/S, avec un trigger, le traitement seffectue directement sur le serveur et il ne nécessite aucun appel à aucune fonction daucune sorte. Cest en effet la base elle-même qui va se rendre compte que lévénement de suppression de la table client nécessite un traitement et va lexécuter. Dans un tel exemple, le code pourrait être le suivant :
CREATE TRIGGER DELETE_CASCADE_CLIENT (CLI_ID_CLI INTEGER) BOOLEAN
BEFORE DELETE
DELETE FROM FACT WHERE (ID_CLI = CLI_ID_CLI)
DELETE FROM LIGNFACT WHERE (ID_CLI = CLI_ID_CLI)
DELETE FROM BONLIV WHERE (ID_CLI = CLI_ID_CLI)
IF ERROR
THEN
RETURN FALSE
ENDIF
RETURN TRUE
Ce trigger comportant différentes commandes SQL devra être appelé au sein dune transaction plus globale incluant la suppression de lenregistrement dans la table mère. Les commandes SQL de ce trigger réclament la suppression dans les tables FACT, LIGNFACT et BONLIV de tous les enregistrements faisant référence à lidentifiant du client transmis en paramètre. Si au moins, une des requêtes échoue, le trigger renvoi False à la procédure layant appelée et lensemble des requêtes sera annulé. Sinon, si tout va bien, le trigger renvoi True et lensemble des modifications sera rendu effectif par une validation (COMMIT).
Ce trigger est stocké au sein même de la définition de la base de données et sexécute, sur le serveur, à chaque fois quun ordre de suppression arrive dans la table CLIENT. Il ny a donc aucun trafic sur le réseau pour effectuer ce traitement
2.6. Les procédures stockées, régals du C/S
En complément aux triggers, les procédures stockées permettent de stocker un traitement (opérant en général uniquement sur les données de la base) au sein même de la base de données, qui sexécutera, par appel de la procédure au moment voulu, sur le serveur.
Exemple :
-- SQLServer
USE mabase
CREATE PROCEDURE OrdersByDate
@nomClient VARCHAR(32),
@StartDate datetime, @EndDate datetime
AS
DECLARE @idClient INT = NULL
SELECT TOP 1 @idClient=id FROM clients WHERE nameClient = @nomClient
IF @idClient IS NOT NULL
SELECT * FROM Orders
WHERE idClient=@idClient AND OrderDate BETWEEN @StartDate AND @EndDate
-- EXEC mabase.dbo.OrdersByDate '2022-01-01T00:00:00.000', '2022-12-31T23:59:59.000'
Il est possible d'utiliser des curseur, des boucle, des curseurs
Dès lors cette procédure peut être appelée nimporte quand, par nimporte quel poste client Elle sexécutera sur le serveur et ne nécessitera pratiquement aucun trafic réseau. On peut aussi imaginer quelle soit couplée avec un trigger ou encore exécutée à une heure différée, par exemple la nuit afin de ne pas ralentir les accès aux données plus fréquents en général dans la journée
Procédures avec paramètre de sortie :
DROP PROCEDURE ps_test2
GO
CREATE PROCEDURE ps_Test2
(@IDUtilisateur CHAR(20),
@MotPasseUtilisateur VARCHAR(20) output)
AS
IF EXISTS(SELECT * FROM Utilisateurs WHERE IDUtilisateur= @IDUtilisateur)
BEGIN
SELECT @MotPasseUtilisateur=MotPasseUtilisateur FROM Utilisateurs
WHERE IDUtilisateur= @IDUtilisateur
RETURN 1
END
ELSE RETURN 0
-- exécution de la procédure
DECLARE @ret INT, @mot VARCHAR(50)
EXECUTE @ret=ps_test2'Bost',@mot output
Print @ret
Print @mot
Evaluation d'une expression :
DECLARE @queryTemp VARCHAR(MAX)
DECLARE @query VARCHAR(MAX) = 'SELECT * FROM user where name=''<name>'''
SET @queryTemp = REPLACE(@query, '<name>', 'toto')
EXEC (@queryTemp)
Table en paramètre :
/* Create a table type. */
CREATE TYPE LocationTableType
AS TABLE
( LocationName VARCHAR(50)
, CostRate INT );
GO
/* Create a procedure to receive data for the table-valued parameter. */
CREATE PROCEDURE dbo. usp_InsertProductionLocation
@TVP LocationTableType READONLY
AS
SET NOCOUNT ON
INSERT INTO AdventureWorks2012.Production.Location
(
Name
, CostRate
, Availability
, ModifiedDate
)
SELECT *, 0, GETDATE()
FROM @TVP;
GO
/* Declare a variable that references the type. */
DECLARE @LocationTVP AS LocationTableType;
/* Add data to the table variable. */
INSERT INTO @LocationTVP (LocationName, CostRate)
SELECT Name, 0.00
FROM AdventureWorks2012.Person.StateProvince;
/* Pass the table variable data to a stored procedure. */
EXEC usp_InsertProductionLocation @LocationTVP;
réf:
2.7. Les curseurs
Procédure avec un curseur :
En principe il ne faux pas utiliser de curseurs car cela dégrade la performance, mais dans certains cas ils peuvent être très pratiques:
CREATE PROCEDURE dbo.uspCurrencyCursor
@CurrencyCursor CURSOR VARYING OUTPUT
AS
SET NOCOUNT ON;
SET @CurrencyCursor = CURSOR FORWARD_ONLY STATIC FOR
SELECT CurrencyCode, Name
FROM Sales.Currency;
OPEN @CurrencyCursor;
GO
DECLARE @MyCursor CURSOR;
DECLARE @CurrencyCode INT;
DECLARE @Name VARCHAR(80);
EXEC dbo.uspCurrencyCursor @CurrencyCursor = @MyCursor OUTPUT;
FETCH NEXT FROM @MyCursor INTO @CurrencyCode, @Name
WHILE (@@FETCH_STATUS = 0)
BEGIN;
FETCH NEXT FROM @MyCursor INTO @CurrencyCode, @Name;
END;
CLOSE @MyCursor;
DEALLOCATE @MyCursor;
GO
Avant d'utiliser un curseur, vérifier s'il est pas possible de faire la même chose avec une boucle WHILE qui est 20 fois plus rapide.
