
________ _______ __ __ _______ ________
| | | | | | | | | \ | |
| __ | |___ / | | | | | __ | | _____|
| |__| | / / | | | | | |__| _| | |___
| __ | / /_ | |__| | | __ \ | ___|_
| | | | / | | | | | | | | |
|__| |__| |_______| |________| |__| |__| |________|
DevOps avec Azure
azure.md 25/12/2023
ultimecool.com
Sommaire
CHAPITRE 1 - Azure
1.1. Introduction à DevOps
1.2. DevOps avec Azure : Infrastructure as Code (IaC) avec Azure ARM
1.3. Créer et déployer des ressources avec Visual Studio et ARM
1.4. ARM Template CI & CD avec VSTS
1.5. Stratégie de CI & CD pour linfrastructure et le Code, 1re approche
1.6. Stratégie de CI & CD pour l'infrastructure et le Code, approche 2
1.7. Extension « Continuous Delivery Tools for Visual Studio »
1.8. L'outil « App Service Continuous Delivery »
1.9. Azure DevOps Projects
1.10. Azure Application Insights et configuration
1.11. Tests fonctionnels avec DevOps
1.12. Tests de charge et de performance avec Azure DevOps - Load Tests
1.13. Architectures micro-services
CHAPITRE 2 - Azure Functions
2.1. Introduction à Azure Functions
2.2. Première fonction Azure
2.3. Les triggers et les liaisons
2.4. Développer des fonctions Azure
CHAPITRE 1 - Azure
1.1. Introduction à DevOps
Lagilité permet de gagner en robustesse et qualité. Cependant, les équipes projets ne sont pas en mesure de livrer rapidement les applications. Le principal goulot détranglement est la barrière qui existe entre les développeurs et les chargés dopération. Les développeurs veulent déployer en production rapidement, et ceci à moindre cout. De leur côté, les chargés de linfrastructure veulent maintenir létat et la stabilité du système. Dun côté, la livraison rapide peut se faire au détriment de la qualité, ce qui impacte la stabilité du système, alors que de lautre côté, les contraintes imposées par les chargés dopération se font au détriment des coûts et du temps. Le concept du DevOps sappuie sur lagilité et la démarche "Lean" pour offrir plusieurs méthodes permettant une meilleure cohésion entre lensemble des équipes du système dinformation, favorisant ainsi latteinte dun objectif commun : livrer rapidement une solution fiable et robuste. « Les équipes du système dinformation » fait référence à la fois aux développeurs, aux chargés dinfrastructures et toute autre personne pouvant intervenir dans la chaîne de livraison. Ce qui nest pas le cas avec lagilité, qui nintègre pas les chargés dopération dans les équipes agiles. DevOps repose sur 5 piliers: CALMS (Culture Automation, Lean, Measurement, Sharing).
1.2. DevOps avec Azure : Infrastructure as Code (IaC) avec Azure ARM
Dans un projet DevOps, les problèmes liés au crash de serveurs de développement, ne peuvent jamais se produire. DevOps propose de bonnes pratiques de gestion de la configuration via lautomatisation. Toute mise à jour dun environnement, toute application dun correctif de sécurité, toute installation dun patch, ... doivent se faire via des scripts. Aucune intervention manuelle nest requise. En scriptant la configuration dun environnement, on dispose de lhistorique des opérations qui ont été effectuées. Les scripts peuvent directement faire office de documentation. Lorsquon parle de gestion de la configuration dans une démarche DevOps, cela fait référence à 2 pratiques: Infrastructure as Code et Configuration as Code.
Infrastructure as Code (IaS)
Linfrastructure pour exécuter une application est un ensemble de ressources : machines virtuelles, espace de stockage, gestionnaire de base de données, etc. La création et la configuration de ces ressources sont définies dans des fichiers de script. A lexécution de ces fichiers, on obtient une infrastructure complète, prête à être utilisée pour le déploiement et lexécution de notre application. Le recours à des scripts va permettre de créer assez facilement autant denvironnements que besoin (dev, test, etc.), avec des états identiques. En effet, chaque fois que le script sera exécuté, le même environnement sera créé.
La définition et la configuration des ressources étant définies dans des fichiers de script, il devient assez aisé dintroduire ceux-ci dans un pipeline dintégration et de livraison continue. Avant le déploiement de lapplication, les scripts dautomatisation sont exécutés pour configurer et provisionner les ressources sur lesquelles lapplication sera déployée.
Si vous avez besoin dune nouvelle ressource plus tard, il suffira de modifier le script et introduire cette nouvelle ressource. Lors du déploiement, la plateforme dintégration et livraison continue va détecter un changement dans la définition de linfrastructure et exécutera le script qui permettra le provisionnement de la nouvelle ressource.
En procédant ainsi, votre infrastructure évoluera avec votre application, et vous disposerez en tout temps le code de lapplication et le script de configuration de linfrastructure dans létat quil faut pour exécuter lapplication.
Il existe sur le marché de nombreuses solutions pour aider les équipes à mettre en place des infrastructures programmables. On peut citer en autres Vagrant, Ansible, Puppet, Docker, Chef, Dell Cloud Manager, etc. Dans les prochaines parties, nous allons voir concrètement comment scripter son infrastructure en utilisant Azure Resource Manager(ARM).
Description dARM
Azure Resource Manager est la solution offerte par la plateforme Cloud Azure pour la création, le provisionnement, la modification et la suppression des ressources. ARM utilise une approche déclarative pour la gestion de linfrastructure. En effet, les caractéristiques des ressources que vous souhaitez utiliser (disque dur, mémoire vive, etc. ) doivent être définies dans un fichier au format JSON. ARM se chargera dinterpréter ce fichier et déployer les ressources qui correspondent dans Azure.
Pour exploiter efficacement ARM, vous devez savoir à quoi renvoient les termes Resource, Resource Group, Resource Providers et ARM Template.
Qu'est-ce quune ressource ?
Sur Azure, une ressource fait référence à un item qui est disponible dans la plateforme Cloud et qui est géré par lutilisateur. Une ressource peut être une machine virtuelle, une base de données, un compte de stockage, un load balancer, etc.
À quoi renvoie un groupe de ressources (Resource group) ?
Le déploiement dune application dans Azure peut nécessiter le recours à plusieurs ressources : machine virtuelle, base de données, compte de stockage, etc. Lensemble de ces ressources représente linfrastructure nécessaire au
fonctionnement de votre application. Celle-ci doit évoluer suivant les besoins de lapplication.
Pour faciliter la gestion de ces ressources, Microsoft offre les « resource group ». Il sagit dun conteneur pour toutes les ressources dune solution. En créant vos groupes de ressources, ayez à lesprit que toutes les ressources dans le même resource group doivent avoir le même cycle de vie. De ce fait, elles sont déployées, mises à jour et supprimées ensemble.
Resource Providers
Dans votre Resource Group, les ressources sont créées et gérées par un Resource Provider (fournisseur de ressource). Chaque Resource Provider fournit des ressources et des outils permettant dexploiter les services dAzure.
Les Resource Providers sont accessibles à travers une couche de gestion cohérente, pouvant être utilisée par de nombreux outils pour exploiter la plateforme Azure. Que vous utilisez Azure PowerShell, le portail Azure, Azure CLI, etc. vous aurez accès au même ensemble dopérations.
ARM Template
Comme je lai souligné plus haut, ARM utilise lapproche déclarative. Les caractéristiques des ressources qui seront déployées dans un resource group, ainsi que leurs dépendances sont définies dans des fichiers au format JSON (JavaScript Object Notation). Ces fichiers représentent les ARM templates.
Le code JSON ci-dessous est un exemple de template ARM :
"resources": [
{
"apiVersion": "2016-01-01",
"type": "Microsoft.Storage/storageAccounts",
"name": "mystorageaccount",
"location": "westus",
"sku": {
"name": "Standard_LRS"
},
"kind": "Storage",
"properties": {
}
}
]
Lorsque ARM reçoit un tel code, il linterprète et transforme son contenu en des opérations REST pouvant être utilisées par chaque Resource Provider pour créer et configurer la ressource quil faut.
Dans la prochaine partie, nous allons créer et déployer notre infrastructure sur Azure en utilisant ARM et Visual Studio.
1.3. Créer et déployer des ressources avec Visual Studio et ARM
Pour créer vos templates Azure, vous devez au préalable installer le kit de développement (SDK) Azure pour Visual Studio. Dans les exemples qui vont suivre, je vais utiliser Visual Studio 2017. Jai simplement installé lEDI en sélectionnant la charge de travail Développement Azure. Nous allons créer un projet ARM qui permettra de déployer les ressources nécessaires pour lhébergement dune application Web sur Azure.
Ouvrez Visual Studio et créez un nouveau projet en sélectionnant le modèle Azure Resource Group (dans Visual C#, Cloud, ou dans Azure sur la version 2019). Pour le nom du projet vous pouvez mettre par exemple « AzResourceWeb ».
Dans la fenêtre contenant la liste des templates, vous devez sélectionner « Blank Template » :
Il faut noter quil existe de nombreux templates préconfigurés avec un ensemble de ressources permettant de répondre à un besoin précis : création et configuration des ressources pour Service Fabric, Jenkins, Azure Web App, etc. Ceux-ci ont été mis en place avec la participation de la communauté, car il est possible de créer et publier son template ARM sur GitHub pour en faire profiter les utilisateurs qui pourraient avoir les mêmes besoins.
Dans la fenêtre de sélection dun template dans Visual Studio, si vous déroulez la zone « Show templates from this location » et vous choisissez « Azure QuickStart », vous aurez une liste de près de 588 templates.
Une fois le projet créé en utilisant le template « Blank Template », vous aurez les Fichiers suivants dans votre explorateur de solution :
« azuredeploy.json » contient la définition de linfrastructure qui sera déployée, ainsi que les paramètres que vous devez définir lors du déploiement. Il contient également les dépendances entre les différentes ressources de votre infrastructure. Ainsi, Azure sera en mesure de déployer vos ressources dans lordre quil faut;
« azuredeploy.parameters.json » contient les paramètres qui seront utilisés par le template;
« Deploy-AzureResourceGroup.ps » est le script PowerShell utilisé pour le déploiement de linfrastructure sur Azure.
Création des ressources
Ouvrir le fichier "azuredeploy.json". A gauche de Visual Studio, l'explorateur JSON apparait. Il va permettre dajouter les nouvelles ressources avec les configurations nécessaires dans le fichier JSON azuredeploy.json, sans avoir besoin déditer ce dernier à la main. Lutilisation dune interface pour le faire est assez pratique, puisque vous navez pas besoin davoir une parfaite maitrise de JSON. Pour ajouter une nouvelle ressource, faire un clic droit sur « resource », puis sur « Add New Resource ».
Dans la fenêtre qui va safficher, sélectionnez Web app, nom « WebAppTest », puis dans la liste déroulante, sélectionnez « Create new ». Compte tenu du fait quune Web App a besoin dun Service Plan, une seconde fenêtre va safficher permettant de créer cette ressource. Le lien sera établi entre les deux. De ce fait, le Service Plan sera créé et déployé avant la ressource Web App. Donnez le nom du Service Plan « ServicePlanTest » et cliquez sur Add.
Vous allez revenir sur la fenêtre de création de la Web App. Vous allez remarquer la présence de deux ressources dans lexplorateur de solutio. Des paramètres et des variables ont été également ajoutés pour celles-ci. En sélectionnant une ressource, la portion de code correspondante dans le fichier JSON est mise en évidence.
Déploiement de la ressource dans Azure
Pour déployer générer le projet. Puis dans lexplorateur de solution, faire un clic droit et cliquer sur Deploy, ensuite sur New.
Dans la fenêtre qui va safficher, sélectionnez votre suscription Azure, ou connectez-vous à votre compte Microsoft si ce nest pas le cas. Vous allez sélectionner dans la liste déroulante du groupe de ressources, et choisir Create New. Une interface va safficher permettant de définir le nom du groupe de ressources, ainsi que lemplacement :
Ceci fait, vous allez cliquer sur le bouton Edit Parameters pour donner un nom à
votre Service Plan ensuite cliquer sur Deploy. La fenêtre de sortie de Visual Studio va afficher les différentes actions en cours, avant de vous afficher le résultat du déploiement. Une fois connecté au portail Azure, vous verrez la nouvelle ressource qui a été créée.
1.4. ARM Template CI & CD avec VSTS
Nous verrons comment mettre en place un pipeline dIntégration et livraison continues en utilisant Visual Studio Team Service (VSTS). Créer un nouveau projet « Azure Resource Group » en utilisant le modèle « Web App ». Puis éditer le fichier WebSite.parameters.json pour définir le nom du HostingPlan :
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentParameters.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"hostingPlanName": {
"value": "HostPlan"
}
}
}
Ajout du gestionnaire de versions
Créer un nouveau projet déquipe sur VSTS, en utilisant Git comme gestionnaire de versions. Une fois le projet déquipe créé, vous aurez une page avec les instructions pour ajouter un repository à votre projet.
Vous allez dérouler la section «Push an existing repository from command line», puis copier les commandes qui seront affichées, et les exécuter en invite de commande dans le dossier racine de votre projet :
git remote add origin https://hinault.visualstidio.com/DefaultCollection/_git/AzResource
git push -u origin --all
Création de la Build Definition
Nous allons maintenant créer une Build Definition dans VSTS pour notre projet. La Build definition est un ensemble de tâches qui va permettre notamment de charger les sources du projet, restaurer les dépendances, générer le projet, exécuter les tests unitaires et enfin produire une sortie (un package de publication) qui pourra être déployée dans lenvironnement dexécution.
Pour notre cas, la sortie sera les fichiers json et PowerShell qui seront tilisés par lAPI ARM Template pour déployer notre infrastructure dans Azure. Nous aurons donc besoin dune tâche pour copier ces fichiers dans le dossier Staging sur le serveur VSTS et dune seconde tâche pour publier lartefact dans VSTS, afin que ces fichiers soient visibles pour la Release Definition, qui pourra les utiliser pour le déploiement.
Pour créer la définition de Build, vous devez cliquer dans le menu sur Build and Release, puis sur le bouton New definition :
Vérifiez que le bon repositorie a été sélectionné, puis cliquez sur Continue.
Sources: This account, Team project: AzRessource, Repository: AzRessourceWeb, Branch: master
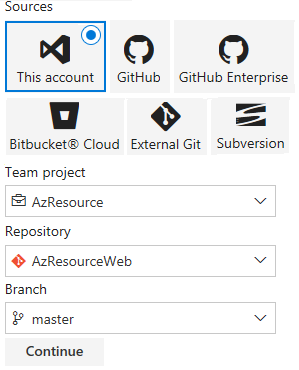
Dans la fenêtre de sélection du Template qui va safficher, sélectionnez Empty. Vous allez donner un nom à la Build Definition (AzResource-CI). Longlet Tasks sera affiché avec un Agent Phase ayant pour nom Phase 1. Vous allez laisser les informations par défaut, et ajouter juste les tâches dont nous avons besoin. Pour le faire, cliquez sur le « + » dans la zone Phase 1 à gauche. Puis, dans la fenêtre qui va safficher à droite, saisissez le filtre « copy files », puis sélectionnez la tâche « Copy Files », puis cliquez sur Add.
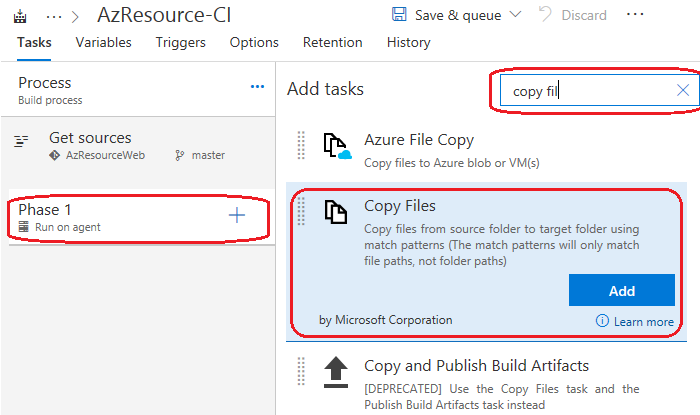
Toujours dans la même fenêtre, changez le filtre par « Publish » et sélectionner la tâche « Publish Build Artifacts ».
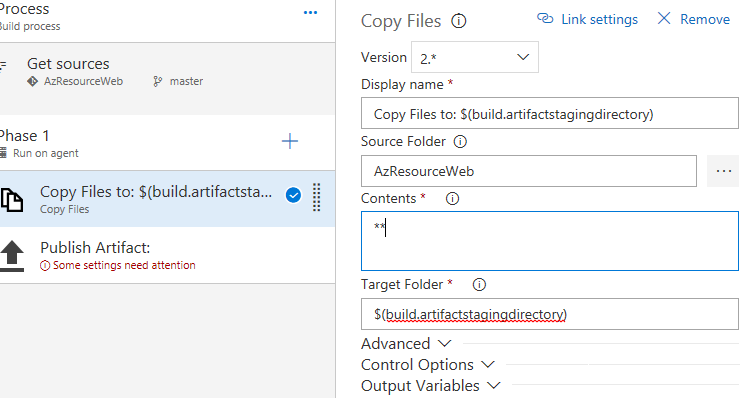
Sélectionner la tâche Copy Files. Dans la fenêtre qui va safficher à droite, renseignez le répertoire source. Cliquer sur le bouton « », puis sélectionner le répertoire dans lequel se trouvent les fichiers du projet (AzResourceWeb). Vous devez saisir « $(build.artifactstagingdirectory) », dans le champ « Target Folder » (répertoire de destination). Il s'agit d'une variable utilisée par VSTS qui permet de spécifier le répertoire, dans lequel seront déposés les fichiers à publier.
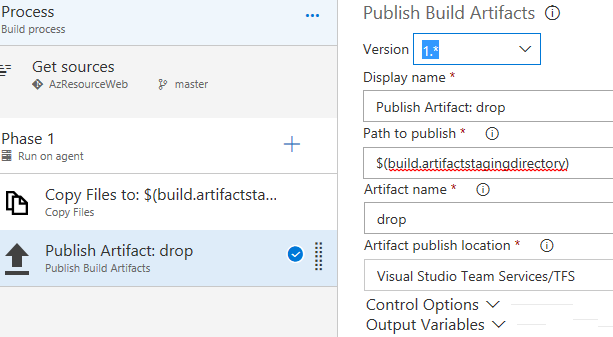
Cela fait, cliquez sur la tâche « Publish Artifact ». Dans le champ « Path to publish », saisissez $(build.artifactstagingdirectory). Il sagit du répertoire dans lequel les fichiers à publier ont été copiés. Dans le champ « Artifact name », vous allez saisir « drop ». Dans le champ « Artifact publish location », Dérouler la liste déroulante et choisir « Visual Studio Team Services/TFS ».
Sur longlet « Triggers », cocher la case « Enable Continuous integration ». Cette opération va permettre de lancer la buid, à chaque commit dune modification de code :
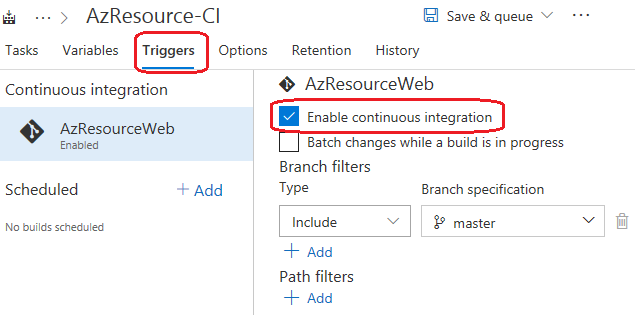
Cliquez enfin sur « Save & queue » pour enregistrer et démarrer une build, qui vous permettra de valider que tout est correct.
Création de la Release Definition
La Release Definition qui permettra de déployer notre projet dans Azure pour créer ou mettre à jour linfrastructure correspondante. Cliquez sur Releases dans le menu Build and Release, puis sur le bouton New definition :
Dans la liste des templates qui va safficher, sélectionnez Empty process. Dans la fenêtre Environment, vous allez donner comme nom Dev à votre environnement et puis fermer cette fenêtre. Vous aurez affiché à lécran longlet Pipeline.
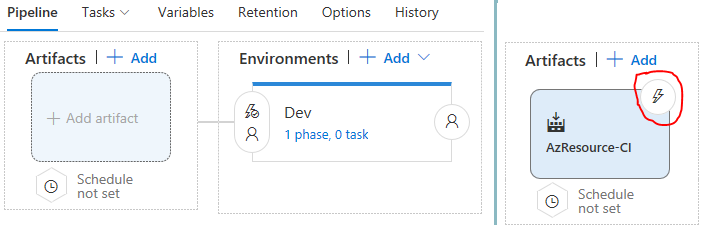
Nous avons précédemment défini notre environnement de déploiement. Nous devons maintenant définir lArtefact qui sera utilisé. Il sagit du résultat qui sera produit par lopération de Build. Cliquer sur Add artifact. Dans la fenêtre qui va safficher, vous allez sélectionnez Build comme Source, ensuite sélectionner votre Build definition (AzResource-CI) dans la zone Source, puis cliquer sur Add
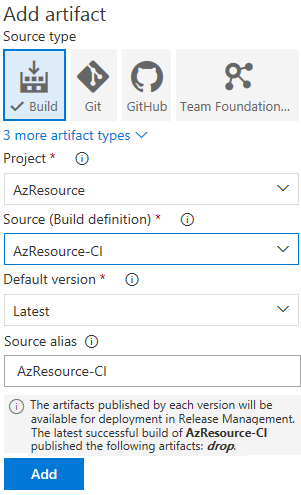
Lartefact publié par chaque version sera disponible pour le déploiement dans la gestion des versions. La dernière construction réussie de AzResource-CI a publié lartefact suivant: drop
Un bouton avec un éclair va safficher sur lArtefact nouvellement créé. Il permet dactiver le déploiement continu. C'est à dire que chaque fois quune opération de Build seffectuera avec succès, le processus de déploiement de cette version du code se lancera automatiquement.
Pour mettre en place le déploiement continu, vous devez donc cliquer sur ce bouton, ensuite activer la fonctionnalité. Une fois cela fait, vous devez aller dans longlet Tasks, puis cliquer sur le bouton « + » dans la zone « Agent Phase ». Dans la fenêtre dajout des tâches qui va safficher, saisissez « Azure Resource » dans le champ de recherche, puis sélectionnez la tâche « Azure Resource Group Deployment » et cliquez sur Add :
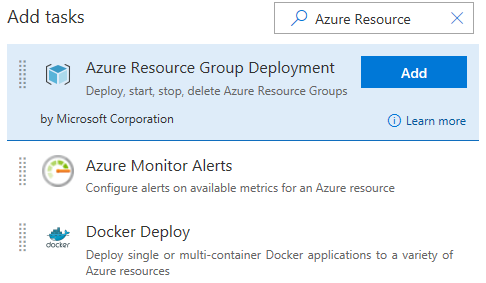
Une fois la tâche ajoutée, cliquez sur cette dernière et renseignez les champs suivants :
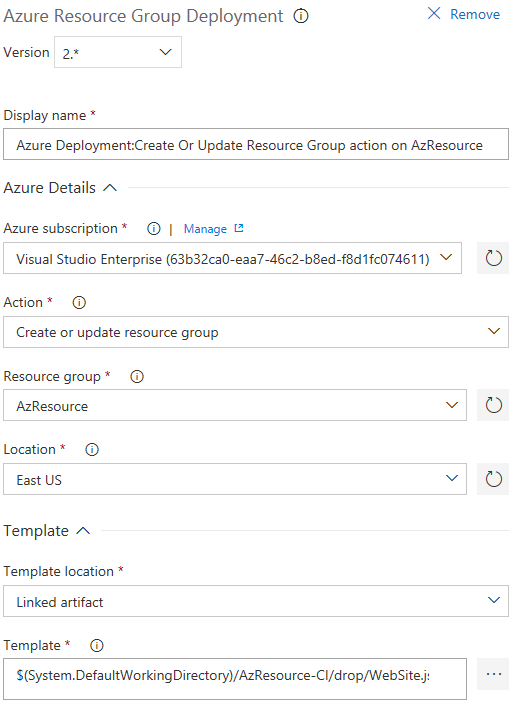
Azure subscription : votre suscription Azure devrait safficher par défaut dans la liste, si vous avez déjà configuré un Endpoint. Sinon, vous devez cliquer sur le bouton « Manage » pour vous rendre dans linterface de gestion des services et ajouter un nouveau endpoint « Azure Resource Manager Service ». Pour plus de détails, vous pouvez consulter larticle suivant :
Action : cliquez sur le champ et sélectionnez dans la liste déroulante « Create or update resource group ».
Resource group : donnez le nom qui sera utilisé dans Azure pour le groupe de ressource.
Location : sélectionnez lemplacement ou votre infrastructure sera déployée.
Template location : sélectionnez « Linked artifact ». Ce choix va vous permettre de définir lemplacement du fichier ARM template qui sera utilisé pour le déploiement.
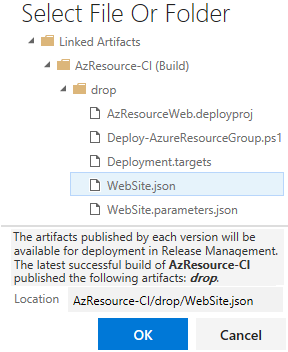
Template : vous devez renseigner le chemin vers le fichier WebSite. json. Pour cela, il suffit de cliquer sur « », ensuite sélectionner le répertoire de publication de la Build (drop) et le fichier WebSite.json :
Template parameters : vous devez renseigner le chemin vers le fichier WebSite.parameters.json. Pour le faire, vous devez procéder de même que ci-dessus.
Vous pouvez laisser les valeurs par défaut pour les autres options :
Enregistrez les modifications.
Pour tester que le déploiement se fait correctement, vous pouvez créer une nouvelle release. Il suffit de cliquer sur le bouton Release, puis Create Release. Dans la fenêtre qui va safficher, sélectionnez lenvironnement Dev, puis lartefact qui a été généré par notre dernière build, puis cliquez sur Create.
Lorsque la Release sera créée, vous pourrez cliquer sur le nom de celle-ci dans le message de confirmation pour afficher la fenêtre de gestion de cette release. Vous pouvez ainsi dans les logs voir si le déploiement cest effectué correctement.
Si cest le cas, vous devez voir votre Resources Group, ainsi que les services qui ont été définis dans le template ARM dans le portail Azure :
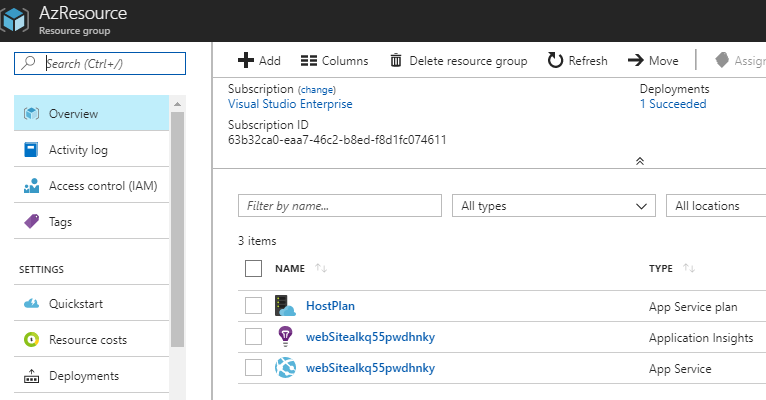
Nous disposons désormais dun pipeline dIntégration et de Livraison continues
pour notre projet ARM template. Chaque fois que notre infrastructure aura besoin dune mise à jour, il nous suffira dapporter les modifications dans le projet Azure ARM Template et ensuite procéder à un commit des changements pour que notre infrastructure soit mise à jour.
Pour vérifier cela, nous allons mettre à jour notre template ARM dans Visual Studio, en y ajoutant un compte de stockage Azure :
{
"$schema": "https://schema.management.azure.com/schemas/2015-01-01/deploymentTemplate.json#",
"contentVersion": "1.0.0.0",
"parameters": {
"hostingPlanName": {
"type": "string",
"minLength": 1
},
"skuName": {
"type": "string",
"defaultValue": "F1",
"allowedValues": [
"F1",
"D1",
"B1",
"B2",
"B3",
"S1",
"S2",
"S3",
"P1",
"P2",
"P3",
"P4"
],
"metadata": {
"description": "Describes plan's pricing tier and capacity. Check details at https://azure.microsoft.com/en-us/pricing/details/app-service/"
}
},
"skuCapacity": {
"type": "int",
"defaultValue": 1,
"minValue": 1,
"metadata": {
"description": "Describes plan's instance count"
}
},
"StaticFilesStorageType": {
"type": "string",
"defaultValue": "Standard_LRS",
"allowedValues": [
"Standard_LRS",
"Standard_ZRS",
"Standard_GRS",
"Standard_RAGRS",
"Premium_LRS"
]
}
},
"variables": {
"webSiteName": "[concat('webSite', uniqueString(resourceGroup().id))]",
"StaticFilesStorageName": "staticfilesstorage44"
},
"resources": [
{
"apiVersion": "2015-08-01",
"name": "[parameters('hostingPlanName')]",
"type": "Microsoft.Web/serverfarms",
"location": "[resourceGroup().location]",
"tags": {
"displayName": "HostingPlan"
},
"sku": {
"name": "[parameters('skuName')]",
"capacity": "[parameters('skuCapacity')]"
},
"properties": {
"name": "[parameters('hostingPlanName')]"
}
},
{
"apiVersion": "2015-08-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Web/sites",
"location": "[resourceGroup().location]",
"tags": {
"[concat('hidden-related:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
"displayName": "Website"
},
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"properties": {
"name": "[variables('webSiteName')]",
"serverFarmId": "[resourceId('Microsoft.Web/serverfarms', parameters('hostingPlanName'))]"
}
},
{
"apiVersion": "2014-04-01",
"name": "[concat(parameters('hostingPlanName'), '-', resourceGroup().name)]",
"type": "Microsoft.Insights/autoscalesettings",
"location": "[resourceGroup().location]",
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
"displayName": "AutoScaleSettings"
},
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"properties": {
"profiles": [
{
"name": "Default",
"capacity": {
"minimum": 1,
"maximum": 2,
"default": 1
},
"rules": [
{
"metricTrigger": {
"metricName": "CpuPercentage",
"metricResourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]",
"timeGrain": "PT1M",
"statistic": "Average",
"timeWindow": "PT10M",
"timeAggregation": "Average",
"operator": "GreaterThan",
"threshold": 80.0
},
"scaleAction": {
"direction": "Increase",
"type": "ChangeCount",
"value": 1,
"cooldown": "PT10M"
}
},
{
"metricTrigger": {
"metricName": "CpuPercentage",
"metricResourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]",
"statistic": "Average",
"timeWindow": "PT1H",
"timeAggregation": "Average",
"operator": "LessThan",
"threshold": 60.0
},
"scaleAction": {
"direction": "Decrease",
"type": "ChangeCount",
"value": 1,
"cooldown": "PT1H"
}
}
]
}
],
"enabled": false,
"name": "[concat(parameters('hostingPlanName'), '-', resourceGroup().name)]",
"targetResourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
}
},
{
"apiVersion": "2014-04-01",
"name": "[concat('ServerErrors ', variables('webSiteName'))]",
"type": "Microsoft.Insights/alertrules",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Web/sites/', variables('webSiteName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]": "Resource",
"displayName": "ServerErrorsAlertRule"
},
"properties": {
"name": "[concat('ServerErrors ', variables('webSiteName'))]",
"description": "[concat(variables('webSiteName'), ' has some server errors, status code 5xx.')]",
"isEnabled": false,
"condition": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.ThresholdRuleCondition",
"dataSource": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleMetricDataSource",
"resourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]",
"metricName": "Http5xx"
},
"operator": "GreaterThan",
"threshold": 0.0,
"windowSize": "PT5M"
},
"action": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleEmailAction",
"sendToServiceOwners": true,
"customEmails": []
}
}
},
{
"apiVersion": "2014-04-01",
"name": "[concat('ForbiddenRequests ', variables('webSiteName'))]",
"type": "Microsoft.Insights/alertrules",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Web/sites/', variables('webSiteName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]": "Resource",
"displayName": "ForbiddenRequestsAlertRule"
},
"properties": {
"name": "[concat('ForbiddenRequests ', variables('webSiteName'))]",
"description": "[concat(variables('webSiteName'), ' has some requests that are forbidden, status code 403.')]",
"isEnabled": false,
"condition": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.ThresholdRuleCondition",
"dataSource": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleMetricDataSource",
"resourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]",
"metricName": "Http403"
},
"operator": "GreaterThan",
"threshold": 0,
"windowSize": "PT5M"
},
"action": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleEmailAction",
"sendToServiceOwners": true,
"customEmails": []
}
}
},
{
"apiVersion": "2014-04-01",
"name": "[concat('CPUHigh ', parameters('hostingPlanName'))]",
"type": "Microsoft.Insights/alertrules",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
},
"properties": {
"name": "[concat('CPUHigh ', parameters('hostingPlanName'))]",
"description": "[concat('The average CPU is high across all the instances of ', parameters('hostingPlanName'))]",
"isEnabled": false,
"condition": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.ThresholdRuleCondition",
"dataSource": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleMetricDataSource",
"resourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]",
"metricName": "CpuPercentage"
},
"operator": "GreaterThan",
"threshold": 90,
"windowSize": "PT15M"
},
"action": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleEmailAction",
"sendToServiceOwners": true,
"customEmails": []
}
}
},
{
"apiVersion": "2014-04-01",
"name": "[concat('LongHttpQueue ', parameters('hostingPlanName'))]",
"type": "Microsoft.Insights/alertrules",
"location": "[resourceGroup().location]",
"dependsOn": [
"[resourceId('Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]": "Resource",
"displayName": "LongHttpQueueAlertRule"
},
"properties": {
"name": "[concat('LongHttpQueue ', parameters('hostingPlanName'))]",
"description": "[concat('The HTTP queue for the instances of ', parameters('hostingPlanName'), ' has a large number of pending requests.')]",
"isEnabled": false,
"condition": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.ThresholdRuleCondition",
"dataSource": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleMetricDataSource",
"resourceUri": "[concat(resourceGroup().id, '/providers/Microsoft.Web/serverfarms/', parameters('hostingPlanName'))]",
"metricName": "HttpQueueLength"
},
"operator": "GreaterThan",
"threshold": 100.0,
"windowSize": "PT5M"
},
"action": {
"odata.type": "Microsoft.Azure.Management.Insights.Models.RuleEmailAction",
"sendToServiceOwners": true,
"customEmails": []
}
}
},
{
"apiVersion": "2014-04-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Insights/components",
"location": "East US",
"dependsOn": [
"[resourceId('Microsoft.Web/sites/', variables('webSiteName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]": "Resource",
"displayName": "AppInsightsComponent"
},
"properties": {
"applicationId": "[variables('webSiteName')]"
}
},
{
"name": "[variables('StaticFilesStorageName')]",
"type": "Microsoft.Storage/storageAccounts",
"location": "[resourceGroup().location]",
"apiVersion": "2016-01-01",
"sku": {
"name": "[parameters('StaticFilesStorageType')]"
},
"dependsOn": [ ],
"tags": {
"displayName": "StaticFilesStorage"
},
"kind": "Storage"
}
]
}
Application de l'ARM template
Puis pousser nos changements sur VSTS. De retour sur VSTS, nous verrons que la Build va démarrer automatiquement. Une fois la Build et la Release effectuées, nous pourrons observer les changements dans Azure :
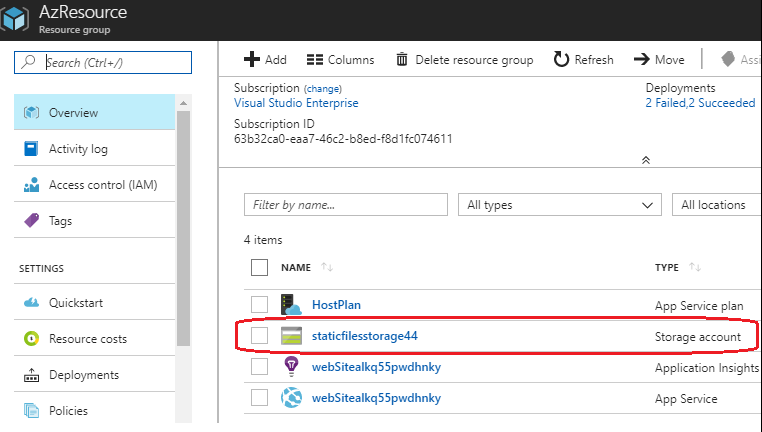
Vous êtes désormais en mesure de mettre en place un pipeline de CI & CD pour déployer un projet Azure ARM sur la plateforme cloud de Microsoft.
1.5. Stratégie de CI & CD pour linfrastructure et le Code, 1re approche
Lun des objectifs dune infrastructure programmable est de permettre de versionner linfrastructure et utiliser le même repository que le code source de lapplication. Ainsi, lapplication et son infrastructure pourront évoluer conjointement.
Nous allons intégrer lapplication à notre repository et voir comment mettre en place une stratégie de CI & CD pour le code de lapplication et les scripts de linfrastructure.
Ajouter une nouvelle application ASP.NET MVC Core à notre solution (c#, .NETCore « Application web ASP.NET Core ». Une fois la nouvelle application ajoutée, nous allons pousser nos changements sur notre repository distant. Nous allons maintenant procéder à la création du pipeline de CI & CD pour notre application.
Choix dune stratégie de CI & CD pour linfrastructure et le Code
Vous devez décider de comment les déploiements vont seffectuer pour le code et linfrastructure. Je vais présenter deux approches différentes : la première approche va permettre dutiliser le même pipeline de CI et CD pour le code et linfrastructure, tandis que la seconde approche va permettre de mettre en place des pipelines séparés. Chaque approche à ses avantages et ses inconvénients.
La 1 ère approche que je vais utiliser, va nous permettre davoir dans une même build definition toutes les tâches pour la génération et la publication du code de linfrastructure ainsi que les tâches pour la génération et la publication de lapplication. Idem en ce qui concerne la release definition.
Lavantage est que lapplication et linfrastructure ont le même cycle de vie. A chaque sauvegarde des changements sur le repository distant, le déploiement de linfrastructure est effectué avant. En cas déchec, le processus névoluera plus et lapplication ne sera pas déployée. Ainsi nous avons une meilleure cohésion entre le code de lapplication et linfrastructure et ces derniers vont partager les mêmes numéros de version et évoluer ensemble.
Dans de nombreux cas, le déploiement des nouveautés de lapplication ne nécessitera aucune mise à jour de linfrastructure. Or, les tâches de génération et de déploiement de linfrastructure sexécuteront à chaque commit du code de l'application et vice-versa. Cela aura pour conséquence un temps de build et de déploiement plus long.
Mise à jour de la Build definition
Accédez à votre Build definition dans VSTS. Vous allez dans un premier temps ajouter une nouvelle variable ayant pour nom BuildConfiguration et pour valeur release :
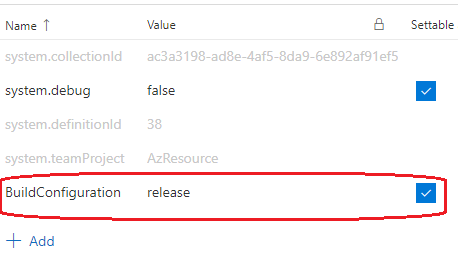
Vous allez ensuite ajouter des tâches pour restaurer les packages NuGet, générer lapplication, exécuter les tests unitaires, publier lapplication et transférer cette dernière dans le répertoire de lartefact.
Tâche pour la restauration des packages NuGet
Vous allez ajouter une tâche .NET Core :
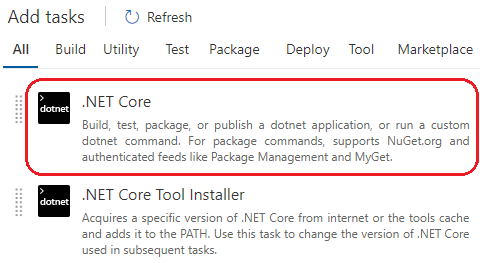
Dans la zone commande, vous allez sélectionner « restore ». Dans le champ « Path to project(s) », vous allez mettre le chemin vers le fichier.csproj. Mettez le chemin suivant « **/*.csproj » afin que la restauration des packages soit faite pour tous les projets de la solution.
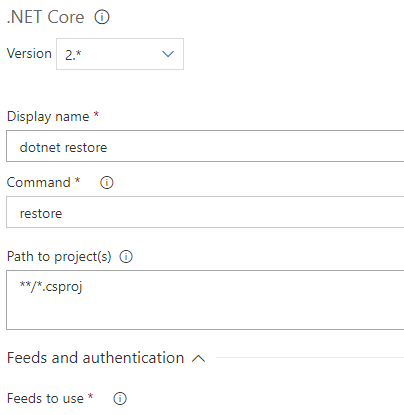
Tâche pour la génération
Ajoutez une 2 ème tâche .NET Core. Sélectionnez la commande Build et renseignez le chemin des fichiers .csproj. Dans la zone Arguments, saisir : « --configuration $(BuildConfiguration) » :
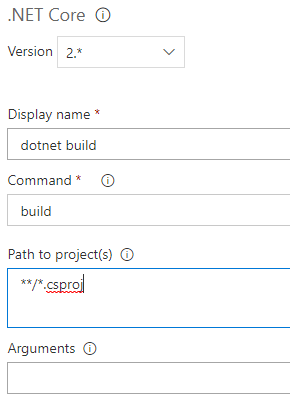
Tâche pour exécuter les tests unitaires
Vous allez ajouter une autre tâche .NET Core à la Build definition. La commande à utiliser sera tests. Dans Path to project(s), vous allez mettre un chemin permettant de rechercher et exécuter tous les projets de tests unitaires dans votre solution. Couramment, les projets de tests unitaires sont dans des dossiers contenant le mot Tests (exemple MonProjet.Tests). Le chemin permettant dexécuter les projets de tests est « **/Tests/.csproj ». Dans le champ Arguments, vous devez saisir « --configuration $(BuildConfiguration)». Noubliez
pas de cocher « Publish test results ».