SET NOCOUNT ON
DECLARE @n INT,@id INT, @nom NVARCHAR(50)
SET @n=1
SET @id=0
WHILE @n > 0
BEGIN
SELECT TOP 1 @id=MaTable_ID, @nom=MaTable_Nom FROM MaTable WHERE MaTable_ID >=@id
SET @n=@@ROWCOUNT
PRINT (CAST(@id AS VARCHAR(5))+'.)'+@nom)
SET @id+= 1
END
GO
réf:
2.8. Le journal, particularité des SGBD C/S
En plus des triggers et des procédures stockées, la plupart des SGBD C/S proposent dhistoriser la « vie » des données, dans ce que lon appelle un journal des transactions. Celui-ci conserve une trace temporelle de toutes les insertions, suppressions, modifications intervenues dans la base de données depuis son origine. Ce journal permet de revenir en arrière de manière partielle sur les données. Lintérêt essentiel réside dans le fait de pouvoir, en cas de crash, revenir à un état des données satisfaisant.
Pour revenir à cet état stable, le système lit le journal en débutant par la fin, et reprend toutes les transactions qui ont été un succès, sans que la mise à jour physique des données ait été effectuée.
réf: SGBDR fichier ou client/serveur ?
https://sqlpro.developpez.com/cours/sgbdr/
2.9. Les vues
Les vues simples
Une vue est une table virtuelle dérivée de tables de base. La vue, a également l'avantage d'avoir son plan compilé sur le serveur et donc d'obtenir un léger gain dans lexécution de la requête.
On stocke seulement la définition de vue
Son contenu est généré dynamiquement
CREATE VIEW Ventelnfo
(référence, DATE, marque)
AS
SELECT P.référence, V.date,
P.marque
FROM Vente V, Produit P
WHERE P.référence =V.ref-produit;
Les vues indexés
Les vues indexées sont un excellent vecteur doptimisation pour des requêtes un peu complexes ou fréquemment utilisées contenant des agrégats ou des jointures.
A savoir on ne peut pas créer un index non clustered sur une vue, tan qu'il n'y a pas de clustered, et que la vue doit être liée au schéma avec l'option WITH SCHEMABINDING pour pouvoir créer cet index. Une vue indexé ne peut pas utiliser de jointure OUTER JOIN.
--Set the options to support indexed views.
SET NUMERIC_ROUNDABORT OFF;
SET ANSI_PADDING, ANSI_WARNINGS, CONCAT_NULL_YIELDS_NULL, ARITHABORT,
QUOTED_IDENTIFIER, ANSI_NULLS ON;
--Create view with SCHEMABINDING.
CREATE VIEW [dbo].[vProdDesc]
WITH SCHEMABINDING
AS
SELECT p.name, d.description
FROM production.product p
INNER JOIN Production.ProductModelProductDescriptionCulture dc
ON dc.ProductModelID = p.ProductModelID
AND cultureid = 'fr'
INNER JOIN production.productdescription d
ON d.ProductDescriptionID = dc.ProductDescriptionID
-- on active les statistiques
SET STATISTICS IO ON
SELECT * FROM dbo.vProdDesc
-- on cree l'index unique clustered
CREATE UNIQUE CLUSTERED INDEX IDX_V1
ON [dbo].[vProdDesc] (name, description)
SET STATISTICS IO ON
SELECT * FROM dbo.vProdDesc WITH (NOEXPAND)
-- on cree l'index non clustered
CREATE CLUSTERED INDEX IDX_V1
ON [dbo].[vProdDesc] (name, description)
SET STATISTICS IO ON
SELECT * FROM dbo.vProdDescWITH (NOEXPAND)
Je pose un index UNIQUE et CLUSTERED sur la vue et pour montrer lutilisation de lindex jexécute un simple SELECT sur la vue .
Sur l'onglet Messages on peut voir le nombre de lectures logiques.
Le plan dexécution généré montre clairement que lindex nest pas utilisé.
Indexed views can be created in any edition of SQL Server 2005. In SQL Server 2005 Enterprise Edition, the query optimizer automatically considers the indexed view. To use an indexed view in all other editions, the NOEXPAND table hint must be used.
Lédition Developer est bien bridée par rapport à la version Enterprise. Et leffet de bord à cela cest que lon ne peut pas utiliser de vue indexées dites « techniques » (ie. utilisées implicitement par loptimiseur de requêtes) car on ne peut pas préciser loption NOEXPAND si la vue nest pas utilisée directement.
SELECT * FROM dbo.vProdDesc WITH (NOEXPAND)
2.10. Impact du nombre de colonnes
La plupart des développeurs sont persuadés que mettre toutes les informations dans une même table rendra leur base de données plus rapide. Mais cest une vue à court terme, car dès que la base de données commence à croitre ou que le nombre dutilisateur augmente, les performances deviennent vite catastrophique
Différences entre des petites tables et une grosse table pour les opérations de lecture :
- Dans une table, quelle soit petite ou grande, une seule méthode doit être choisie pour accéder aux données :
- balayage de toutes les lignes de la table;
- balayage de toutes les lignes dun index;
- recherche dans un index;
- Une fois quune grande table a été morcelée en plusieurs petites tables, loptimiseur peut choisir la meilleure méthode daccès entre balayage et recherche pour chacune des tables de la requête, en préférant la recherche aussi souvent que possible.
- Sil existe plusieurs prédicats de recherches ou plusieurs conditions dans le prédicat, la seule manière dopérer dans une grande table est de balayer toute la table.
Bien entendu les recherches sont incommensurablement plus rapides que les balayages parce que leur coût est logarithmique.
Finalement et malgré le coût des jointures, une requête avec plusieurs prédicats ou conditions sexécutera beaucoup plus rapidement dès que le volume de données commence à peser dun poids important. Et plus les requêtes « roulent » vite, plus un grand nombre dutilisateurs peuvent utiliser simultanément le système
Toutes les opérations relationnelles dans une base de données sont faites exclusivement en mémoire. Aussi quelque soit la méthode daccès aux données, toutes les données nécessaires à la requête doivent être placées en RAM avant dêtre lues.
- Avec un balayage, toutes les lignes de la table doivent être placées en mémoire
- Avec une recherche, très peu de pages doivent être placées en mémoire, parce quun index est un arbre et quil suffit dy placer la page racine, les pages de navigation et la page feuille contenant les données finales.
Bien entendu un balayage place un grand nombre de page en mémoire, tandis quune recherche en place très peu.