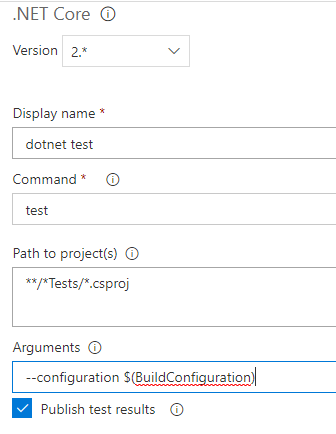
Tâche pour publier lapplication
Ajouter une tache .NET Core pour publier lapplication (publish). Dans le champ Arguments, vous devez saisir « --configuration $(BuildConfiguration) --output $(build.artifactstagingdirectory)». Ces arguments vont être passés à la commande dotnet publish lors de son exécution pour définir la configuration à utiliser et le répertoire de publication du projet.
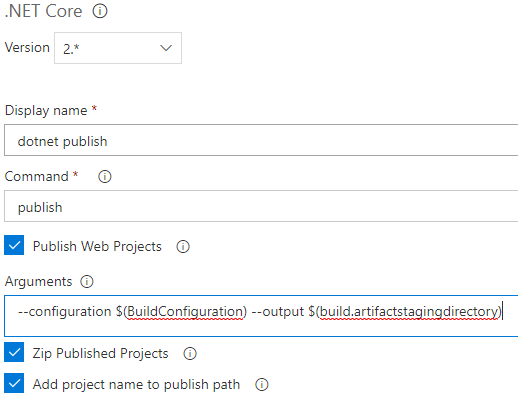
Pour finir, vous devez déplacer la tâche « Publish Build Artifacts » à la fin. Elle doit être la dernière tâche à être exécutée. Les fichiers de déploiement pour linfrastructure et lapplication seront placés dans le dossier Staging. Cette tâche va permettre de les déplacer dans le dossier de lArtefact, afin que les tâches de déploiement puissent accéder à ceux-ci.
Release Definition.
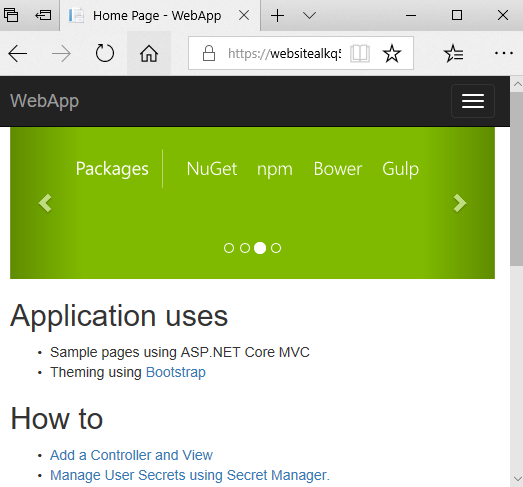
Passons maintenant à la mise à jour de la Release definition pour ajouter la tâche de déploiement de lapplication dans son infrastructure Azure. Lunique tâche dont nous avons besoin est la tâche « Azure App Service Deploy ». Vous devez renseigner votre suscription Azure et le nom de votre Azure App Service. Enregistrez et mettez en file dattente une nouvelle Release pour vous assurer que tout fonctionne correctement. Une fois lapplication déployée, ouvrez le portail Azure, sélectionnez votre App Service et accédez à votre application via ladresse URL obtenue à partir du portail Azure :
1.6. Stratégie de CI & CD pour l'infrastructure et le Code, approche 2
Vu que les modifications de linfrastructure peuvent être moins fréquentes que celles du code, que vous pouvez utiliser un "versioning" différent pour le code et linfrastructure, ou pour toute autre raison, vous pouvez décider dutiliser des pipelines différents pour linfrastructure et le code.
Création de la Build Definition
Ouvrez VSTS dans votre navigateur allez dans Release, puis créez une nouvelle Build Definition en utilisant le template ASP.NET Core :
Il dispose de toutes les tâches nécessaires à la génération et la publication de lapplication : restauration des packages NuGet, génération du projet, exécution des tests unitaires, publication de lapplication et transfert dans le dossier de destination de lartefact.
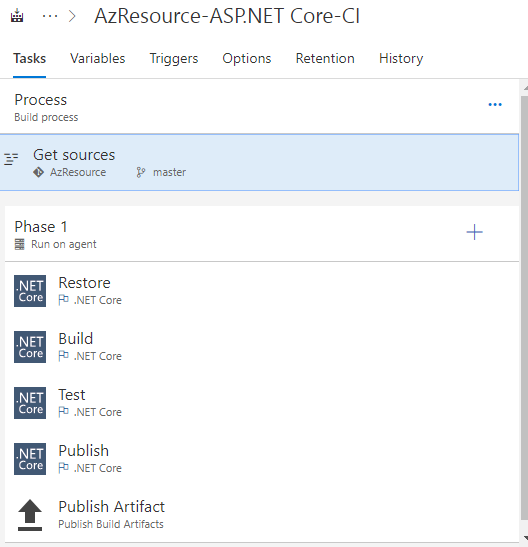
Toutes les tâches ont déjà été configurées comme il se doit. Aucune modification nest nécessaire. Il ne vous reste plus quà activer lintégration continue dans longlet Triggers, puis enregistrer et mettre en file dattente une nouvelle Build, pour vous assurer que tout fonctionne correctement.
Création de la Release Definition.
Passons à létape de création de la Release Definition pour le déploiement de lapplication dans linfrastructure Azure App Service que nous avons créé dans le billet précédent. Allez dans la section Releases, puis ajoutez une nouvelle Release Definition en utilisant le template Azure App Service Deployment.
Vous allez nommer lenvironnement Dev. Ensuite, vous devez ajouter lArtefact en utilisant « AzResource-ASP.NET Core-CI » comme Source. Noubliez pas dactiver le déploiement continu. Il ne vous reste plus quà configurer la tâche de déploiement. Cela se fait dans via longlet Tasks. Vous aurez besoin de renseigner votre suscription Azure et le nom de votre Azure App Service :
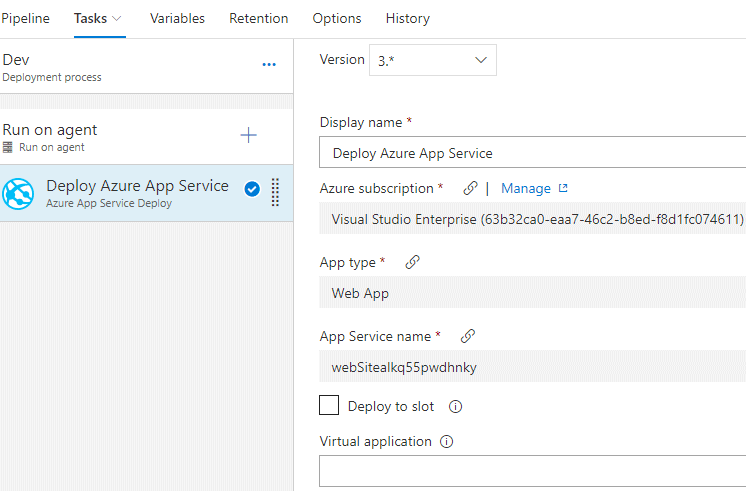
Enregistrez et mettez en file dattente une nouvelle Release pour vous assurer que tout fonctionne correctement. Une fois lapplication déployée, ouvrez le portail Azure, sélectionnez votre App Service et accédez à votre application via ladresse URL obtenue à partir du portail Azure :
Stratégie de CI & CD pour linfrastructure et le Code
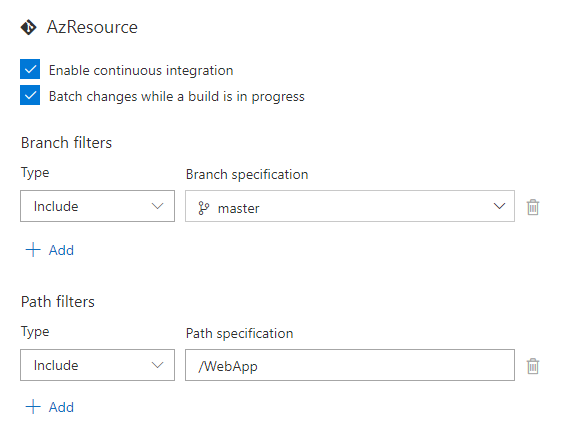
Si vous apportez une modification au code, vous allez constater suite à votre commit que les deux builds vont démarrer. En mettant en place des Builds Definition différentes pour le code et linfrastructure, nous voulions justement que les tâches de build et déploiement de linfrastructure ne sexécutent que lorsque la modification concerne le code de linfrastructure et vice-versa.
Pour remédier à cela, vous allez éditer chaque Build Definition et ajouter un filtre pour ternir uniquement compte des modifications effectuées sur les fichiers dans le dossier de chaque projet :
1.7. Extension « Continuous Delivery Tools for Visual Studio »
Cette extension permet détendre les fonctionnalités de Visual Studio 2017 pour offrir aux développeurs des fonctionnalités DevOps et damélioration de la qualité de code. Elle est disponible uniquement pour les projets ASP.NET et cible uniquement des services Microsoft, dont Azure et VSTS.
Installation de lextension
Aller dans le menu Outils, puis cliquer sur Extensions et Mises à Jour. Ensuite, effectuer une recherche en utilisant les mots « Continuous Delivery Tools ». Ou téléchargez le marketplace.visualstudio.com. Sur VS 2019, c'est dans le menu Extensions.
Mise en place du pipeline de CD & CI pour une application ASP.NET Core
Pour mettre en place un pipeline de CI & CD pour votre application ASP.NET Core, cette dernière doit utiliser un Repository Git. Si ce nest pas le cas, le bouton « Add to Source Control » dans la barre de statut de lextension va vous permettre de rapidement ajouter votre code source au gestionnaire de version Git et pousser vos modifications sur Visual Studio Team Services.
Pour accéder à linterface de CI & CD de votre application, faites un clic droit sur votre solution dans lexplorateur de solution, ensuite cliquez sur « Configure Continuous Delivery to Azure » :
À partir de votre compte Microsoft et VSTS, les informations seront récupérées sur votre abonnement Azure, votre repository et la branche utilisée.
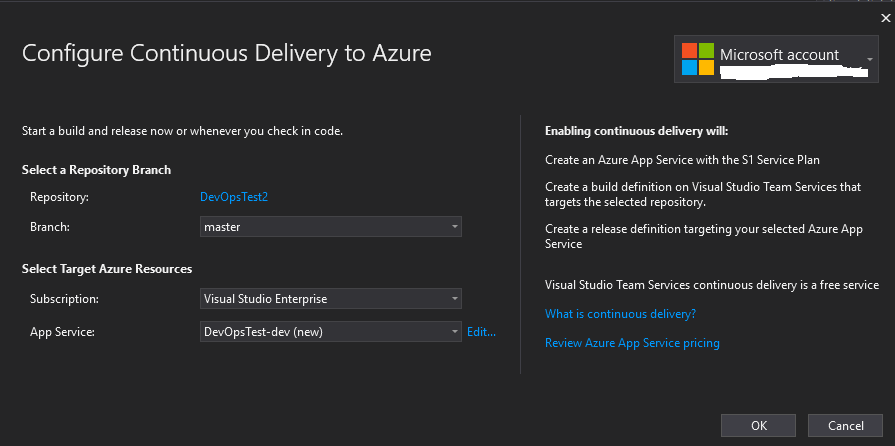
Lextension propose par défaut la création dun nouvel Azure App Service. Si vous avez un App Service existant sur Azure, vous pouvez dérouler et sectionner ce dernier. Vous pouvez cliquer sur Edit pour modifier le nom de lApp Service, la localisation, le nom du groupe de ressources, du Service Plan et la taille du Service Plan. Si tout est correct pour vous, cliquez sur Ok
Lextension va procéder à la création du groupe de ressources et des services nécessaires sur Azure. La Build et la Release definition seront créées sur VSTS. Une nouvelle opération de génération et de déploiement de lapplication sur Azure sera automatiquement lancée. Vous pouvez accéder à votre compte VSTS pour apprécier les configurations qui ont été faites pour vous.
Vous pouvez plus tard personnaliser la configuration qui a été faite en ajoutant des tâches supplémentaires ou des environnements additionnels (staging,prod,etc)
1.8. L'outil « App Service Continuous Delivery »
C'est un outil qui est offert au niveau du portail Azure pour mettre en place rapidement un pipeline robuste de déploiement continue, permettant de builder, exécuter des tests unitaires, exécuter des tests de performance, déployer son application en utilisant les slots de déploiement, etc. Elle permet de déployer des applications .NET Core, Node.js et PHP.
Pour utiliser cette fonctionnalité, vous devez au préalable créer un App Service sur Azure. Votre code source doit être hébergé sur un repository Git distant, privé ou public. Vous pouvez utiliser VSTS, GitHub ou tout autre gestionnaire de version Git.
Pour accéder à la fonctionnalité, sélectionnez simplement votre App Service et vous verrez dans le menu de gauche « Continuous Delivery » :
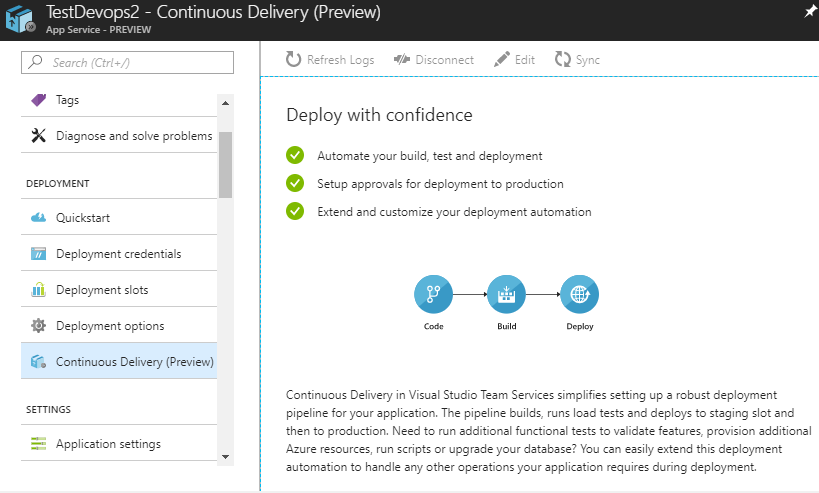
La création dun pipeline de CI&CD avec App Service Continuous Delivery se fait en 4 étapes.
1 Définir lemplacement du code source
La première chose à faire sera de fournir les informations pour récupérer votre code source à partir de votre repository Git :
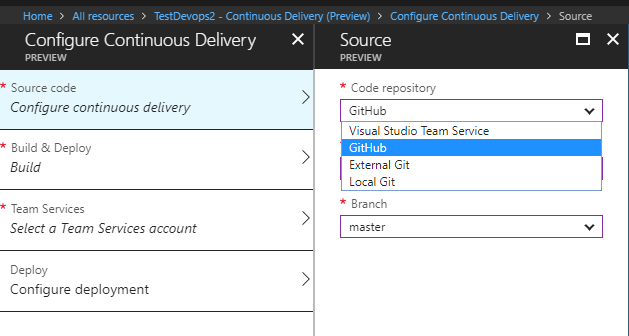
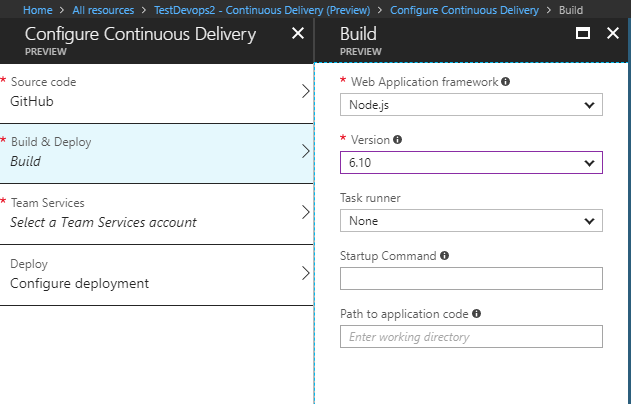
2 Configurer la Build et le déploiement
Vous devez ensuite renseigner les informations qui permettront de configurer correctement la génération et le déploiement. Les tâches à exécuter varient en fonction de la plateforme dexécution de lapplication. Vous devez donc renseigner le framework utilisé (.NET Core, Node.js et PHP) ainsi que la version de ce dernier.
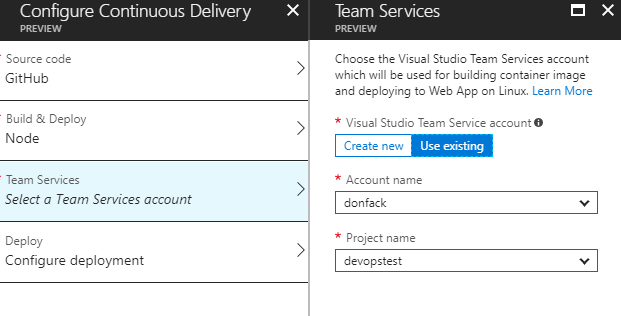
3 Team Services
Comme souligné plus haut, Visual Studio Team Services est utilisé comme serveur de CI&CD. Vous devez donc avoir un compte VSTS avec un projet déquipe existant. Il est également possible de créer un compte VSTS directement à partir de cette interface.
4 Deploiement
La dernière étape est la configuration de comment le déploiement va seffectuer. Vous pouvez choisir dutiliser un slot de déploiement ou non. Si vous utilisez un slot de déploiement, la Release definition sera configurée de telle sorte quà chaque déploiement, la nouvelle version soit dans un premier temps déployée sur le slot Staging, ensuite un swap sera effectué pour la faire passer en production.
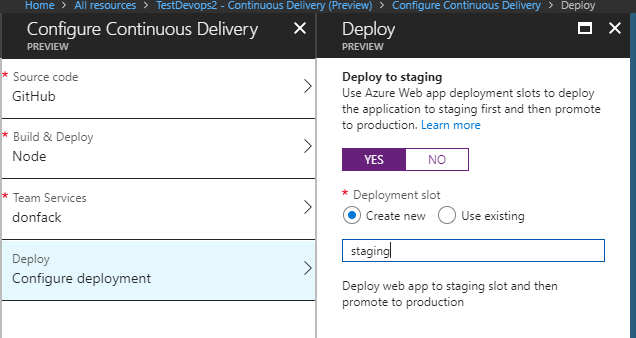
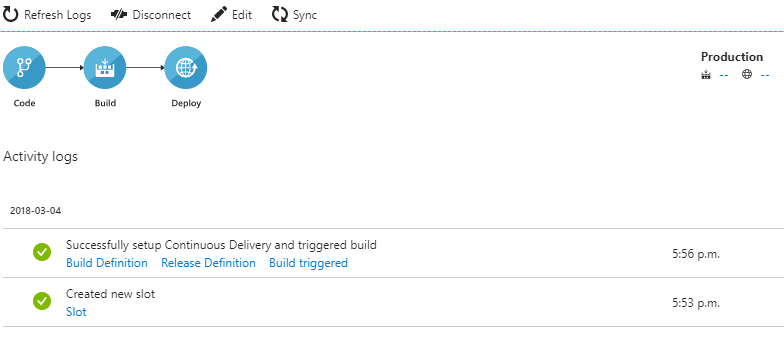
Lorsque toutes les étapes sont complétées, la création de la Build et la Release definition est effectuée sur VSTS. Ensuite, une opération de génération et de déploiement de lapplication est automatiquement enclenchée.
Dans Azure, vous aurez un récapitulatif des configurations effectuées sur VSTS.
1.9. Azure DevOps Projects
La mise en place dun pipeline dintégration et livraison continues peut être une tâche assez fastidieuse. Prenons, par exemple, une application Web ASP.NET Core qui sexécute dans un conteneur Docker. Nous voulons publier cette dernière dans un service Azure (Web App For Container) en utilisant les fonctionnalités de CI & CD offertes par VSTS. Pour y parvenir, nous devons :
- créer dun groupe de ressources Azure (Azure Resource Group) ;
- créer un Azure Registry qui servira de repository privé pour les images docker de notre application ;
- créer un Azure App Service ;
- configurer notre application pour utiliser un repository Git sur VSTS ;
- configurer la connexion entre VSTS et Azure ;
- configurer le pipeline dintégration continue pour une application ASP.NET Core qui sexécute dans un conteneur Docker ;
- configurer le pipeline de déploiement continu ;
Toutes ces configurations demandent une bonne connaissance de lensemble de ces outils/services. En dehors de quelques petites spécificités liées aux besoins du projet, la configuration restera la même dun projet à lautre. Microsoft a donc décidé dautomatiser le processus en offrant Azure DevOps Projetcs.
Avec Azure DevOps Projects, vous pouvez en 5 min procéder à la mise en place dun pipeline dintégration et déploiement continus pour un tel projet. Les services adéquats seront créés et les configurations nécessaires seront automatiquement effectuées dans Azure et VSTS.
Le service offre :
- un support intégré des infrastructures dapplication populaires, notamment .NET, Java, PHP, Node.js ou encore Python ;
- la mise en place rapide et automatique dun pipeline dintégration et de déploiement continus ;
- du monitoring intégré avec Application Insights ;
- la possibilité de démarrer à partir de zéro avec une nouvelle application ou utiliser une application existante.
Nous allons donc commencer par ouvrir le portail Azure, et créer une nouvelle ressource DevOps Projetcs.
Étape 1 : Choix du Runtime
La 1 ère chose à faire sera la sélection de la plateforme dexécution de votre application, si vous partez de zéro (.NET, Java, PHP, Python, etc.).
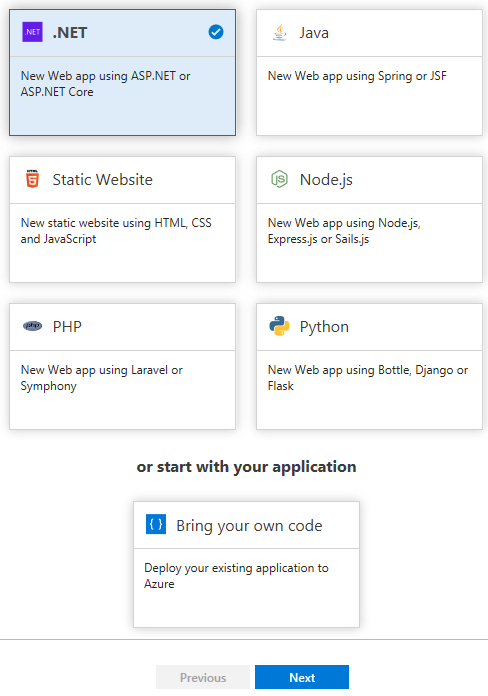
Si vous avez une application existante, vous devez cliquer sur « Bring your own code ». Ensuite, vous devez renseigner le repository distant sur lequel votre projet est archivé. Pour un repository GitHub, en quelques clics, vous êtes en mesure de lier votre compte GitHub avec Azure. Pour un autre fournisseur, vous devez fournir les renseignements nécessaires pour récupérer votre code : URL du repository, nom de branche, utilisateur et mot de passe pour un repository privé Pour linstant seul Git est supporté. TFSVC de Microsoft non pris en charge.
Pour notre test, nous allons sélectionner .NET.
Étape 2 : Choix du Framework
Pour .NET, vous avez le choix entre le Framework ASP.NET ou ASP.NET Core. Pour un projet Java, le choix sera entre Spring et JSF. Pour NodeJS, vous devez choisir entre NodeJS uniquement, Express.js et Sails.js
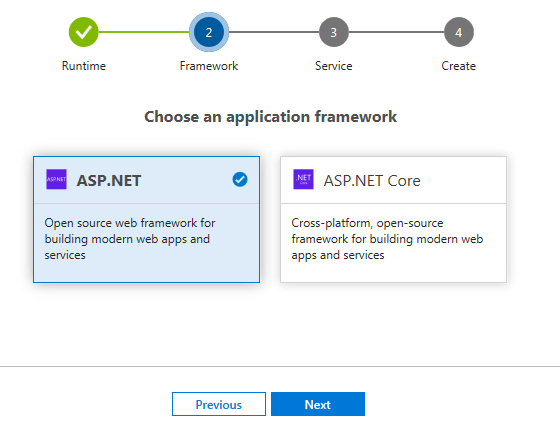
Pour notre cas, nous allons choisir ASP.NET Core.
Étape 3 : Choix du service Azure
A létape 3, vous devez sélectionner le service Azure dans lequel votre appli va sexécuter. Les choix offerts pour linstant sont Web App (Windows et Linux), Web App For Containers et Virtual Machine (Windows pour linstant). Plusieurs autres services Azure seront supportés avant la sortie de la version stable.
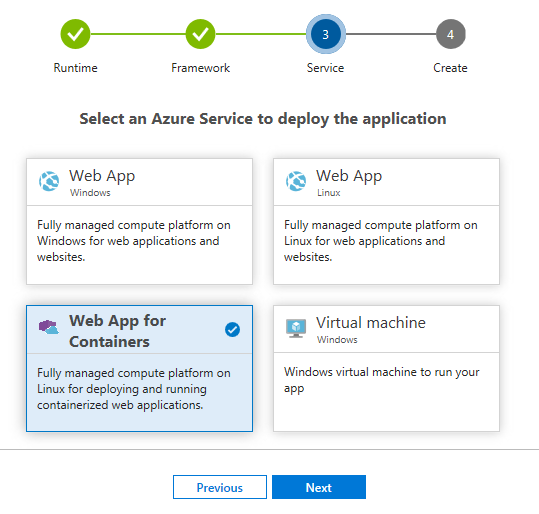
Pour notre test, nous allons sélectionner Web App for Containers.
Étape 4 : Création du pipeline
La dernière étape sera la spécification du compte VSTS, labonnement Azure et le nom de projet qui seront utilisés.
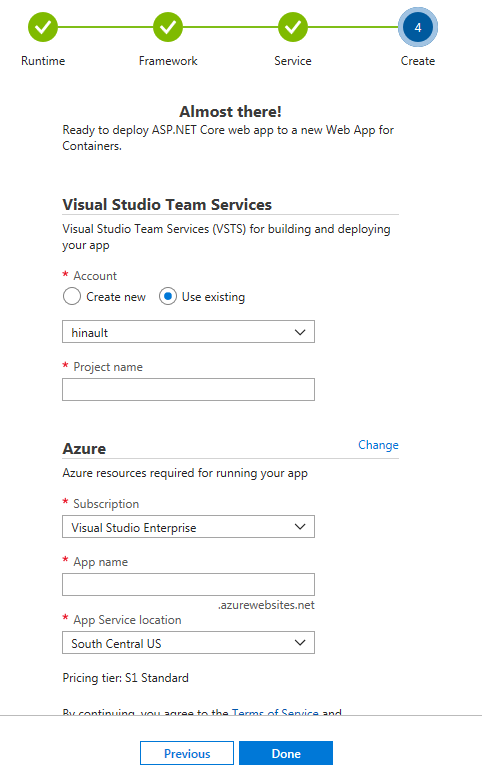
Un clic sur Done et tout le processus est enclenché. À partir dun Template qui sera chargé depuis Azure, les services nécessaires pour le déploiement de votre application seront créés. Il sagit dun App service plan, un registre privé de
conteneurs, un App Service et Application Insights pour le monitoring.
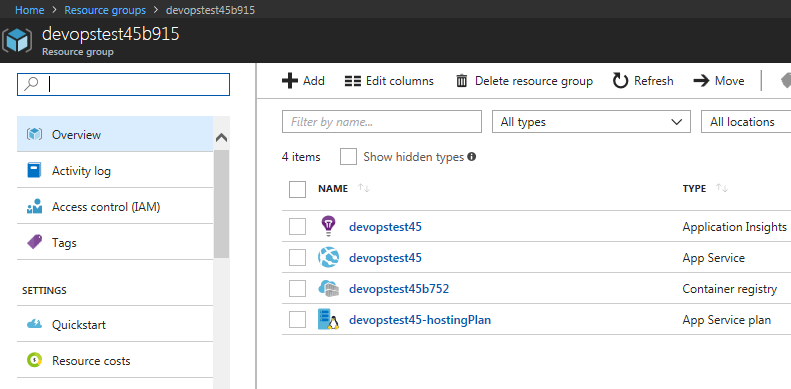
Dans un groupe de ressources différent, deux autres services sont créés pour le suivi. Il sagit dun service DevOps Projects et dun Team Services account :
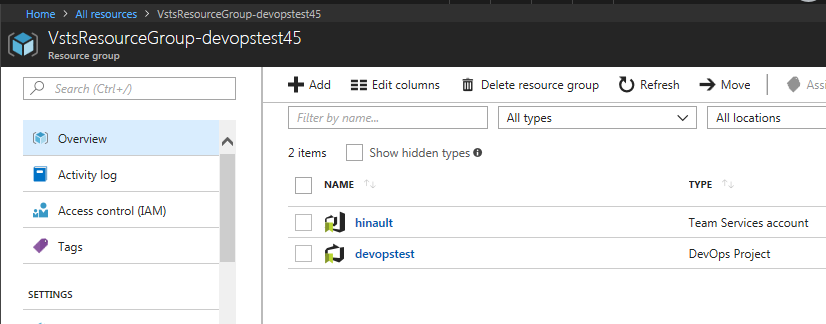
Le Team Service Account permet daccéder aux informations sur votre compte VSTS.
Le service DevOps Project est en quelque sorte un tableau de bord qui agrège un certain nombre dinformations pertinentes de VSTS, nécessaires à la gestion de votre projet. En un coup dil, vous saurez quand a eu lieu le dernier commit, la dernière Build et le dernier déploiement. Les différents liens permettent daccéder à VSTS pour plus de détails, Application Insights et Azure App Service
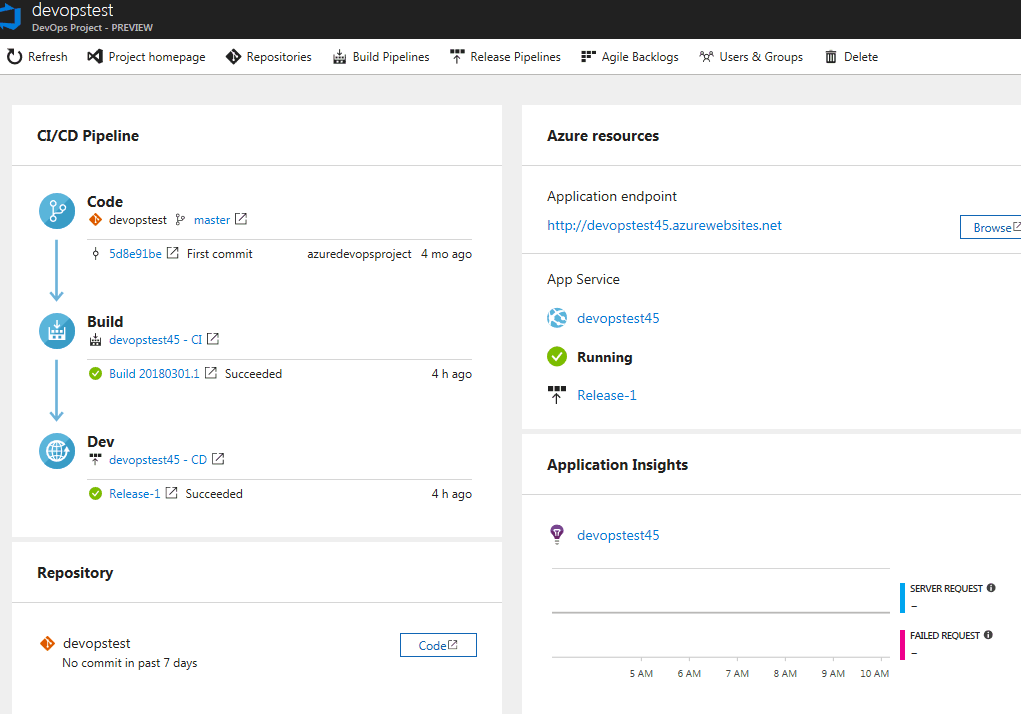
Si vous cliquez sur le lien en dessous dApplication endpoint, vous serez redirigé vers la page daccueil de votre application :
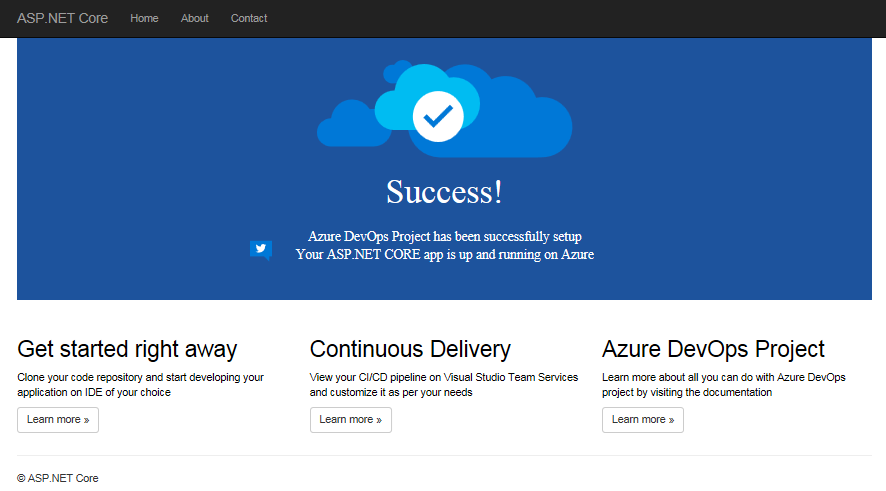
Du côté de VSTS, le projet déquipe a été créé. Ensuite, un repository Git a été créé pour lapplication. Les configurations pour permettre la communication entre VSTS et Azure sont automatiquement effectuées. La configuration des tâches pour la Build Definition et la Release Definiton en fonction des caractéristiques de lapplication est également effectuée. Enfin, un commit du code source est effectué pour démarrer le processus de CI et CD.
Vous navez plus quà cloner votre code source et procéder aux modifications en utilisant votre EDI favori. Une fois vos modifications poussées vers le repository distant, la build et le déploiement sur Azure se feront automatiquement. Si vous avez des besoins particuliers, vous pouvez ajuster les configurations faites par défaut.
Azure Devops Projects est un excellent moyen pour mettre en place un pipeline de CI et CD, créer les ressources adéquates pour son application, etc. rapidement, sans avoir besoin de connaissances avancées.
1.10. Azure Application Insights et configuration
Il est recommandé de disposer des indicateurs permettant de mesurer les performances de lapplication, dévaluer la qualité des livrables, dêtre informé et pouvoir réagir rapidement en cas de bogue, etc. Surtout lorsque lapplication est en production, car ces indicateurs de performances et de qualité seront une base de travail pour améliorer lapplication et mieux répondre aux besoins des utilisateurs.
Un pipeline DevOps doit donc intégrer des outils qui permettront aux équipes projets de saméliorer en continu. Cela sinscrit dans la portion Mesure des cinq piliers de DevOps (Culture, Automation, Lean, Measurement, Sharing). Pour adresser ce besoin, Azure offre comme solution Azure Applications Insights.
Quest-ce quAzure Application Insights
Azure Application Insights est un service extensible de gestion des performances des applications Web, permettant une analyse temps réel de son application. Le service détecte automatiquement les problèmes de performances. Il intègre de puissants outils danalyse qui aident à diagnostiquer les problèmes et à comprendre ce que font les utilisateurs avec votre application. Il a été conçu pour permettre daméliorer continuellement les performances et la convivialité. Il prend en charge un large éventail de plates-formes, notamment .NET, Node.js et J2EE, hébergées sur site ou dans le cloud.
Lun des atouts dApplication Insights est le fait quil sintègre à votre processus DevOps et offre des points de connexion à un large éventail doutils de développement. Application Insight analyse entre autres les éléments : - Taux de demandes, temps de réponse et taux déchec - Taux de dépendance, temps de réponse et taux déchec - Exceptions - Consultations de pages et performances de chargement - Appels AJAX à partir de pages web - Nombre de sessions et dutilisateurs - Compteurs de performances - Diagnostics dhébergement de Docker ou Azure. - Journaux de suivi des diagnostics de votre application - Mesures et événements personnalisés
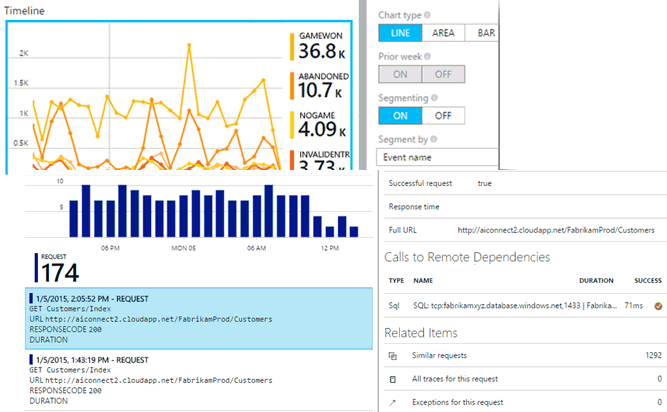
Intégration dApplication Insights dans le code de linfrastructure
Dans les parties précédentes de cette série de billets de blog, nous avons procédé à la création de notre infrastructure en utilisant des fichiers de scripts JSON (ARM Template). Ces fichiers de scripts ont été intégrés dans un pipeline dintégration et livraison continue, tout comme le code de lapplication.
De ce fait, pour chaque évolution de linfrastructure, les modifications sont effectuées dans les fichiers de scripts de configuration et archivées. A ce moment, le déploiement des changements en production se fait automatiquement par le pipeline.
Nous disposons actuellement des ressources suivantes dans notre infrastructure sur Azure: App Service plan, Storage account, et App Service.
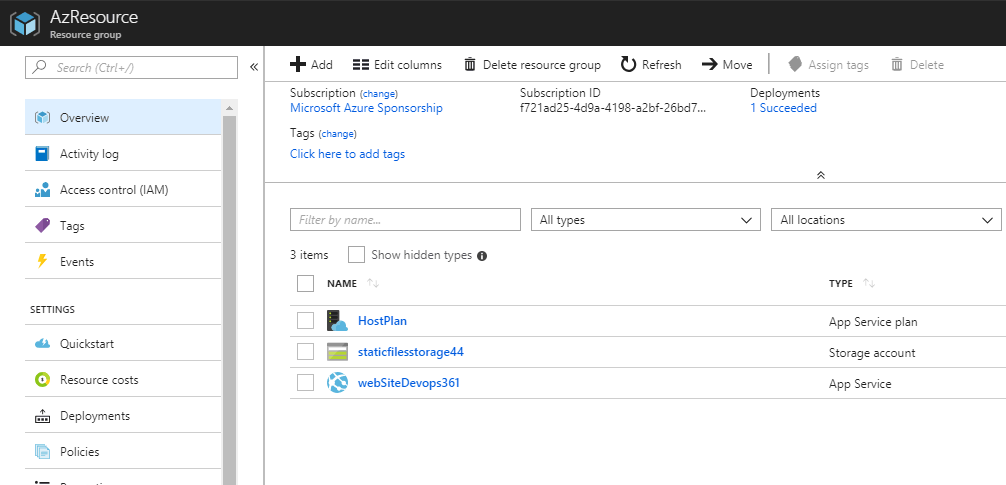
Notre besoin actuel est de pouvoir ajouter la nouvelle ressource Application Insights à notre infrastructure. La nouvelle ressource à ajouter est de type « Microsoft.Insights/components ». Le code JSON ARM Template permettant de créer cette dernière est le suivant :
{
"apiVersion": "2014-04-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Insights/components",
"location": "East US",
"dependsOn": [
"[resourceId('Microsoft.Web/sites/', variables('webSiteName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]": "Resource",
"displayName": "AppInsightsComponent"
},
"properties": {
"applicationId": "[variables('webSiteName')]"
}
}
La ressource Application Insights aura le même nom que lapplication Web. Lemplacement doit être le même que celui de lapplication car les deux ressources doivent être créées dans le même ressource group. La ressource Application Insights dépend de la ressource pour lapplication Web, dont le second sera créé avant le premier.