Indexation
Un moyen de réduire drastiquement les temps daccès est dindexer la table. Cependant, nous allons découvrir quindexer une table obèse génère trois problèmes supplémentaire :
un accroissement important du volume globale de la base, une forte diminution de la concurrence en lecture comme en écriture, une optimisation notablement moins efficace
Nous supposons que les colonnes telephone, email et adresse ne sont pas toujours renseignée et dans ce cas une modélisation respectant à la lettre les principes, aurait conduit à séparer en 4 tables, ces données à savoir :
CREATE TABLE Contact
(ID_personne INT PRIMARY KEY)
CREATE TABLE Contact_TEL
(ID_personne INT PRIMARY KEY,
telephone CHAR(20) NOT NULL)
CREATE TABLE Contact_EML
(ID_personne INT PRIMARY KEY,
email VARCHAR(256));
CREATE TABLE Contact_SKP
(ID_personne INT PRIMARY KEY,
skype VARCHAR(128));
1) quelle est la version du modèle, présentant le plus fort volume ? Si nous comptons les données des tables, la base 1 (monotabulaire) compte au plus 408 octets par ligne (le INT comptant pour 4 octets).
La base 2 fait : TABLE Contact : 4 TABLE Contact_TEL : 24 TABLE Contact_MEL : 260 TABLE Contact_SKP : 132 Total base 2 : 420 octets.
La différence est minime et sil y a des NULL, leur absence de stockage dans la base 2 penchera en faveur de cette solution Mais raisonnons par labsurde et considérons un taux de NULL de zéro
Ajoutons maintenant les index À nouveau, considérons labsurde et tentons dindexer les 2 bases pour optimiser toutes les requêtes possibles.
Dans la base monotable, les index à poser, pour optimiser tous les cas de requêtes, sont les suivants :
telephone email skype CLEF D INDEX
------------- --------- ------- ------------------------------------------
X1 1 (telephone)
X2 1 (email)
X3 1 (skype)
X4 1 2 (telephone, email)
X5 1 2 (telephone, skype)
X6 1 2 (email, skype)
X7 1 2 3 (telephone, email, skype)
Cependant ces index ne suffisent pas à couvrir tous les cas de figure. En effet, les informations dun index étant vectorisées (tri de la première colonne de le clef dindex, puis tri relatif de la seconde, pour les données identiques dans la première) certaines requêtes ne peuvent bénéficier des index ci dessus.
Par exemple la clause WHERE suivante :
WHERE telephone = '0123456789' AND email LIKE 'dupont%'
pourra pleinement utiliser lindex X4, tandis que cette nouvelle clause WHERE ne le peut :
WHERE telephone = '012345%' AND email = 'dupont@ibm.com'
Il faut des index complémentaires avec des clefs inversées !
telephone email skype CLEF D INDEX
------------- --------- ------- ------------------------------------------
X8 2 1 (email, telephone)
X9 2 1 (skype, telephone)
X10 2 1 (skype, email)
X11 1 3 2 (telephone, skype, email)
X12 2 1 3 (email, telephone, skype)
X13 2 3 1 (skype, telephone, email)
X14 3 1 2 (email, skype, telephone)
X15 3 2 1 (skype, email, telephone)
Le volume théorique des index est alors le suivant :
X1 : 20 X8 : 276 X2 : 256 X9 : 148 X3 : 128 X10 : 384 X4 : 276 X11 à X15 : 404 X5 : 148 X6 : 384 X7 : 404
TOTAL indexation base monotable : 4 444 octets (+ 404 octets de ligne).
Indexation base multi tabulaire : X1 sur table Contact_TEL (telephone) =: 20 X2 sur table Contact_MEL (email) =: 256 X3 sur table Contact_SKP (skype) =: 128 TOTA indexation base multitable : 404 (+ 420 octets)
Différence de volume des deux bases : 4848 / 824 = 5,88. Autrement dit la base monotabulaire serait près de 6 fois plus grosse que la base multitabulaire ! Comme il y a moins de chance que le plan soit optimal (voir ci après), cela conduit à des balayages de tables ou dindex plus fréquent, ce qui prends plus de place en cache Au détriment dautres données (le cache nétant pas élastique ! car cest la RAM )
En ce qui concerne les mises à jour et compte tenu des verrous à poser, dans la base monotabulaire, toute mise à jour dune seul information, bloque le ligne de la table. Plus personne ne peut accéder aux autres rubriques. Dans la base multitabulaire, la mise à jour dune information ne bloque pas les autres rubrique pour la même personne. La base multitabulaire est donc 3 fois plus fluide statistiquement que la base monotabulaire
Confronté à un choix dindex, loptimiseur doit décider lequel prendre. Plus il y en a, et plus le travail est complexe, ardu et prends du temps. Comme les optimiseurs ont un temps impartis pour calculer le meilleur plan il est possible que, devant la combinatoire, le temps impartit soit écoulé avant que le plan optimal soit trouvé Conséquence, plus il y a dindex en général et sur une même table en particulier dans toute la base, et plus il y a de chance que le plan de requête soit finalement moins bon !
Enfin, pour les SGBDR qui savent travailler en parallèle, laccès aux données sur plusieurs tables et souvent plus rapide, car fait en parallèle, que sur une seule table plus grosse plus longue, plus grande !!!
La compacité des données
Les SGBDR stockent leur données dans des pages qui font une certaine taille. Pour SQL Server comme pour PostGreSQL, cette taille est de 8 Ko.
Le principe est quune ligne dune table doit impérativement tenir intégralement dans une page. Il nest donc pas possible de dépasser une certains taille de ligne qui est de 8060 octets dans SQL Server et 8136 dans PostGreSQL. Si vous construisez une table avec une taille de ligne moyenne de 4500 octets, alors vous naurez jamais plus dune ligne par page et perdrez par conséquent plus de 3500 octets qui seront inutilisés. De plus votre table sera vu comme fragmentée de plus de 40%, et son volume augmente de 40% ! Bref, là encore les performances vont chuter. A savoir qu'il est possible de contourner ce problème en utilisant des champs de type blob qui seront stockées à un autre emplacement.
Dans une base de données relationnelle bien modélisée on trouve de très nombreuses petites tables dépassant rarement la dizaine de colonnes (hors clef étrangères). Les performances restent stables quelque soit le volume des données, car loptimiseur trouvera toujours un index dont le but est faire passer le coût daccès de linéaire à logarithmique.