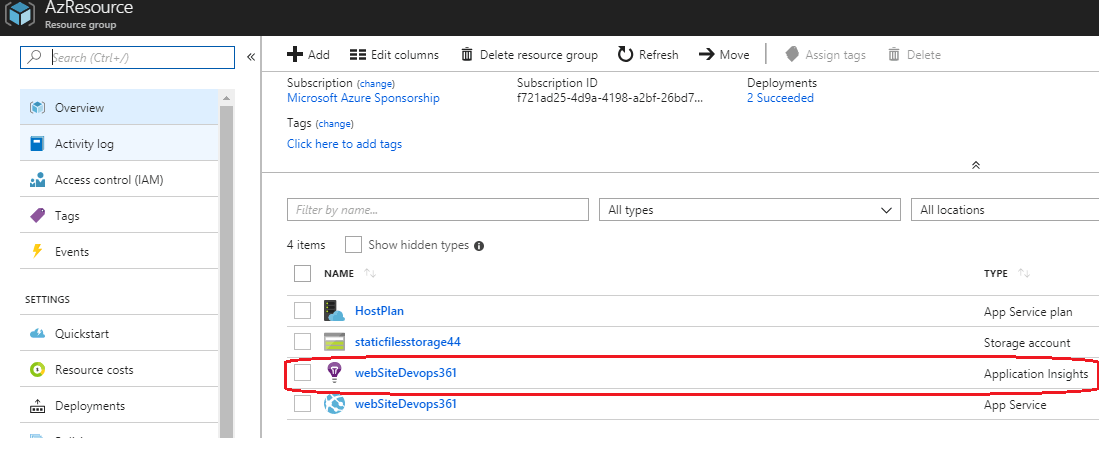
Il est important dajouter le paramètre tags qui est linké avec ResourceGroup Id de la Web App. Cela permet non seulement davoir les ressources dans le même ressource group, mais aussi de créer un lien entre les deux ressources. Ainsi, dans le portail Azure à partir de la WebApp vous pouvez naviguer vers Application Insights.
Pour ajouter cette nouvelle ressource, vous devez simplement éditer le fichier JSON de description de votre infrastructure et ajouter le code ci-dessus :
WebSite.json
{
"apiVersion": "2014-04-01",
"name": "[variables('webSiteName')]",
"type": "Microsoft.Insights/components",
"location": "East US",
"dependsOn": [
"[resourceId('Microsoft.Web/sites/', variables('webSiteName'))]"
],
"tags": {
"[concat('hidden-link:', resourceGroup().Id, '/providers/Microsoft.Web/sites/', variables('webSiteName'))]"
"displayName": "AppInsightsComponent"
},
"properties": {
"applicationId": "[variables('webSiteName')]"
}
}
Une fois vos modifications enregistrées et archivées, votre infrastructure sera mise à jour avec la création de la nouvelle ressource Application Insights :
Configuration dApplication Insights dans le projet
Afin quApplication Insights puisse collecter les données de télémétrie sur les performances et le fonctionnement de notre application, nous devons intégrer le SDK de ce dernier et configurer notre application afin que les informations soient transmises à la ressource Application Insights que nous avons créée précédemment.
Cela va demander la modification de plusieurs fichiers. Mais, en utilisant VS, lintégration est assez simple, car une interface est offerte pour guider le développeur dans le processus.
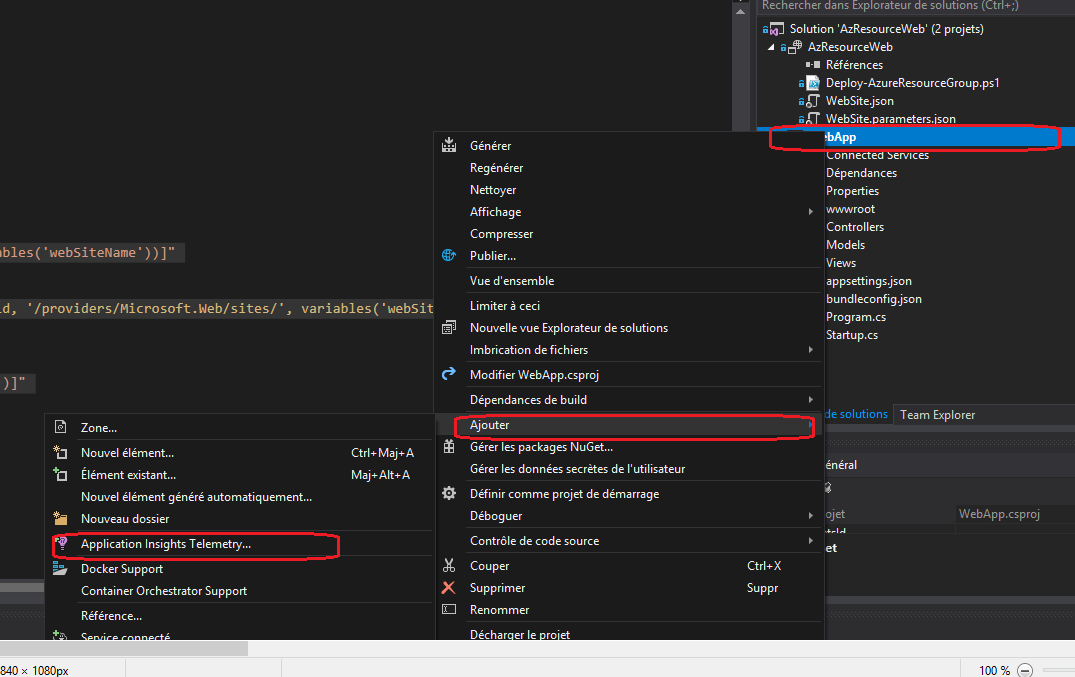
Lintégration dAppli. Insights se fait à partir de lexplorateur de solution en faisant un clic sur le projet, Ajouter, ensuite Application Insights Telemetry.
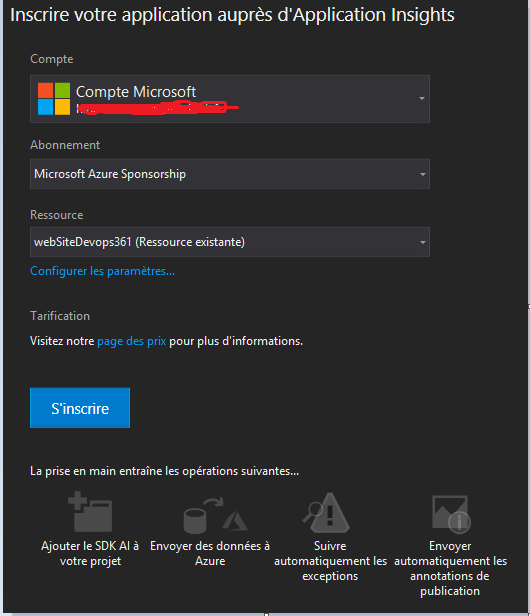
Dans la fenêtre de configuration qui va safficher, cliquez sur Bien démarrer. Il ya une interface qui va safficher permettant de sélectionner votre compte Azure, labonnement Azure, ensuite la ressource Application Insights. Si cette dernière nexiste pas, il est possible den créer directement une. Mais, procéder ainsi serait en contradiction avec lapproche Infrastructure as Code (IaC). Ceci parce que linfrastructure sera modifiée sans passer par les scripts de configuration.
Un clic sur sinscrire et la configuration est effectuée pour votre projet.
Le fichier .csproj est modifié pour ajouter les packages nécessaires au fonctionnement de Application Insights. Une entrée est effectuée dans le fichier appsettings.json pour ajouter la clé dinstrumentation de la ressource Application Insights. La classe Program est mise à jour pour prendre en compte Application Insights dans le pipeline HTTP de ASP.NET Core. Et enfin, le Layout de lapplication est modifié pour intégrer les scripts JavaScript dinstrumentation de Application Insights.
Vous pouvez enregistrer votre projet et archiver toutes vos modifications. Le déploiement se fera automatiquement. Suite à lutilisation de votre application, de nombreuses informations seront collectées et agrégées dans le portail Azure.
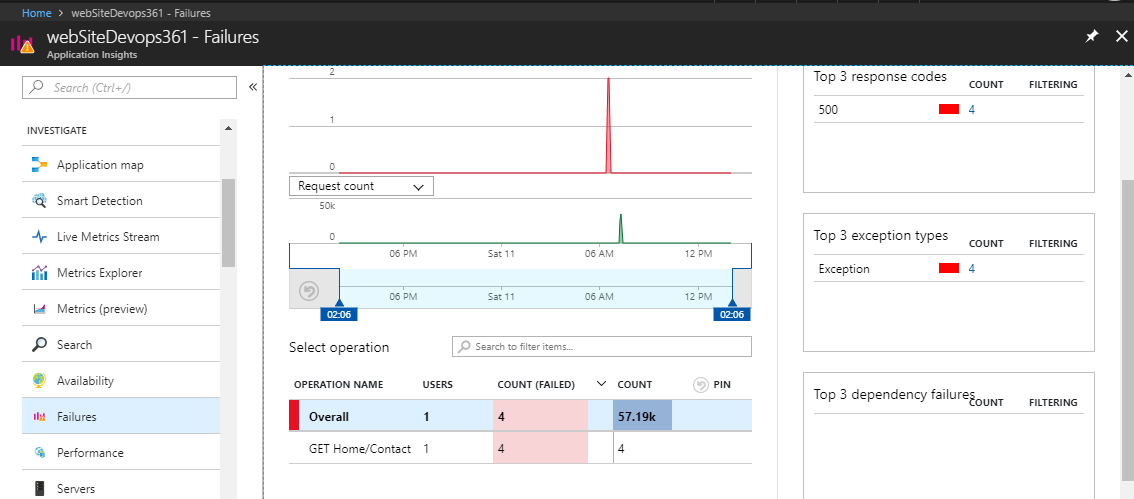
Le monitoring et lévaluation de son application en production est étape importante et non négligeable dans un projet DevOps. Avec Application Insights, vous avez une solution à ce besoin.
1.11. Tests fonctionnels avec DevOps
Les tests manuels Les tests manuels nécessitent quun testeur interagisse avec lapplication en suivant éventuellement un scénario de tests, quil sassure que le comportement de lapplication est en lien avec le résultat escompté. Les tests manuels sont essentiellement une liste textuelle détapes.
Les tests codés Les tests codés de linterface utilisateur (coded UI test) permettent la mise en place de tests fonctionnels capables dinteragir avec linterface utilisateur en automatique, de vérifier que le résultat escompté est conforme et ; si non, douvrir un bug relatif à lerreur rencontrée. Lensemble de ce processus étant automatisé, il est possible dexécuter ces tests fréquemment. En revanche, leur rédaction et leur maintien sont beaucoup plus lourds et coûteux que des tests manuels.
Les tests unitaires Les tests unitaires font partie du processus du développement intrinsèque. Ils permettent au développeur de sassurer quune fonction fonctionne correctement. Cest essentiellement du code qui teste du code.
Les tests de charge Les tests de charge sont généralement basés sur des tests de performance. Le 1er vérifie la performance dune application comme son nom lindique, tandis que le second permet de « stresser » mon application afin de vérifier si elle est en mesure de supporter une charge importante dutilisateurs simultanés.
Test plans
Avec Azure DevOps, je dispose dun espace dédié pour la rédaction de mes jeux de tests, leur exécution et leur suivi. Avec les Test Plans, je peux gérer mes jeux de tests pour une itération donnée. Un Test Plan inclue mon scénario de tests, les configurations (operating systems, navigateurs), les résultats. En termes dorganisation, un Test Plan peut correspondre à un sprint par exemple dans le cadre dun développement dapplications avec une approche Agile. Je peux donc décider de tester à lintérieur de ce Test Plan, lensemble des nouvelles fonctionnalités qui sont développées au cours de cette itération.
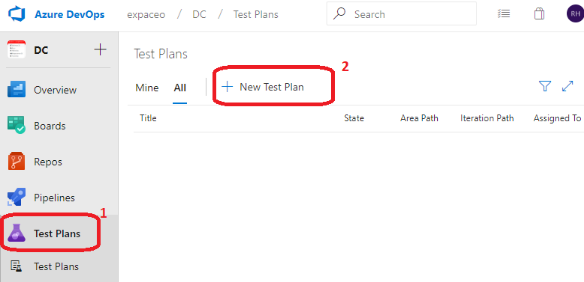
A partir dAzure DevOps, cliquer sur Test Plans (1) puis sur New Test Plan (2).
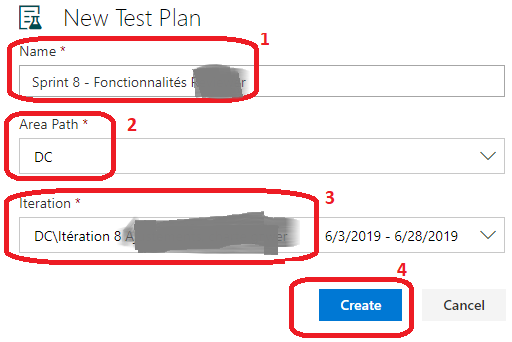
Renseigner le Name du Test Plan (1), le Area Path (2) et la Iteration (3), puis cliquer sur Create (4).
Configuration de tests
Aller sur Configurations, puis configurer autant denvironnements que de besoin en fonction des systèmes dopérations et des navigateurs à partir desquels les tests seront effectués. Si je coche Assign to new test plans, ces configurations seront assignées à lensemble des Test Pans qui seront créés. Les jeux de tests seront dupliqués autant de fois quil y a denvironnements de tests différents qui ont été configurés.
Modélisation du métier -> Conception / Architecture -> Développement -> Test unitaires & d'intégration -> Affinage du modèle métier & refactorisation ->
Test case
A partir de mon Test plan, je peux mettre en place mes Test cases ou scénarios de tests. Un scénario de tests décrit un ensemble dinteractions que je peux avoir avec mon application qui ont pour objectif de valider une fonctionnalité ou un comportement de cette dernière. Un Test case est un work item de mon usine logicielle Azure DevOps.
Je peux créer un Test case à partir de Work items (1), puis New Work Item (2), Test Case (3).
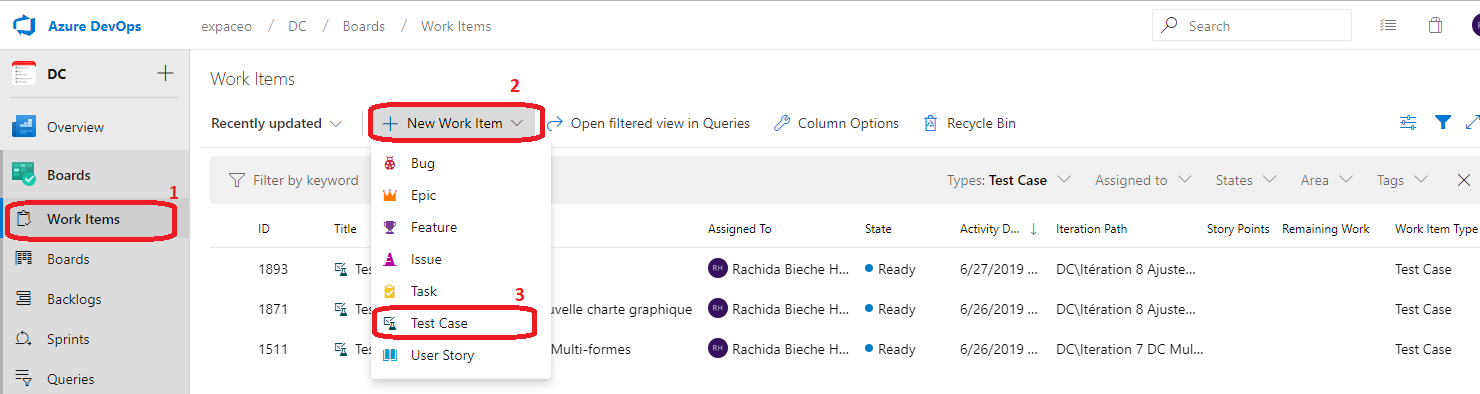
Je renseigne le nom de mon Test Case (1), lIteration et je peux cliquer sur Shared Steps pour inclure des étapes qui sont traditionnellement partagées entre plusieurs scénarios de tests. Un Shared Step est considéré comme un work item.
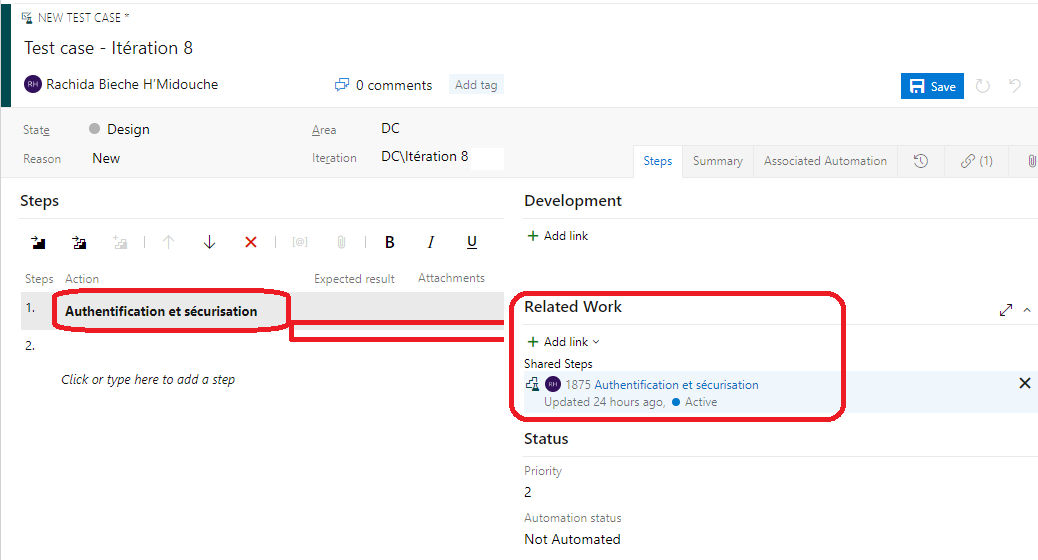
Pour ajouter un Shared Step, cliquer sur licône Insert Shared Steps (1) puis sur Run Query (2) pour lancer la recherche de work item type Shared Steps.
Une fois mon Shared Step ajouté, je peux le visualiser à droite de ma fenêtre comme un lien. En cliquant sur le work item, je peux visualiser le contenu du
Shared Step et le gérer à ma guise.
Si je nai pas encore de Shared Tests, je peux e n créer un, en cliquant sur licône Create Shared Steps (1) et en lui donnant un Name (2).
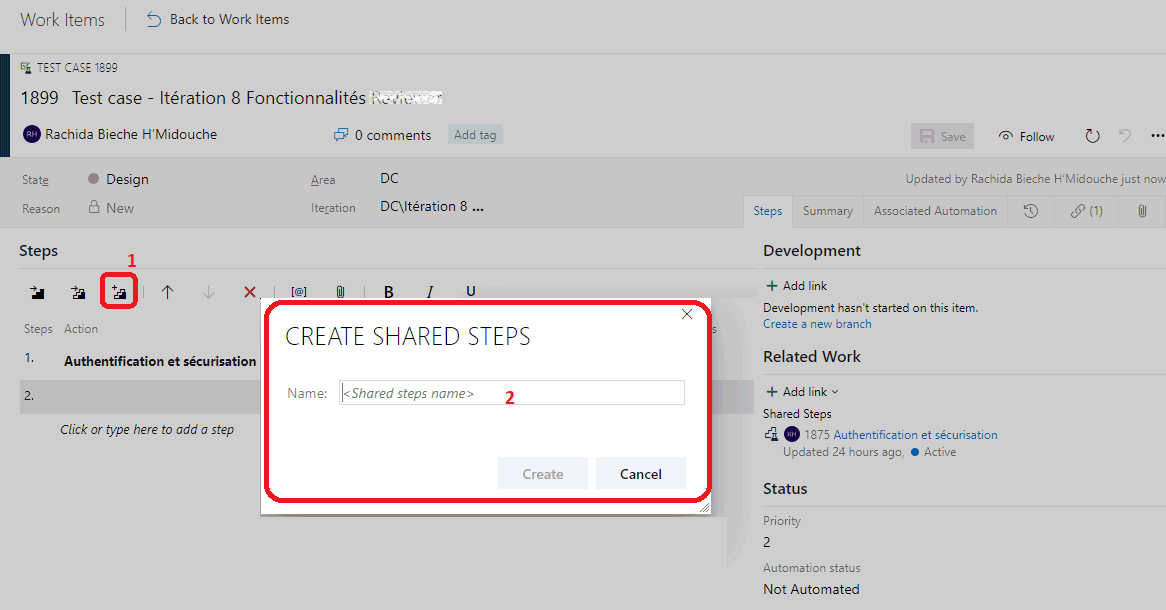
Shared steps
Les Shared Steps peuvent être utiles lorsquil y a des étapes partagées, répétitives donc, quil est nécessaire dexécuter avant de tester une fonctionnalité. Ces étapes répétitives sont répétées dans plusieurs scénarios de tests. Ceci est le cas spécifique de lauthentification par exemple. Il peut donc être utile afin doptimiser leur maintenance de les décrire dans des Shared Steps et de réutiliser ces Shared Steps dans plusieurs jeux de tests. Je ne rédige donc quune seule fois les étapes nécessaires à laccès et à lauthentification à lapplication et je peux les réutiliser à autant dendroits que je le souhaite. Je peux également créer un Shared Step a posteriori en sélectionnant un ensemble de steps déjà créés e t en cliquant sur Create shared steps.