Dans une base ayant des tables obèses, laccès aux données se fait essentiellement par balayage. Les index sont rarement utilisés. Tant que les tables peuvent être mise en cache dans la RAM, les temps daccès semblent corrects. Dès que la volumétrie des tables dépasse la quantité de RAM, les performances chutent drastiquement et les temps de réponse senvolent.
Dans une base mal modélisée, le résultat est une consommation anormale de RAM du fait de la structure de la table et de nombreux balayage (peu dutilisation dindex). Dans un tel cas, la solution consiste à avoir une RAM sur le serveur égal à la taille de la base ou bien de restructurer la base !
Le problème est que restructurer la base nécessite une refonte complète du développement, si les développeurs nont pas prévu au départ dutiliser des
vues Bref, pour ne pas avoir respecter lart de la modélisation des données, les performances deviendront tôt ou tard un cauchemar !
réf: Base de données et performances
petites tables et tables obèses ! | Le blog de SQLpro
https://blog.developpez.com/sqlpro/p10070/langage-sql-norme/base_de_donnees_et_performances_petites
2.11. Gestion de base de donnée
Lister les index de table
Voici une petite requête qui va nous permettre de lister les colonnes de tous les index dune table bien précise de notre base de Données. En effet, ce bout de code à garder à proximité, va nous permettre de savoir si on a un index sur telle ou telle colonne de notre table pour ainsi optimiser les temps de chargement.
SELECT Tab.name TABLE_NAME,
Idx.name INDEX_NAME,
Col.name COLUMN_NAME,
'PRIMARY_KEY' = CASE Idx.is_primary_key WHEN '0' THEN '0' ELSE '-1' END,
'UNIQUE' = CASE Idx.is_unique WHEN '0' THEN '0' ELSE '-1' END
FROM sys.tables Tab
INNER JOIN sys.indexes Idx ON Tab.object_id = Idx.object_id
INNER JOIN sys.index_columns IdxCol ON IdxCol.object_id = Idx.object_id AND IdxCol.index_id = Idx.index_id
INNER JOIN sys.columns Col ON Col.object_id = IdxCol.object_id AND Col.column_id = IdxCol.column_id
WHERE Tab.type_desc = 'USER_TABLE'
AND Idx.is_primary_key = 0
--AND Tab.name = 'MA_TABLE_NAME'
ORDER BY TABLE_NAME, INDEX_NAME,COLUMN_NAME
Le résultat de cette requête :
- Nom de la table
- Le nom de lindex
- Nom de la colonne sur laquelle existe lindex
- Sagit-il dune clé primaire ?
- index unique ou non ?
réf: SQL Server - Afficher les index d'une table ou d'une base SQL Server
https://3click-solutions.com/fr/afficher-index-table/
Afficher l'espace de données utilisé par chaque table
Voice 2 requettes pour SQLServer permettant de connaitre l'espace utilisé par chacunes des tables :
SELECT
t.object_id,
OBJECT_NAME(t.object_id) ObjectName,
SUM(u.total_pages) * 8 Total_Reserved_kb,
SUM(u.used_pages) * 8 Used_Space_kb,
u.type_desc,
MAX(p.rows) RowsCount
FROM
sys.allocation_units u
JOIN sys.partitions p ON u.container_id = p.hobt_id
JOIN sys.tables t ON p.object_id = t.object_id
GROUP BY
t.object_id,
OBJECT_NAME(t.object_id),
u.type_desc
ORDER BY
Used_Space_kb DESC,
ObjectName;
SELECT s.Name + '.' + t.NAME AS TableName, p.rows AS RowCounts,
SUM(a.total_pages) * 8 AS TotalSpaceKB, SUM(a.used_pages) * 8 AS UsedSpaceKB,
(SUM(a.total_pages) - SUM(a.used_pages)) * 8 AS UnusedSpaceKB
FROM sys.tables t
INNER JOIN sys.indexes i ON t.OBJECT_ID = i.object_id
INNER JOIN sys.partitions p ON i.object_id = p.OBJECT_ID AND i.index_id = p.index_id
INNER JOIN sys.allocation_units a ON p.partition_id = a.container_id
LEFT OUTER JOIN sys.schemas s ON t.schema_id = s.schema_id
WHERE t.NAME NOT LIKE 'dt%' AND t.is_ms_shipped = 0 AND i.OBJECT_ID > 255
GROUP BY t.Name, s.Name, p.Rows
ORDER BY UsedSpaceKB DESC
Clés étrangères
Cette requête répertorie toutes les relations de clé étrangère dans la base de données actuelle.
SELECT
FK_SCHEMA = CU.TABLE_SCHEMA,
FK_Table = FK.TABLE_NAME,
FK_Column = CU.COLUMN_NAME,
Pk_Schema = PK.TABLE_SCHEMA,
PK_Table = PK.TABLE_NAME,
PK_Column = PT.COLUMN_NAME,
Constraint_Name = C.CONSTRAINT_NAME
FROM
INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS C
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS FK
ON C.CONSTRAINT_NAME = FK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS PK
ON C.UNIQUE_CONSTRAINT_NAME = PK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE CU
ON C.CONSTRAINT_NAME = CU.CONSTRAINT_NAME
INNER JOIN (
SELECT
i1.TABLE_NAME,
i2.COLUMN_NAME
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS i1
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE i2
ON i1.CONSTRAINT_NAME = i2.CONSTRAINT_NAME
WHERE
i1.CONSTRAINT_TYPE = 'PRIMARY KEY'
) PT
ON PT.TABLE_NAME = PK.TABLE_NAME
WHERE (PK.TABLE_NAME = 'AMC') --OR (FK.TABLE_NAME = 'AMC')
--C.CONSTRAINT_NAME = 'FK__PatientSu__idStr__5986F3E2'
ORDER BY FK_Table, FK_Column, PK_Table, PK_Column
Avec SMSS il est facile de visualiser les dépendances d'une table. Pour cela faites un click droit sur la table et choisissez "Afficher les dépendances".