Je définis lensemble de mes étapes partagées(1), je peux ajouter des paramètres précédés de la mention @(2), définir la valeur de mes paramètres (3), décrire le résultat escompté (4) et éventuellement ajouter des pièces jointes.
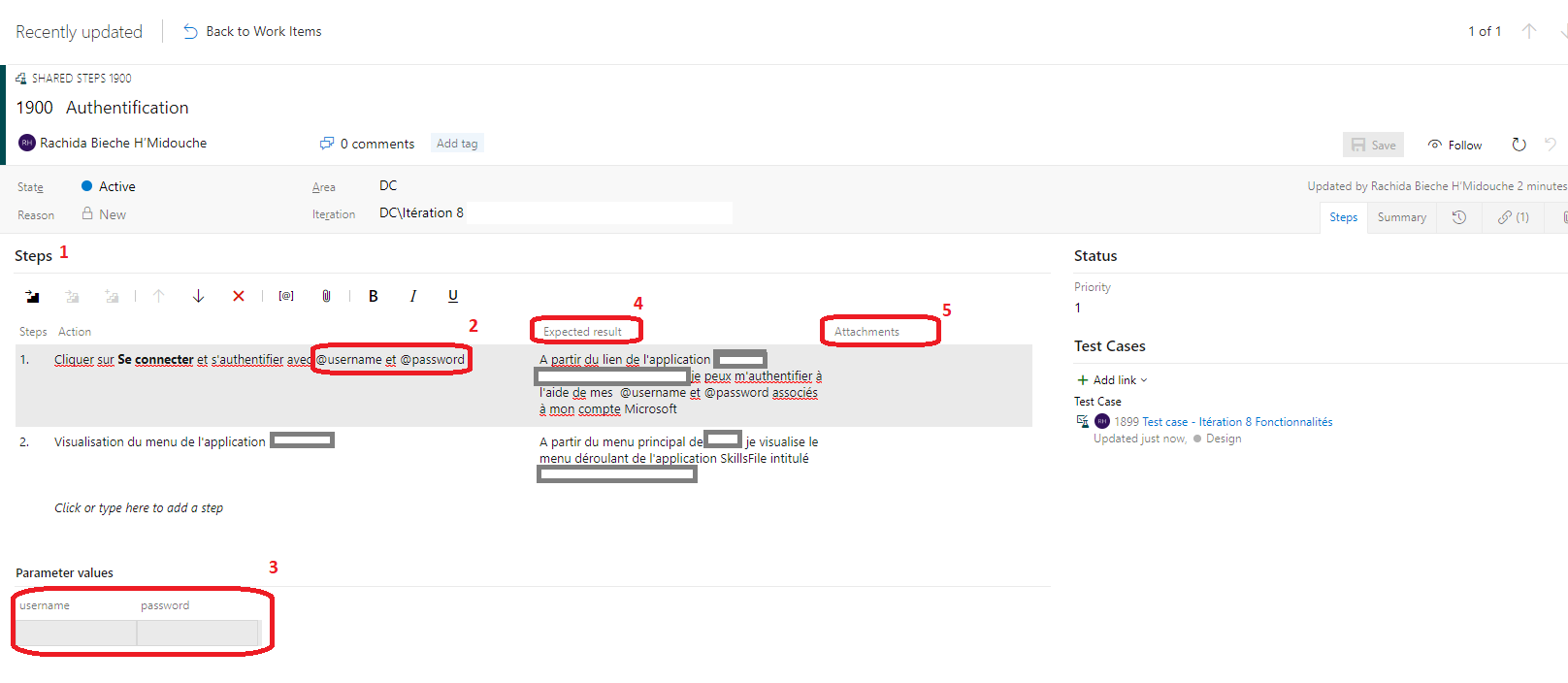
Expected result Cette colonne permet de renseigner les informations que le testeur devrait vérifier lorsquil exécute le test, telles que le résultat escompté de laction quil vient de réaliser.
Attachments Dans la colonne Attachments, je peux joindre une photo ou autre qui donnerait davantage dinformations sur ce que le testeur devrait faire ou vérifier.
Paramètres
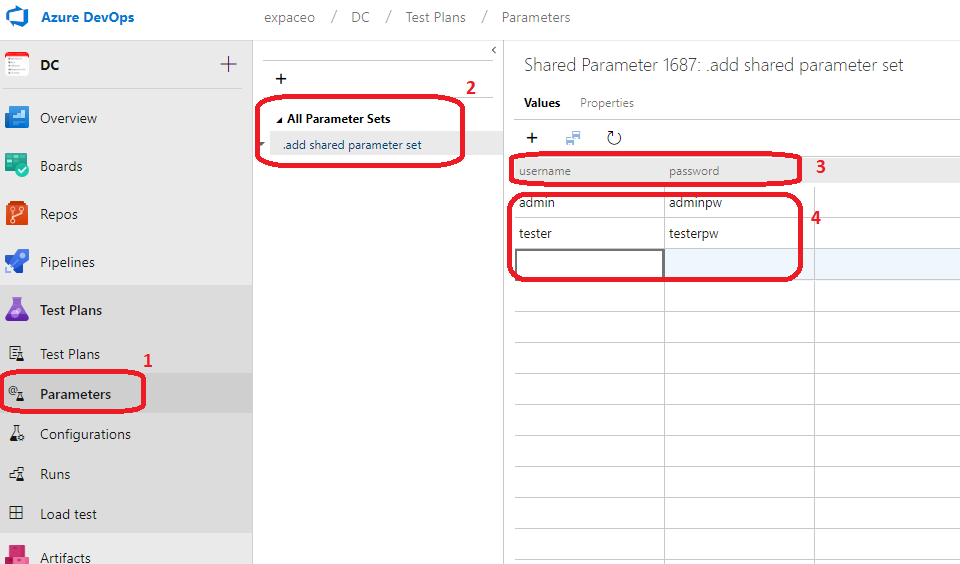
Je peux utiliser des paramètres afin de fournir différentes valeurs à un jeu de tests. Au lieu de dupliquer un jeu de tests, je peux paramétrer un jeu unique avec plusieurs valeurs possibles. Les valeurs que je définis pour chacun de mes paramètres seront utilisées au moment de lexécution des tests, chaque valeur correspond à une itération de jeu de tests.
Aller sur Parameters (1), cliquer sur Add shared parameter set (2), renseigner le nom des paramètres (3), puis les valeurs (4).
Repartir sur le Test case, cliquer sur Add link (1) et Choisir Existing item et référencer le add shared parameter set que lon vient de configurer et il devrait apparaître directement (2).
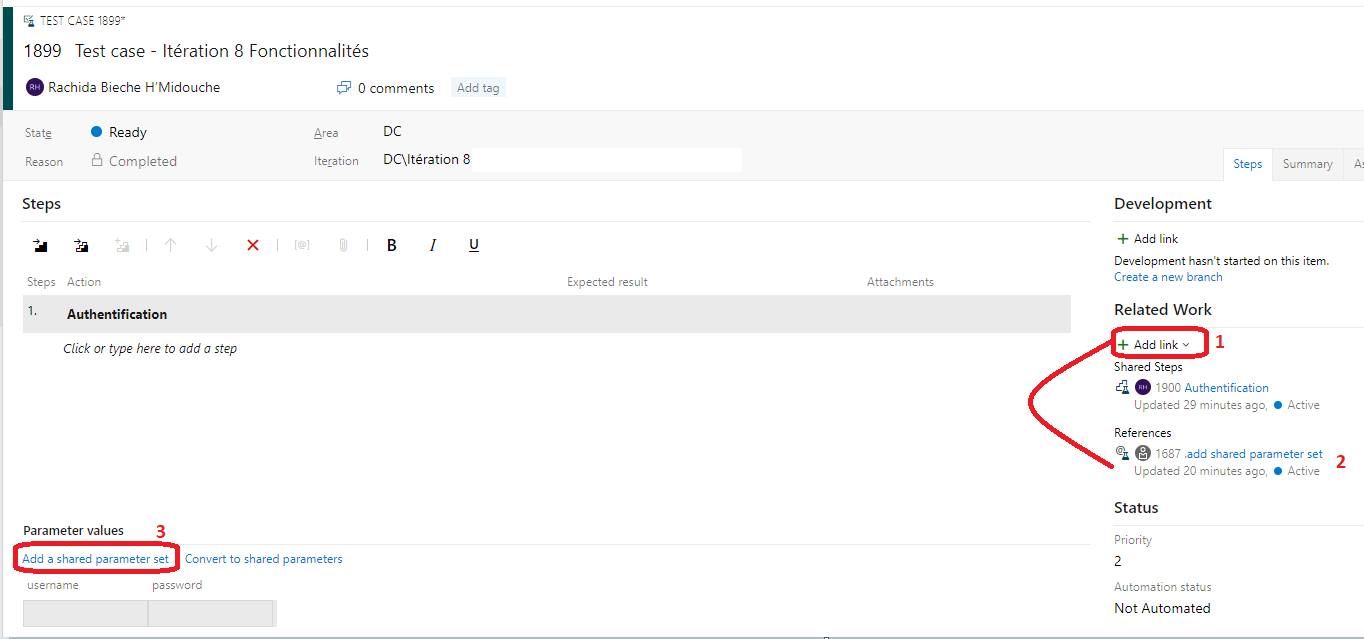
Ensuite cliquer sur Add a shared parameter set (3) et lon devrait voir les valeurs définies apparaître comme ci-dessous.
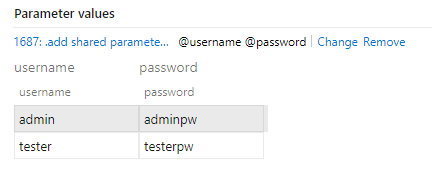
Je peux continuer à renseigner lensemble des fonctionnalités que je souhaite tester en ajoutant autant détapes que nécessaires.
Test suite
Il existe trois différentes suites de tests dans Azure DevOps :
1.Static suite 2.Requirement-based suite 3.Query-based suite
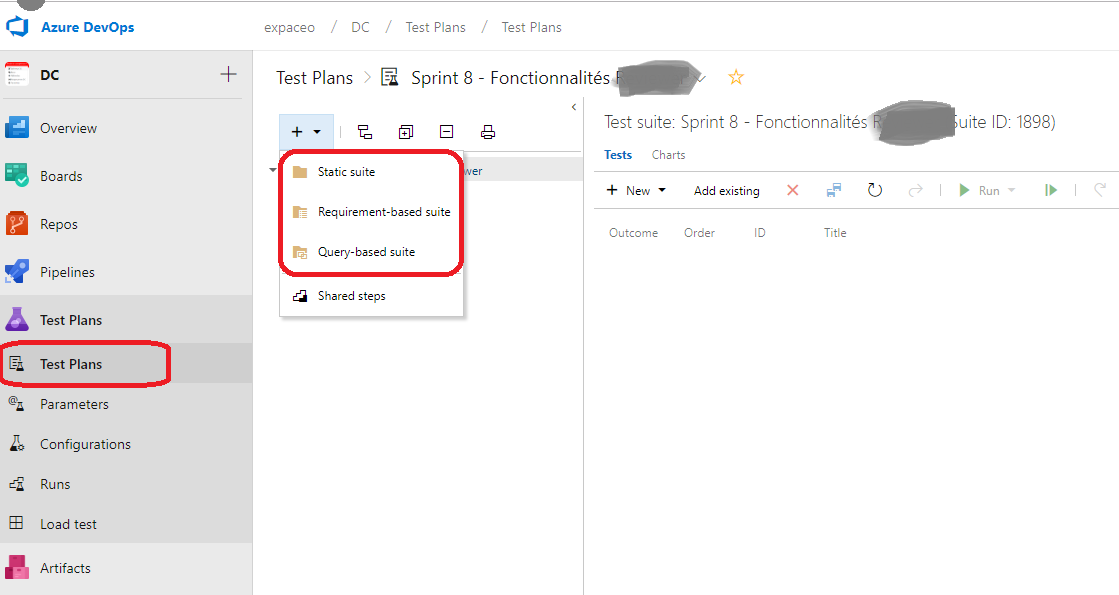
Static suite
Cest une liste simple de scénarios de tests qui peuvent être ajoutés manuellement à un scénario.
Requirements-based test suite
Ces tests concernent nimporte quels scénarios de tests liés à des user stories, items de spécifications fonctionnelles qui sont chargés au début de chaque itération en vue dêtre implémentés dans lapplication au cours du sprint. Ceci permet donc de créer et dexécuter un jeu de tests qui permet de vérifier que la fonctionnalité décrite au travers de la user story a été implémentée en conformité avec les spécifications.
La work item par défaut pour les spécifications fonctionnelles est la user story pour un projet créé avec un template basé sur la méthodologie Agile dans Azure DevOps.
Query-based suite
La Query-based suite permet de spécifier une requête dynamique de work items afin de sélectionner un Test case selon certains critères. Je peux par exemple rechercher parmi des scénarios de tests ceux qui se focalisent sur des
fonctionnalités critiques développées plus tôt afin de sassurer quelles nont pas été cassées ou que nous ne sommes pas face à une régression en raison du développement de nouvelles fonctionnalités. Je peux aussi tout simplement rechercher mon Test Case en lien avec les nouvelles fonctionnalités en cours de développement que je veux tester et le charger pour exécuter les tests.
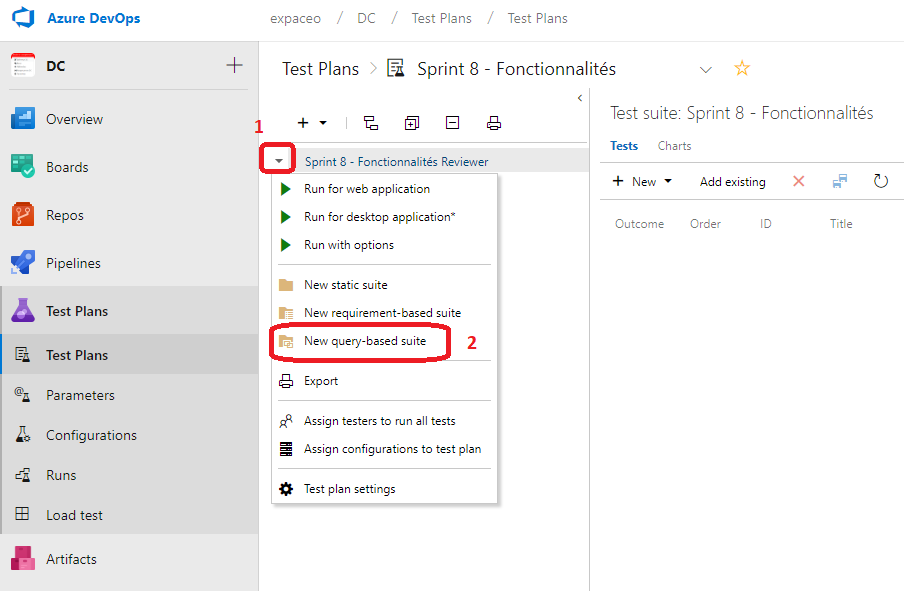
Nous allons mettre en place une Query-based suite tests pour exécuter nos tests. Depuis Test Plans, cliquer sur la flèche (1) puis sur New Query-based suite.
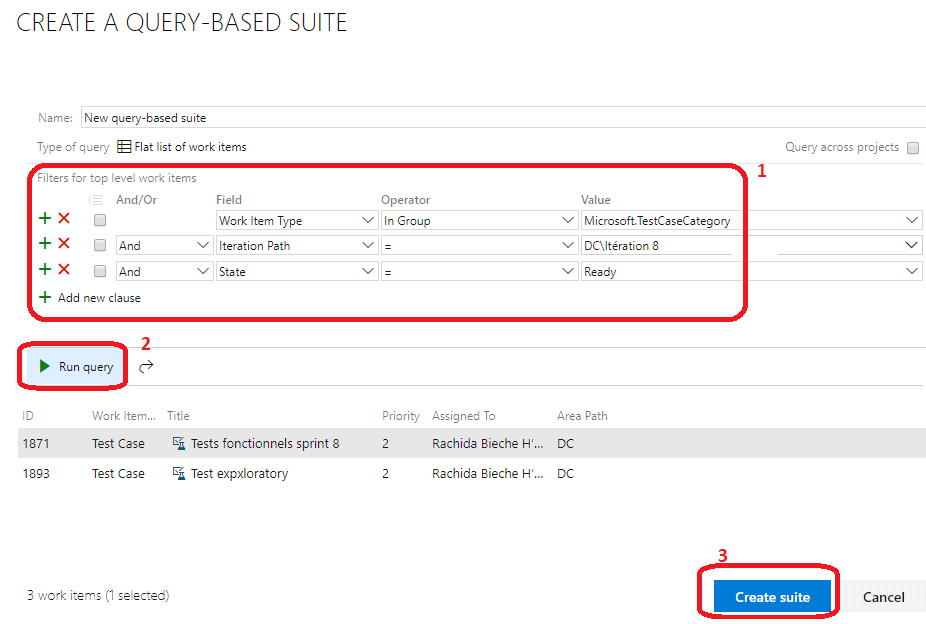
Une pop-up souvre pour lancer une requête qui nous permet deffectuer une recherche parmi les tests disponibles selon certains critères. Ajouter autant de filtre que nécessaire en cliquant sur Add new clause (1), puis cliquer sur Run query (2) pour lancer la requête, puis cliquer sur Create suite après avoir sélectionné le ou les tests qui vous intéressent.
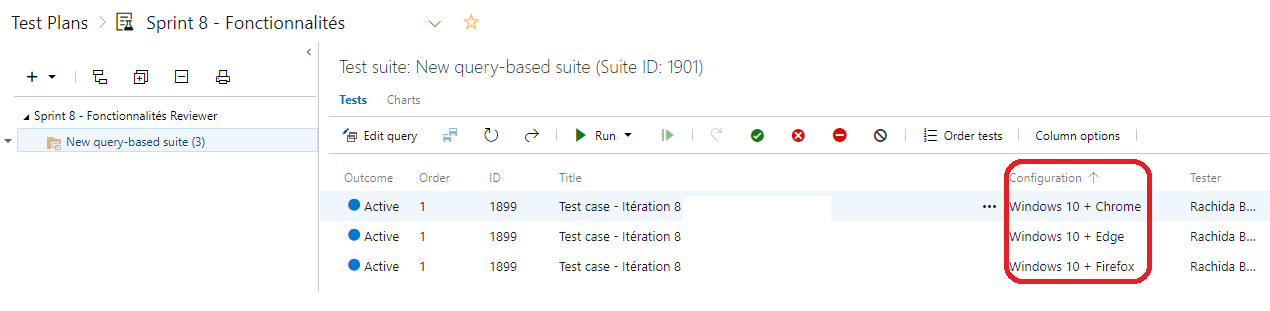
Comme mentionné plus tôt, les tests cases que jobtiens sont multipliés autant de fois que jai défini denvironnements de tests (os + navigateur).
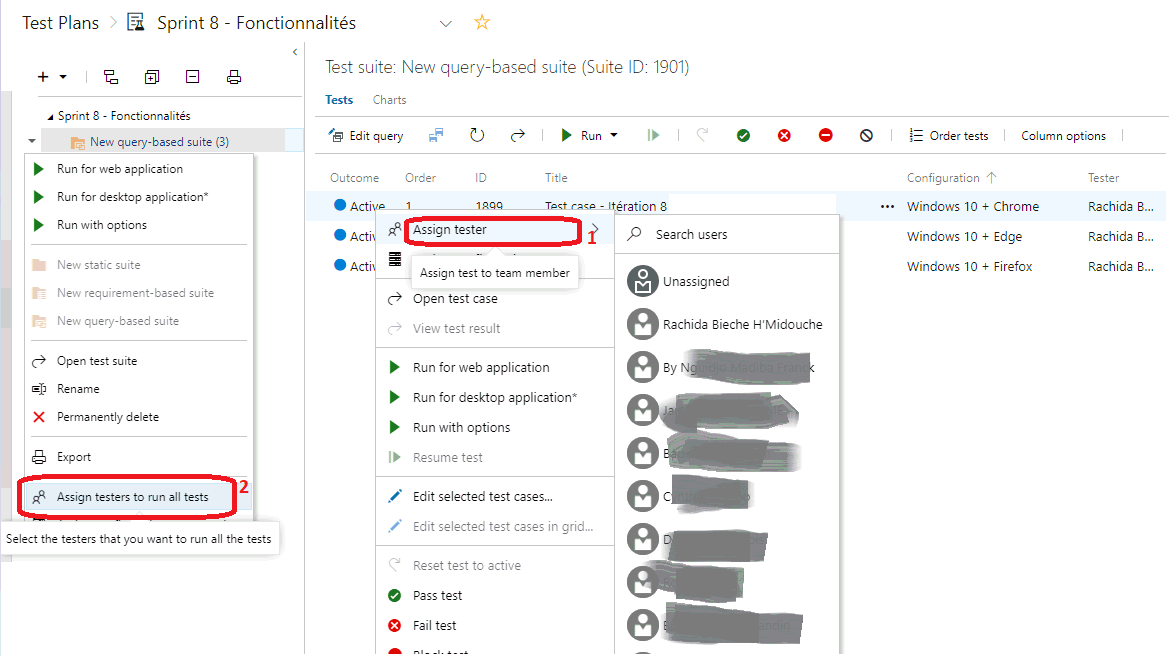
Assigner des testeurs
Je peux assigner des testeurs pour la réalisation de mes tests, à lensemble de ma suite de tests (2) ou à un seul jeu de tests (1).