Pour lister l'arbre des dépendances a une table
DECLARE @TableName VARCHAR(80) = 'actSPO'
DECLARE @n INT,@n2 INT, @id INT, @id2 INT
DECLARE @Schema NVARCHAR(50), @Schema2 NVARCHAR(50), @TABLE VARCHAR(50), @Table2 VARCHAR(50)
SELECT
ROW_NUMBER() OVER (ORDER BY PK.TABLE_NAME) AS ID,
FK_SCHEMA = CU.TABLE_SCHEMA,
FK_Table = FK.TABLE_NAME,
--FK_Column = CU.COLUMN_NAME,
Pk_Schema = PK.TABLE_SCHEMA,
PK_Table = PK.TABLE_NAME,
PK_Column = PT.COLUMN_NAME
--Constraint_Name = C.CONSTRAINT_NAME
INTO #FK
FROM
INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS C
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS FK
ON C.CONSTRAINT_NAME = FK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS PK
ON C.UNIQUE_CONSTRAINT_NAME = PK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE CU
ON C.CONSTRAINT_NAME = CU.CONSTRAINT_NAME
INNER JOIN (
SELECT
i1.TABLE_NAME,
i2.COLUMN_NAME
FROM
INFORMATION_SCHEMA.TABLE_CONSTRAINTS i1
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE i2
ON i1.CONSTRAINT_NAME = i2.CONSTRAINT_NAME
WHERE
i1.CONSTRAINT_TYPE = 'PRIMARY KEY'
) PT
ON PT.TABLE_NAME = PK.TABLE_NAME
WHERE (PK.TABLE_NAME <> FK.TABLE_NAME)
-- creation de la table
CREATE TABLE #FKdest
(ID INTEGER NOT NULL PRIMARY KEY,
parentId INTEGER,
TableSchema VARCHAR(80),
TableName VARCHAR(80))
SET @n=1
SET @id=0
WHILE @n > 0
BEGIN
-- niveau 1
SELECT TOP 1 @id=id, @Schema=FK_SCHEMA, @TABLE=FK_TABLE FROM #FK WHERE id >=@id AND (PK_Table = @TableName)
SET @n=@@ROWCOUNT
IF 0 = (SELECT COUNT(1) FROM #FKdest WHERE TableSchema = @Schema AND TableName = @TABLE)
INSERT INTO #FKdest VALUES (@id, 0, @Schema, @TABLE)
-- niveau 2
IF 0 < (SELECT COUNT(1) FROM #FK WHERE PK_Schema = @Schema AND PK_Table = @TABLE)
BEGIN
SET @n2=1
SET @id2=0
WHILE @n2 > 0
BEGIN
SET @n2 = 0
IF 0 < (SELECT COUNT(*) FROM #FK WHERE id >=@id2 AND (PK_Table = @TABLE))
BEGIN
SELECT TOP 1 @id2=id, @Schema2=FK_SCHEMA, @Table2=FK_TABLE FROM #FK WHERE id >=@id2 AND (PK_Table = @TABLE)
SET @n2=@@ROWCOUNT
IF 0 = (SELECT COUNT(1) FROM #FKdest WHERE (TableSchema = @Schema2 AND TableName = @Table2) OR id=@id2 )
INSERT INTO #FKdest VALUES (@id2, @id, @Schema2, @Table2)
-- niveau 3
IF 0 < (SELECT COUNT(1) FROM #FK WHERE PK_Schema = @Schema2 AND PK_Table = @Table2)
IF 0 = (SELECT COUNT(1) FROM #FKdest INNER JOIN #FK ON #FK.id = #FKdest.ID
WHERE TableSchema = #FK.FK_Schema AND TableName = #FK.FK_TABLE AND #FK.PK_Schema = @Schema2 AND #FK.PK_Table = @Table2)
BEGIN
INSERT INTO #FKdest SELECT id, @id2, FK_Schema, FK_TABLE FROM #FK WHERE PK_Schema = @Schema2 AND PK_Table = @Table2
END
END
SET @id2+= 1
END
END
/*
IF 0 < (SELECT count(1) FROM #FK WHERE PK_Schema = @Schema AND PK_Table = @Table)
IF 0 = (SELECT count(1) FROM #FKdest inner join #FK on #FK.id = #FKdest.ID
WHERE TableSchema = #FK.FK_Schema and TableName = #FK.FK_TABLE and #FK.PK_Schema = @Schema and #FK.PK_Table = @Table)
BEGIN
INSERT INTO #FKdest SELECT id, @id, FK_Schema, FK_TABLE FROM #FK WHERE PK_Schema = @Schema AND PK_Table = @Table
-- niveau 3
END
*/
SET @id+= 1
END
SELECT * FROM #FKdest ORDER BY id
DROP TABLE #FKdest
DROP TABLE #FK
Pour renommer une clé étrangère
SET @GeneratedFKLikeName = 'FK__PatientSu__idUse%'
SET @NewFKName = 'FK__PatientSu__idUse__67D51339'
SET @ColumnFK = 'idUserDoctor'
SELECT TOP 1 @GeneratedFKLikeName = CU.TABLE_SCHEMA + '.' + C.CONSTRAINT_NAME
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS C
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS FK
ON C.CONSTRAINT_NAME = FK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS PK
ON C.UNIQUE_CONSTRAINT_NAME = PK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE CU
ON C.CONSTRAINT_NAME = CU.CONSTRAINT_NAME
INNER JOIN (
SELECT i1.TABLE_NAME, i2.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS i1
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE i2
ON i1.CONSTRAINT_NAME = i2.CONSTRAINT_NAME
WHERE i1.CONSTRAINT_TYPE = 'PRIMARY KEY'
) PT ON PT.TABLE_NAME = PK.TABLE_NAME
WHERE --(PK.TABLE_NAME = 'AMC') OR (FK.TABLE_NAME = 'AMC')
C.CONSTRAINT_NAME LIKE @GeneratedFKLikeName
AND ((@ColumnFK IS NULL) OR (CU.COLUMN_NAME = @ColumnFK))
EXEC sp_rename @GeneratedFKLikeName ,@NewFKName;
Connexion depuis un autre ordinateur a votre base SQL Server
Allez dans le Gestionnaire de configuration SQL Server, développez SQL
Server Configuration réseau, puis cliquez sur Protocoles pour
Pour vous connecter à cette instance à partir d'un autre ordinateur, vous devez ouvrir un port de communication dans le pare-feu. Linstance par défaut du moteur de base de données écoute sur le port 1433 ; Par conséquent, vous navez pas besoin de configurer un port fixe.
Dans le menu Démarrer , cliquez sur Exécuter, tapez WF.msc, puis cliquez sur OK. Dans le Pare-feu Windows avec fonctions avancées de sécurité, dans le volet gauche, cliquez avec le bouton droit sur Règles de trafic entrant, puis sélectionnez Nouvelle règle dans le volet Action.
Dans la boîte de dialogue Type de règle , sélectionnez Port, puis cliquez sur Suivant.
Dans la boîte de dialogue Protocoles et ports , sélectionnez TCP. Sélectionnez Ports locaux spécifiques, puis tapez le numéro de port de linstance du moteur de base de données. Tapez 1433 pour l'instance par défaut.
Sur un deuxième ordinateur qui contient les outils clients SQL Server ouvrez
Management Studio, et dans la zone Nom du serveur , tapez
tcp:
Important
- Si vous omettez tcp: dans la zone Nom du serveur , le client essaiera tous les protocoles activés, dans l'ordre spécifié dans sa configuration.
- Si une tentative est effectuée pour établir une connexion avec le nom dinstance lors de la connexion au serveur distant, le service SQL Server Browser doit être en cours dexécution sur le serveur distant. Le mappage de port de nom dinstance ne fonctionne pas si le service SQL Server Browser nest pas en cours dexécution.
Copier une base vers une version antérieur de SQL Server
Avec SQL Server Management Studio (SSMS) nous allons pouvoir copier entièrement une base de donnée vers une autre quelque soit la version de SQL Server. Ou alors copier le scructure complète d'une base (de production par exemple) et la remplir avec des données d'une base de développement.
1) Générer des scripts à partir de la base à copier; un pour la structure, un pour les vues, et un pour la programmabilité
Ouvrir SSMS et se connecter sur l'instance ou se trouve la base à copier Faire un click droit sur la base, Taches, Générer des scripts Sélectionner Tables, Utilisateurs, Rôles, Schémas, et Types de tables Aller dans Avancé, sélectionner
- Générer un script de création/suppression (DROP/CREATE)
- Générer un script d'utilisation de la base de données (USE DATABASE) Ã False
- Générer un script pour la version du serveur: SQL Serveur 2012
- Inclure des noms de contraintes système à True
- Vérifier l'existence de l'objet à False
Options de Table/vue
Générer un script pour les déclencheurs
Générer un script pour les index
Faire un script également pour les vues et pour tous ce qui est programmabilité. Vérifier dans les scripts qu'il n'y ai aucune références au nom de base.
2) Création de la base de destination à minima
Ouvrir SSMS et se connecter sur l'instance ou on veux copier la base Créer une nouvelle base Reprendre le script qui a été généré pour les tables. Dans le script, enlever et mettre de coté, la partie concernant la création des clés étrangères à la fin du script, puis passer le script sur la nouvelle base.
3) Exportation des données
Faire un click droit sur la base, Taches, Exporter des données Utilisation de SQL SERVER NATIVE CLIENT 11, sélectionner votre serveur source Prochaine étape, sélectionnez votre nouveau serveur de destination
Désélectionner toutes les vues Sélectionner tous les élément restant et cliquer sur Modifier les mappages. Cocher "Activer l'insertion d'identité" Si certaines tables ne passent pas, faire précédent et désélectionner la table.
ex: Errors_Log_SPI
4) Sur la nouvelle base de donnée, passer le script pour les clé étrangères, puis pour les vues et pour les procédures (éventuellement repasser les vues).
Si il y a des erreur avec les clé étrangère c'est que l'exportation a échoué et que toutes les tables n'ont pas été exportés, à cause d'une erreur. Reprendre à l'étape 2.
Si il y a une ou plusieurs erreurs avec le script de procédure stockées, il faut les corriger.
- Modifier la définition des valeur par defaut des paramètres d'entrée des PRC ex : @idExtern int null par @idExtern int ex : @idExtern INT NULL = 0 par @idExtern INT = 0
- Modifier la fonction TRIM (SQL2017) avec RTRIM(LTRIM( ))
- Modifier STRING_AGG (SQL2017)
- Modifier les index sur les variable de table
declare @activeDoctors table ( id int, name varchar(100), --SQL2012 UNIQUE NONCLUSTERED (id) --index idx_nom (id) );
https://stackoverflow.com/questions/886050/creating-an-index-on-a-table-variable
réf:
https://askcodez.com/possible-de-restaurer-une-sauvegarde-de-sql-server-2014-sur-sql-server-2012.html
réf:
https://askcodez.com/comment-les-valeurs-null-affecter-les-performances-dune-base-de-donnees-de-recherche.html
Pour afficher les tables contenant une référence à la table
SELECT DISTINCT FK.TABLE_SCHEMA + '.' + FK.TABLE_NAME, CU.COLUMN_NAME
FROM INFORMATION_SCHEMA.REFERENTIAL_CONSTRAINTS C
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS FK
ON C.CONSTRAINT_NAME = FK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.TABLE_CONSTRAINTS PK
ON C.UNIQUE_CONSTRAINT_NAME = PK.CONSTRAINT_NAME
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE CU
ON C.CONSTRAINT_NAME = CU.CONSTRAINT_NAME
INNER JOIN (
SELECT i1.TABLE_NAME, i2.COLUMN_NAME
FROM INFORMATION_SCHEMA.TABLE_CONSTRAINTS i1
INNER JOIN INFORMATION_SCHEMA.KEY_COLUMN_USAGE i2
ON i1.CONSTRAINT_NAME = i2.CONSTRAINT_NAME
WHERE i1.CONSTRAINT_TYPE = 'PRIMARY KEY'
) PT ON PT.TABLE_NAME = PK.TABLE_NAME
WHERE PK.TABLE_NAME = 'ActCategory' AND FK.TABLE_NAME <> 'ActCategory'
Trouver les requettes les plus gourmandes en CPU
Si vous voulez trouver les 'n' requêtes les plus importantes qui sont actuellement dans le cache et qui consomment le plus de CPU, alors vous êtes au bon endroit.
La DMV sys.dm_exec_query_stats contient toutes les informations sur les requêtes consommatrices de ressources (CPU, mémoire, I/O) qui sont actuellement dans le cache.