Exécution des tests
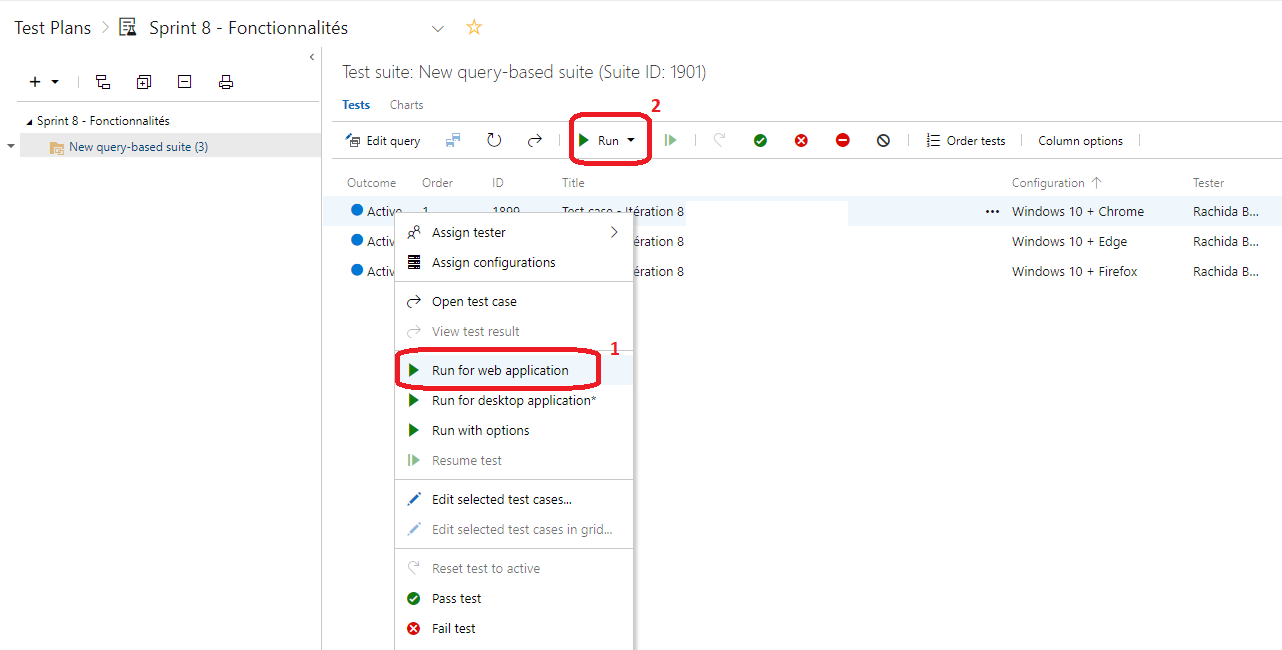
A partir de ma query-based suite, je fais clique droit (1) sur le test que je veux exécuter et je choisis ceux qui me conviennent. Jobtiens un résultat similaire à partir de la barre en cliquant sur Run (2).
Pour exécuter mes tests, mieux vaut avoir un écran partagé dans lequel je mets
dun côté mon jeu de tests et de lautre mon application que je teste.
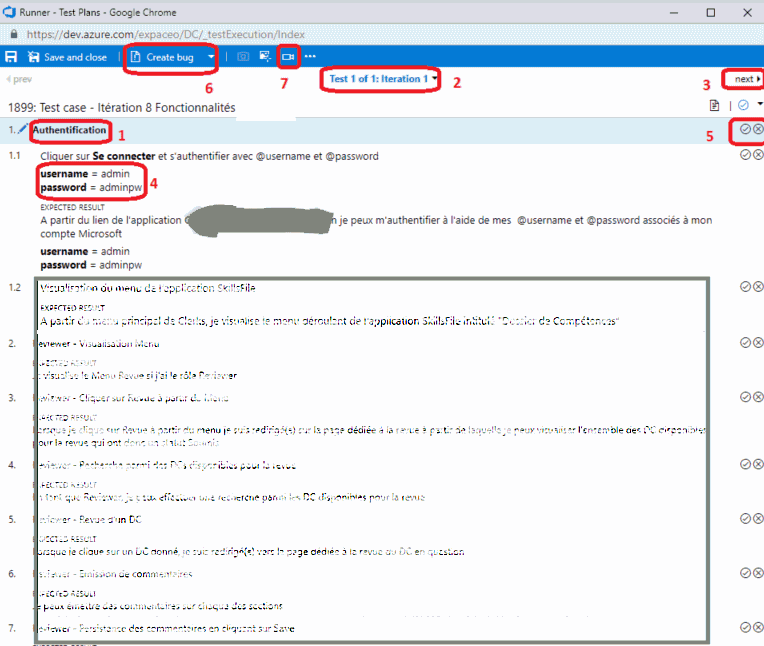
Ma première étape est la Shared Steps Authentification(1) que nous avons définie
plus tôt. Jai donc deux itérations (2) pour cette étape en raison des deux
parameters values (4) que nous avons définies. Je peux accéder au deuxième jeu
de valeurs en cliquant sur next (3). Je coche chaque étape en fonction du
comportement de lapplication eu égard à la fonctionnalité que je teste (5). Si
une étape échoue je peux renseigner un commentaire et logger directement un bug
avec Create bug (5). Je peux aussi enregistrer mes actions (7).
Création de bugs
A quoi bon faire des tests si lon ne consigne pas les bugs quelque part, en vue de leur résolution ?
Azure DevOps a mis à disposition une série doutils qui permettent de tracer de manière détaillée les étapes de reproduction du bug, en outre il est également possible de joindre au bug, des captures décran et des vidéos explicitant au maximum le bug afin que le développeur ait lensemble des informations à portée de main pour procéder au débogage et à la résolution du bug.
Les informations facilement mises à disposition par Azure DevOps que lon peut inclure dans un bug sont :
- Les informations sur la machine à partir desquelles les tests sont exécutés
- Le journal des étapes suivies par le testeur lorsquil a rencontré le bug
- Les informations relatives au système dinformation de la machine i.e. los, ram, version du navigateur etc.
- Les enregistrements vidéo lors des tests
Pendant lexécution de mes tests, je peux créer directement un bug à partir de ma fenêtre de jeu de tests. Grâce à mon extension Test & Feedback, je peux enregistrer mes actions (avec audio aussi). Lors de la création dun bug, la ou les vidéos seront directement attachée(s). Des informations systèmes sont également incluses automatiquement, et je peux ajouter des commentaires, des captures décran, etc.
Pour installer lextension Test & Feedback suivre le tutoriel suivant :
https://docs.microsoft.com/en-us/azure/devops/test/perform-exploratory-tests?view=azure-devops
Puis suivre les instructions pour se connecter à son projet :
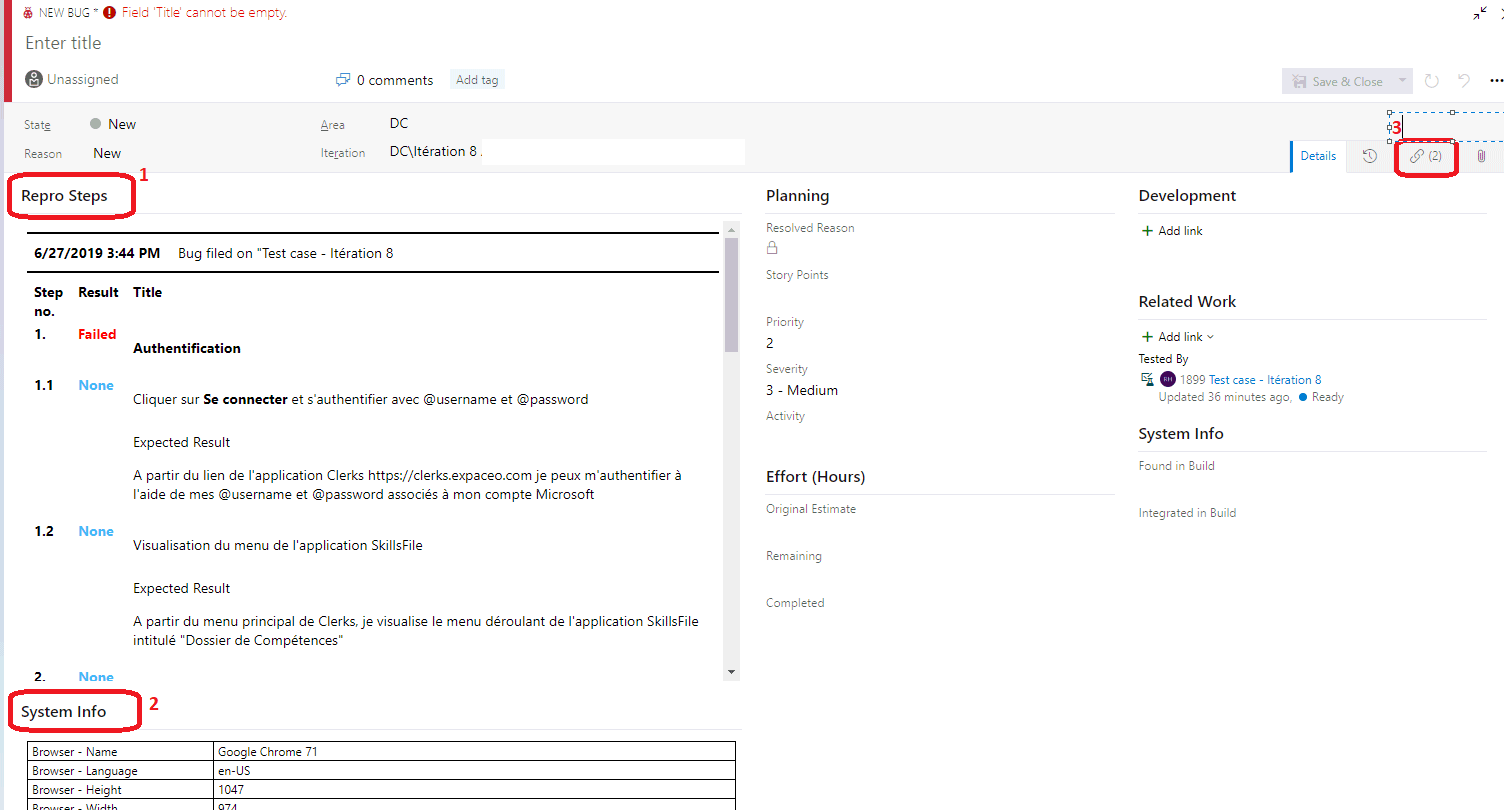
Quand je clique sur Create Bug, une fenêtre pop-up souvre. Dans les Repro Steps (1), jai la reproduction des étapes ayant menées au bug. System info(2) procure les informations systèmes (os, ram, navigateur, etc.) de la machine à partir de laquelle les tests ont été faits. Et le lien (3) me permet daccéder à la vidéo que jai enregistrée grâce à mon extension Test & Feedback.
En cliquant sur le lien (3), jaccède à la fenêtre ci-dessous. Je peux assigner mon bug à un membre de léquipe (1), je peux cliquer sur mon résultat de test pour avoir davantage de détails (2) et je visualise aussi le statut de mon test (3).
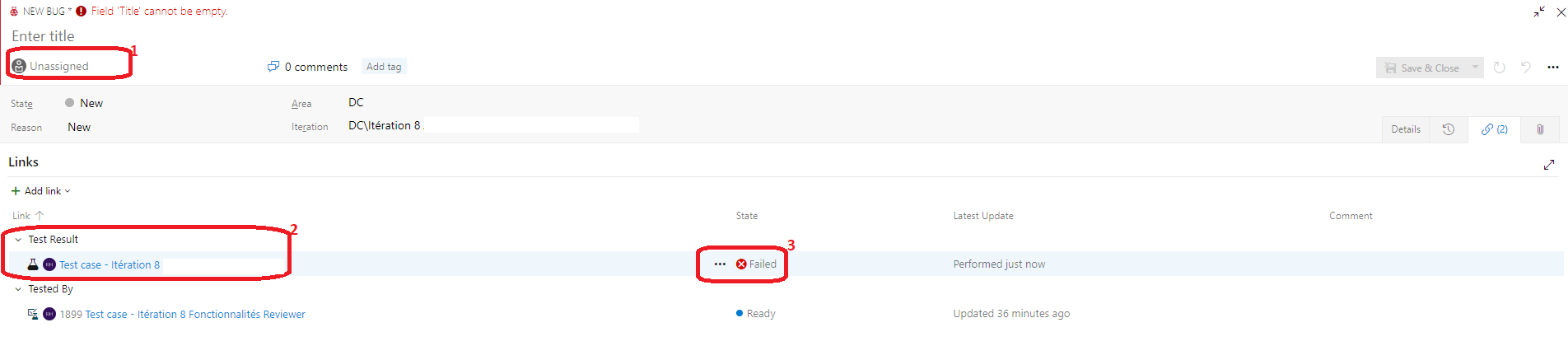
Lorsque je clique sur le résultat de mon test (2), une nouvelle fenêtre souvre avec un niveau granulaire de détails, jy retrouve ma vidéo (1).
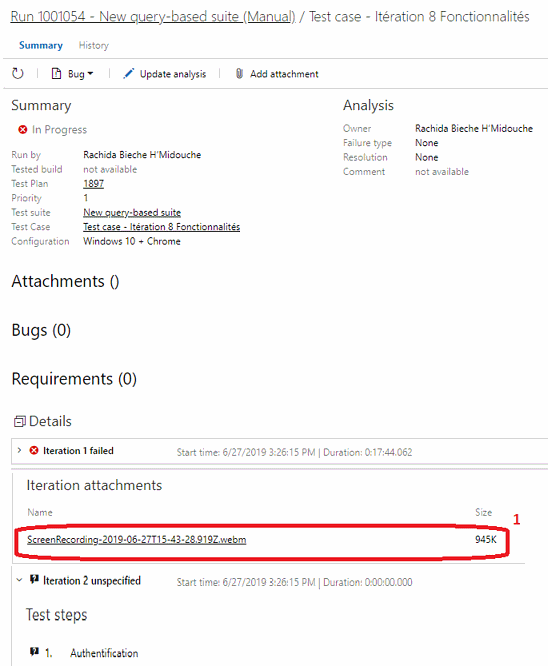
Pilotage et suivi dexécution des tests
Je peux visualiser mes tests prêts à lusage ainsi que leur statut (Passed, failed) dans la section Test Plans. Chaque jeu de tests apparaît autant de fois quil y a denvironnements de configurations définis. Je peux aussi décider de bloquer un test qui ne serait pas prêt à être réalisé par exemple par quil contiendrait des fonctionnalités qui ne seraient pas encore implémentées dans la compilation utilisée par les tests. Dans la section Runs, je peux visualiser le résultat des tests précédents.

Exploratory testing (tests exploratoires)
Comme nous venons de le voir, les tests fonctionnels précédents se basent sur une liste de spécifications fonctionnelles que léquipe de développement a développées. Ce sont des séries de scénarios de tests prédéfinis qui ont pour objectif de valider la bonne implémentation des spécifications.
Les tests exploratoires aussi appelés les tests agiles (agile testing) quant à eux, ne suivent pas un scénario écrit davance. Ils font appel à la créativité et au côté « explorateur » des testeurs afin de laisser libre court à son imagination pour la réalisation des tests, sans quil se sente entravé par un script. Il va donc explorer lapplication sous divers angles pour essayer de la « casser ». Il pourrait ainsi découvrir des bugs, pour lesquels nul naurait pensé à rédiger un cas de test.
Avec Azure DevOps, je peux réaliser mes Exploratory testing au travers de lextension Test & Feedback que jai ajoutée sur mon navigateur.
A partir du navigateur cliquer sur lextension Test & Feedback (1); puis sur Start session (2). Ensuite, cliquer sur Record Screen (3) puis sur Start Recording et sur Share pour accepter de partager son écran. Lenregistrement de lécran est activé.
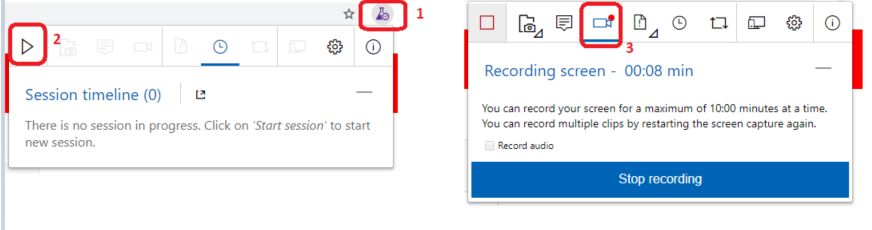
Je peux alors laisser libre cours à mon imagination pour tester mon application de la manière que je souhaite sans suivre un scénario de tests précis.
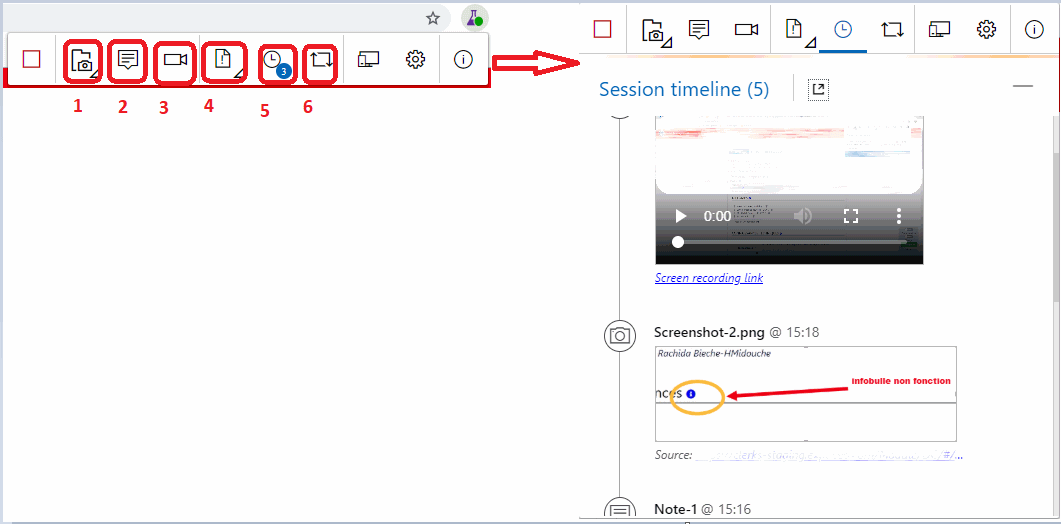
A partir de cette fenêtre de commande, je peux faire des captures décran que je peux annoter (1), ajouter une note (2), lancer un enregistrement vidéo avec ou sans audio (3), créer directement un bug, une tâche ou un test case (4), accéder à mon Timeline (5) avec lensemble des logs (vidéos, captures décran, heures, etc.) ou lier un work item (6).
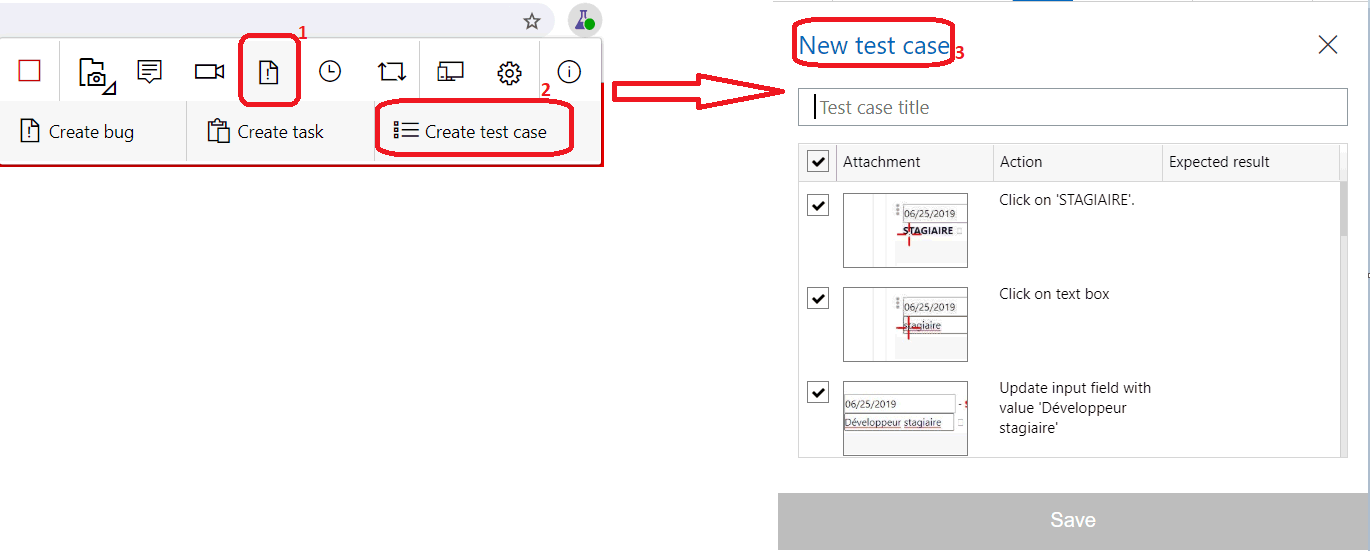
Si je clique sur licône (1), et ensuite sur Create Test Case (2), je peux transformer automatiquement mes enregistrements en Test case, scénario de tests (3). Ceci créera automatiquement un work item Test case dans mon Azure DevOps.