Nous pouvons simplement joindre la DMV ci-dessus avec sys. dm_exec_query_plan et ensuite avec sys. dm_exec_sql_text pour obtenir les plans de requête et le texte SQL qui est en cours d'exécution.
Voici la requête qui donne le TOP 10 des requêtes qui sont actuellement dans le cache et qui consomment le plus de CPU :
;WITH eqs
AS (
SELECT
[execution_count]
,[total_worker_time]/1000 AS [TotalCPUTime_ms]
,[total_elapsed_time]/1000 AS [TotalDuration_ms]
,query_hash
,plan_handle
,[sql_handle]
FROM sys.dm_exec_query_stats
)
SELECT TOP 10 est.[text], eqp.query_plan AS SQLStatement
,eqs.*
FROM eqs
OUTER APPLY sys.dm_exec_query_plan(eqs.plan_handle) eqp
OUTER APPLY sys.dm_exec_sql_text(eqs.sql_handle) AS est
ORDER BY [TotalCPUTime_ms] DESC
réf:
https://sqlmaestros.com/script-find-top-10-cpu-intensive-queries/
CHAPITRE 3 - Architecture
3.1. Architecture avec une base synchronisé en lecture seule
Si tu es bien en « synchronous commit » voici le schema dexecution
Du coup la transaction est aussi présente sur le nud 2 (et 3) en même temps que sur le 1.
Donc je ne comprends pas trop pourquoi vous avez une latence ?
3.2. Architecture de la réplication
Larchitecture de la réplication SQL Server, repose sur les différentes techniques qui permettent de copier et de distribuer les données des différents objets dune base de données vers une autre.
SQL Server propose trois types de réplication :
- La réplication transactionnelle (Transactional Replication).
- La réplication de capture instantanée (Snapshot Replication).
- La réplication par fusion (Merge Replication).
A titre d'information, la réplication ne concerne pas la duplication de base de données. Si vous voulez dupliquer toute la base de donnée en entier, vous allez choisir plutôt log shipping ou miroir de base de données.
La réplication transactionnelle est généralement utilisée dans un environnement serveur à serveur pour répondre aux besoins suivants :
Redondance des données sur un ou plusieurs serveurs qui se trouvent sur le même site ou sur des sites différents.
Utilisation du serveur abonné comme un serveur de reporting et de lecture seule.
Consolidation des données sur un serveur central en provenance de plusieurs sites distants.
Besoin davoir un serveur abonné mis à jour en quasi temps réel avec le serveur de publication.
La volumétrie et lactivité de la base est très importante, dans ce cas la réplication par capture instantanée peut prendre longtemps et verrouille à chaque fois laccès aux données sur la base de publication.
Réplication vers un serveur non-SQL Server, comme Oracle ou Sybase.
Principe de fonctionnement :
La réplication transactionnelle commence en général par une capture instantanée des objets et des données de la base à publier.
Une fois la première capture effectuée, toutes les modifications effectuées sur les schémas et les données de la base de publication sont transmis au fur et à mesure (presque en temps réel) aux différents abonnés.
Les changements et les transactions produites sur le serveur de publication sont appliqués dans le même ordre sur les abonnés, donc la cohérence des données est garantie par le mécanisme de la réplication.
Schéma darchitecture dune réplication transactionnelle :
.gif)
La réplication transactionnelle est effectuée par différents agents :
- Agent de capture instantanée (snapshot)
- Agent de lecture du journal de transaction
- Agent de distribution.
Lagent de capture instantanée (snapshot) :
- Génère un snapshot (ensemble de fichiers) contenant les schémas et les données des objets de la base à publier (tables, vues, fonctions, procédures, ).
- Les fichiers générés sont déposés dans un répertoire partagé (répertoire snapshot) accessible par tous les serveurs qui participent à la réplication (serveur de publication, serveur de distribution et les différents abonnés).
- Enregistre les informations de synchronisation dans la base de distribution qui se trouve sur le serveur de distribution ou sur le serveur de publication si celui-ci joue les deux rôles à la fois.
- Bref, cest lui qui génère la copie des données qui sera utilisée pour initialiser la base à mettre en réplication sur les différents abonnés.
- Le job de lagent est planifié en « one shot » car il est utilisé uniquement pour linitialisation ou pour la réinitialisation des données.
Lagent de lecture du journal :
- Surveille le journal des transactions de la base publiée (lactivité de la base sur le serveur de publication), et copie les transactions qui doivent être répliquées depuis le journal des transactions dans la base de distribution.
- La base de distribution joue donc le rôle dune file dattente (stockage et distribution des transactions).
- Le job de lagent de lecture du journal tourne sans arrêt sur le serveur de publication. Si le job est arrêté, la réplication des données sarrête.
Lagent de distribution :
- Se charge de la copie des données de la capture instantanée (le snapshot dinitialisation) et les différentes transactions stockées au fur et à mesure dans la base de distribution vers les abonnés.
- Le job de cet agent tourne sans arrêt comme lagent de lecture du journal. Si le job est arrêté, la réplication sarrête aussi.
- Le job de lagent peut être configuré sur le serveur de distribution (publication/distribution si le serveur de publication joue les deux rôles) ou sur labonné selon le mode de configuration de la réplication (push ou pull).
Mise en place dune réplication transactionnelle : Pré-requis :
- Le module de réplication doit être installé sur tous les serveurs qui participent à la réplication (publication, distribution et les abonnés). SQL Server dispose dune procédure qui permet de le vérifier facilement (sp_MS_replication_installed).
- Deux comptes de service (Active Directory) : un compte pour le service SQL Server Agent et lautre pour le fonctionnement de la réplication (il est déconseillé dutiliser le même compte).
- Création dun partage pour la capture instantanée (snapshot).
- Droits de lecture/écriture sur le partage et les droits NFS sur le dossier à partager pour le compte de service SQL Agent.
- Le rôle serveur « sysadmin » pour le compte de service.
Création de la réplication
Pour un nouveau serveur, il faut configurer la distribution. Configurer la distribution consiste à choisir est ce l'éditeur lui même, l'éditeur ici c'est le serveur qui contient la donnée, ou vous voulez qu'un autre serveur puisse jouer le rôle du distributeur. Le distributeur c'est un serveur qui contient la base de donnée, dite distribution. Cette base de donnée distribution elle contient la configuration de la réplication; quels sont les différents abonné, quelle mode est utilisé par abonnés, comme par exemple pull, ça veut dire que l'abonné, c'est lui qui vat venir chercher l'information de chez l'éditeur, ou le contraire en mode push, ça veut dire que l'information vat être envoyé de l'éditeur vers l'abonné. Quand comment avec quelle sécurité. Ces informations de configuration sont stockées dans une base qui s'appelle distribution.
- Connectez-vous au serveur de distribution, au serveur de publication ou à labonné dans Management Studio, puis développez le nud du serveur.
- Sur le serveur de distribution, dans "Réplication", "Publication locales", click droit, "Configurer la distribution"
L'assistant de configuration demande ou vous voulez stocker cette distribution. Si votre serveur éditeur est assez sollicité, il est recommandé que cette base de donnée distribution soit installé sur un autre serveur (une autre instance) sur votre réseaux. Ensuite l'assistant demande le chemin ou on vat créer les snapshot. Ici on choisit plutôt un répertoire partagé sur le réseaux, parce que peut être il y aura des abonnés qui vont aller puiser dans le dossier de snapshot, c'est le mode pull. Saisir le chemin du dossier réseaux dans le champ "Dossier d'instantanées". Ensuite l'assistant crée la base système distribution sur votre serveur de distribution. Pour annuler cette configuration, click droit
sur Réplication, "Désactiver la publication et la distribution"
Après on doit créer notre publication, c'est à dire le choix des articles que l'on veux dupliquer sur les autres abonnés.
- Sur le serveur de publication, dans "Réplication", "Nouvelle réplication"
- Choisir la base de donnée de publication, c'est a dire celle qui doit contenir les articles.
- Choisir le type de publication, par exemple transactionnelle, ce qui veut dire que s'il y a une modification sur le serveur A, envoi la transaction qui a modifié la donnée sur éditeur vers l'abonné.
Tous les types de publication ont besoin d'une première capture instantanée (snapshop). Le snapshot est utilisé pour rendre la donnée disponible pour le deuxième serveur, l'abonné.
- Choir les tables, quel article vous voulez, seules les tables avec une clé primaire sont sélectionnable. La réplication transactionnelle utilise les clefs les ligne pour pouvoir identifier les modifications. S'il n'y a pas de clefs
- Choisir le compte qui aura accès au dossier partagé du snapshot. Lancer services.msc pour voir quel compte tourne l'Agent SQLServer, et si il a les droits accès au dossier. Sinon il est possible de créer un compte spécifique. Le compte doit posséder un mot de passe et avoir le droit "sysadmin" au niveau des bases de données.
- Nommer la publication, par exemple Pub_Trans_TestPerf_Categorie
Une foie la création de la publication on vat choisir l'abonné.
- Sur le serveur de publication, dans "Réplication", sélectionner dans Publication locale, la publication créé. Faire une click droit, nouveaux abonnements
- Choisir entre Pull et Push
- Ajouter des abonnés serveur et base, ou créer une nouvelle base de donnée. Le nom d'instance des abonnés doit contenir le nom du serveur, si ce n'est pas le cas il faudra renommer le nom de l'instance.
- Planifier la synchronisation: en continue, manuel, ou avec une planification.
Pour renommer le nom de l'instance SQLServer:
-- Donne le nom actuel de l'instance
SELECT @@servername
GO
-- Supprime l'ancien nom des tables système
sp_dropserver 'NOM Actuelle lue par la requête ci-dessus'
GO
-- Ajoute le nouveau nom dans les tables système
sp_addserver 'NOUVEAU NOM DE LINSTANCE', LOCAL
GO
-- Vérification de la prise en compte du nouveau nom
SELECT * FROM sys.servers WHERE server_id = 0
GO
-- Vérification de la prise en compte du nouveau nom - prise 2
sp_helpserver
GO
-- REDÉMARRER L'INSTANCE POUR PRENDRE EN COMPTE CE NOUVEAU PARAMÈTRE
-- Vérification que c'est bien effectif
SELECT @@SERVERNAME
GO
Pour vérifier que tout fonctionne bien
- Sur le serveur de publication, dans "Réplication", sélectionner dans Publication locale, la publication créé, et l'abonné. Click droit, "Lancer le moniteur de réplication"
réf:
https://easyteam.fr/la-replication-transactionnelle-sql-server-1/
https://easyteam.fr/replication-transactionnelle-sql-server-2/
https://easyteam.fr/replication-transactionnelle-sql-server-3/
https://easyteam.fr/suppression-dune-replication-transactionnelle-sql-server/
réf:
réf:
https://learn.microsoft.com/fr-fr/previous-versions/sql/sql-server-2008-r2/ms151706(v=sql.105
)?redirectedfrom=MSDN
réf:
https://www.youtube.com/watch?v=hPftwLU7fXk
3.3. Transfer de journaux
L'objectif c'est d'avoir dans un autre serveur la même base de donnée, cela permet dans le cas ou le serveur principal plante, d'avoir une base de donnée déjà prête, sur un deuxième serveur pour orienter les applications sur ce deuxième serveur. Cette base de donnée doit être synchrone ou presque synchrone par rapport à la première base. Donc il faut mettre à jour au fur et à mesure les données sur le deuxième serveur. L'idée c'est de sauvegarder le journal, du moment que toutes les transactions y passent, puis de transférer le point TRN (qui est la sauvegarde de ce journal) sur le deuxième serveur puis de le restaurer.
- Taches, Envoyer les journaux de transaction
- Cocher Activer en tant que base de donnée primaire dans une configuration de la copie des journaux de transactions
- Paramètres de sauvegarde, choisir un dossier partagé pour la sauvegarde, et indique le chemin local. Comme on veux déplacer la sauvegarde du dossier partagé du serveur 1 vers le dossier partagé du serveur 2 toutes les 5 min au paramètre la conservation des sauvegarde à 5h au lieu de 72h, et une alerte au bout de 15 min sans sauvegarde. On paramètre la planification toutes les 5 min.
- Dans base de donnée secondaire, ajouter le deuxième serveur
- Dans le menu demarrer Outils de configuration, Configuration de la surface d'exposition SQL Server
réf:
https://www.youtube.com/watch?v=5zz_GB9jfwE
https://www.youtube.com/watch?v=6e5SU2bOuvE
https://www.youtube.com/watch?v=F_GOzKIUG-A
3.4. Architecture du Miroir
réf:
132 millisecondes