Conclusion
Nous avons vu comment mettre en place des tests fonctionnels avec ou sans paramètres et comment à partir de tests exploratoires, générer automatiquement un jeu de tests. Nous avons également vu comment tracer de manière granulaire
les actions qui ont précédé la rencontre dune anomalie afin douvrir directement un bug aussi détaillé que possible pour une meilleure compréhension et prise en charge par les développeurs.
Il est possible également dajouter à ses tests plans des tests automatisés. Ceci étant, comme évoqué plus haut, les tests automatisés sont plus lourds à rédiger et maintenir. Leur mise en place doit préalablement se faire dans Visual Studio.
réf: test fonctionnels
https://lesdieuxducode.com/blog/2019/7/mise-en-place-et-gestion-de-tests-fonctionnels-avec-azure-devops
1.12. Tests de charge et de performance avec Azure DevOps - Load
Tests
Jévoquerai uniquement les tests de charge basés sur des requêtes http dans un navigateur, effectués à partir dAzure DevOps. A noter quil est également possible deffectuer des tests de charge à partir dAzure Portal. Nous mettrons en place un test de charge simple ; puis, un test avec des paramètres.
Avec les load tests dAzure DevOps, je peux facilement créer un jeu de tests reproductible qui peut maider dune part, à analyser la performance de mon application web; et, dautre part, à identifier de potentiels points de blocage. Je peux donc créer des tests de performance qui répliquent mes actions telles que lors de lutilisation de mon application. Un test de performance web nest rien dautre quune série dinteractions prédéfinies avec une application web qui simule la manière dont un utilisateur donné peut interagir avec mon application. Concrètement, les tests de performance envoient de manière ordonnée une série de requête http(s) à lapplication cible et vérifie que cette dernière adopte le comportement escompté. Sur la base des tests de performance, je vais mettre en place les tests de charge qui ne font que compiler lensemble des résultats des tests de performance, et qui permet de simuler ce qui se passe lorsquun grand nombre dutilisateurs essaie daccéder à mon application simultanément.
Tests de charge à partir dune URL
Les tests de charge à partir dune URL, ou tests de stress ne sintéressent quà la performance brute de mon application. Ils nintègrent donc pas de notions de règles de validation par exemple.
Avec les tests de charge, je peux vérifier que mon application fonctionne correctement même lorsquelle est sollicitée / mise sous pression par plusieurs utilisateurs de manière concurrente. Je peux configurer les niveaux et les types de charge que je souhaite simuler et ensuite exécuter le test de charge. Une série de requête est générée vers lapplication cible. Azure DevOps renvoie lanalyse du résultat des tests de charge relatifs à lapplication qui est mise sous pression au travers dun système dindicateurs clefs et de logs.
Mise en place des tests simples
Accès : Azure DevOps Test Plans Load Tests URL based test
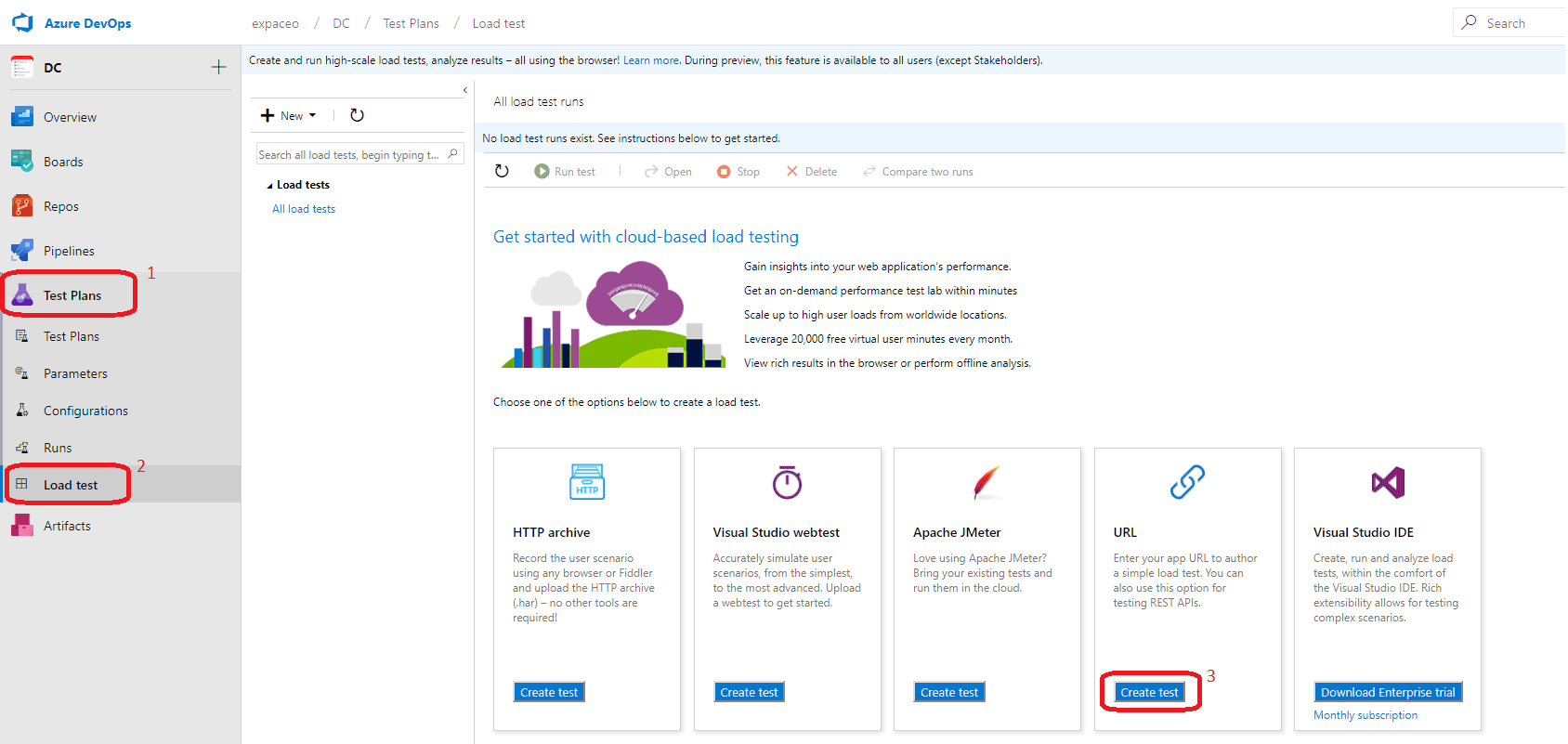
Donner un nom au Test de charge (1), puis renseigner lurl que lon veut tester (2). On peut ajouter autant durl que nécessaire. Pour chaque url, il faut sélectionner la méthode que lon souhaite (GET, POST, PUT). Laisser le http method à Get pour des tests simples.
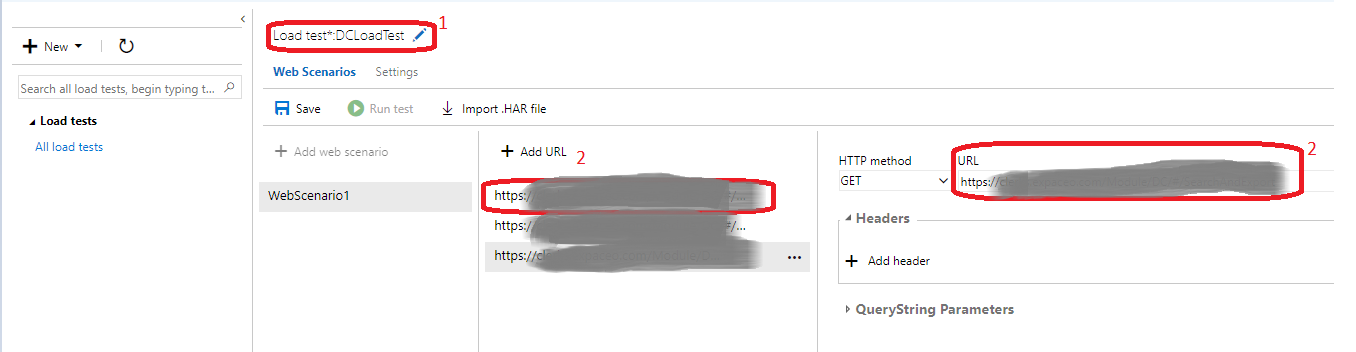
Dans Settings (1), on peux changer les paramètres de tests tels que la durée, le type de chargement, le nombre dutilisateurs virtuels, le lieu (choisir un lieu proche des utilisateurs), le type de navigateur (2) etc.
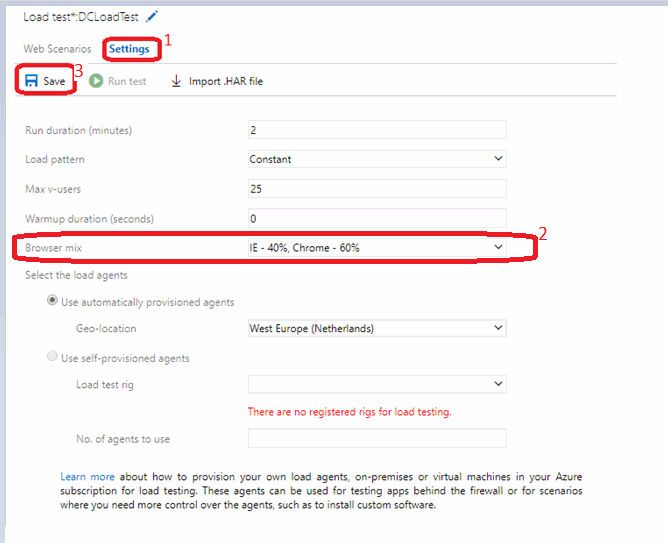
Quelques explications
Load pattern : Le load pattern ou schéma de charge permet de simuler la charge utilisateur de deux manières distinctes : constante ou séquentielle.
Une charge constante permet de définir une charge utilisateur qui va rester inchangée, constante donc, pendant toute la durée des tests. Si je définie une base dutilisateurs virtuels à 400, la performance de mon application sera analysée avec une base constante de 400 utilisateurs virtuels pendant toute la durée des tests.
Le step load ou charge séquentielle définit un certain nombre dutilisateurs virtuels au début des tests ainsi quun nombre maximal dutilisateurs pendant la durée des tests. Dans ce cas de figure, je dois préciser la durée dune séquence (step duration en secondes) ainsi que le nombre dutilisateurs virtuels (step user count) pendant cette séquence. Lorsque la durée de la première séquence expire, le nombre dutilisateurs virtuels sincrémente en fonction du nombre dutilisateurs spécifié pour la prochaine séquence, à moins que le nombre maxi dutilisateurs nait déjà été atteint. Les tests de charge séquentiels sont très utiles dans le processus didentification du nombre dutilisateurs que mon appli
peut supporter avant quelle ne commence à rencontrer des problèmes performance.
Warmup duration: Le paramètre warm-up duration sert à définir un laps de temps pendant lequel aucune information relative aux tests ne sera enregistrée / recueillie / observée bien que le test soit en cours dexécution. Après ce laps de temps d « échauffement » (permettant dexclure les délais éventuels de compilation et de gestion du cache), la collecte de données débute et se poursuit jusquà ce que le temps défini dans le paramètre du temps dexécution (run duration) soit atteint.
Browser mix: Le paramètre browser mix permet de préciser la répartition par type de navigateur que nous souhaitons simuler. Le type de navigateur na de sens, en ce qui concerne les tests de performance, que si lapplication testée a été configurée différemment afin de tenir compte du poste (desktop, mobile, etc.).
Load agent: Les machines «agent » sont les machines qui vont être utilisées pour les tests, versus les machines « client » qui sont la machine du développeur. Les machines agent exécutent les tests de charge. Ces tests étant exécutés sur le cloud Azure, il est préférable de sélectionner un agent qui se trouve proche, dun point de vue géographique, des utilisateurs de lapplication.
Test rig : Un test rig est composé dun contrôleur (qui coordonne les actions dune ou plusieurs machines agent) et de n agent(s). Dans cet exemple nous utiliserons les agents prédéfinis par Azure.
Lancer les tests
Lancer les tests en cliquant sur Run Test.
Lorsque je clique sur Run pour exécuter mes tests, les requêtes http définies sont envoyées à mon application, dans lordre défini dans mon scénario Web.
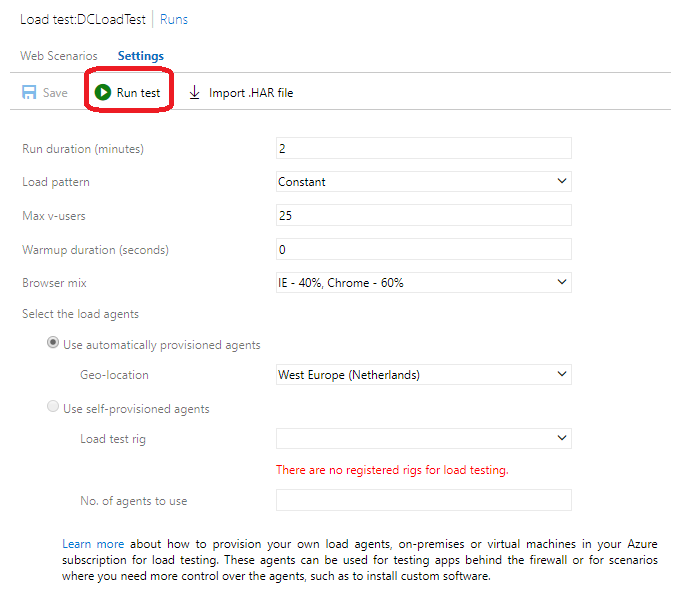
visualiser et interpréter les résultats de mes tests
Je peux visualiser un résumé de mes tests, des graphes, un diagnostic et des logs. Lanalyse des données de mes tests de charge me permet didentifier des points de blocage, des erreurs et de mesurer limpact des améliorations dans mon application.
Attention, lexécution de mes tests peut générer des erreurs qui nincomberaient pas uniquement à mon application mais qui peuvent être inhérentes à la rédaction et configuration de mes tests.
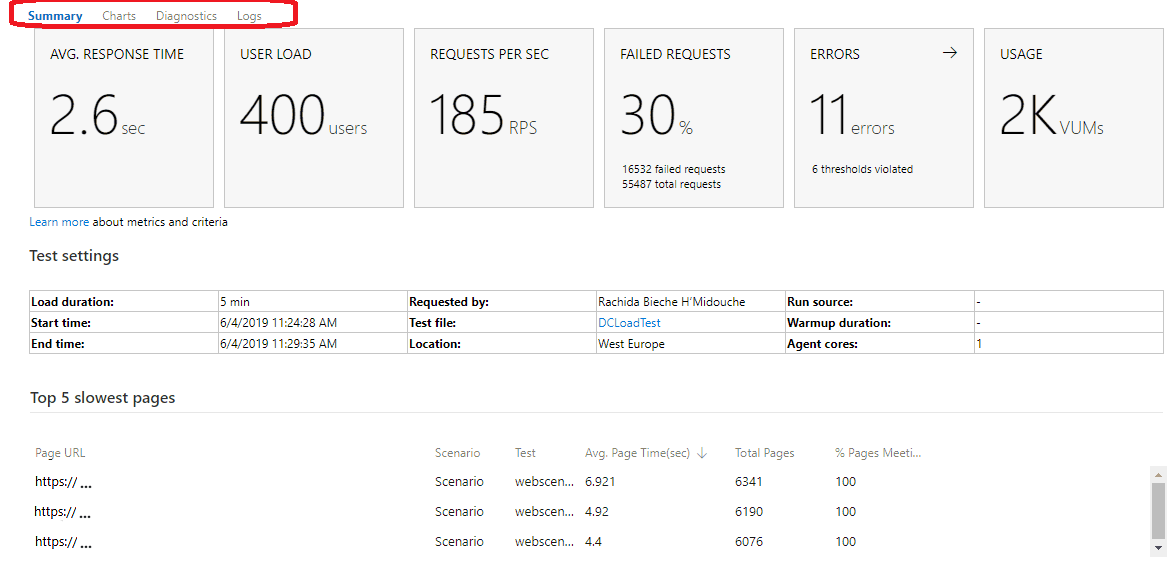
Dans la section Summary, je peux visualiser entre autres quelques métriques / statistiques relatives au nombre d utilisateurs qui a été chargé, le nombre de requêtes par seconde, le pourcentage de requêtes qui ont échoué, le temps moyen de réponse, le nombre derreurs, mes top 5 des pages les plus lentes (ainsi que le nombre de fois que chaque page a été sollicitée, la moyenne du temps de réponse de chacune), etc. Lusage et le VUM (Virtual User Minutes) ont trait au décompte qui sera appliqué à la souscription et donc à la tarification Azure eu égard à ce test.
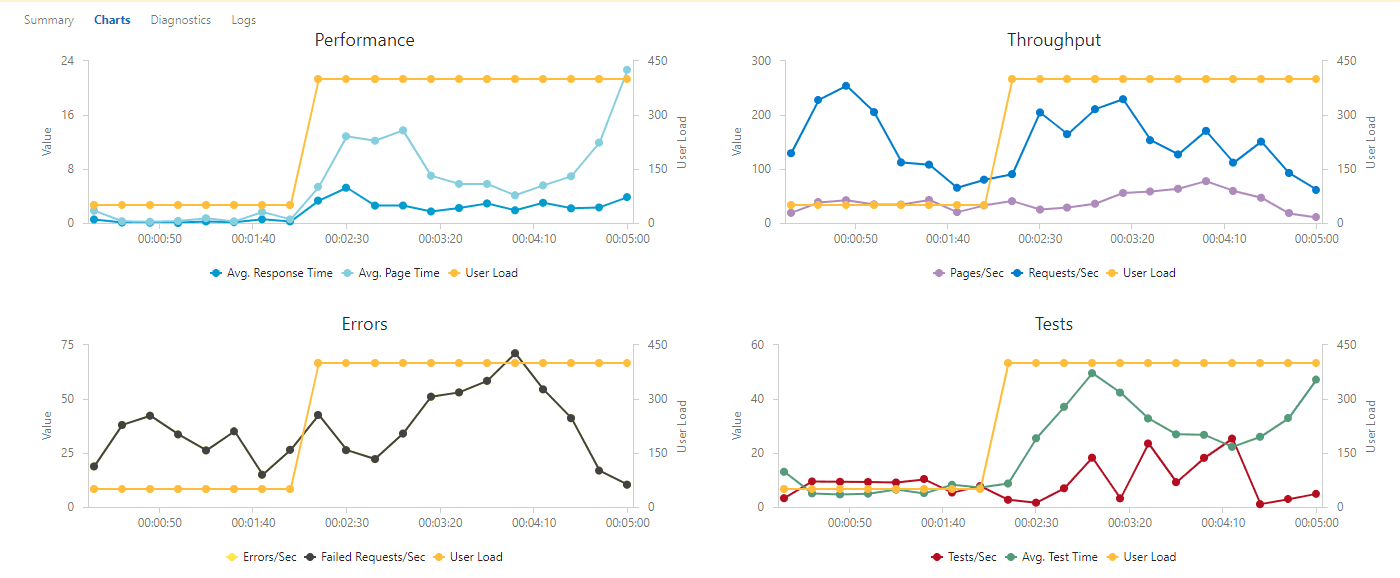
Dans la section Diagnostics (accessible aussi en cliquant sur Errors à partir de longlet Summary), je peux visualiser entre autres, les erreurs qui se sont produites durant les tests, leur typologie (type (1) et sous-type (2)), loccurrence des erreurs ou le nombre de fois quelles se sont produites (3), ainsi que les derniers messages derreurs enregistrés (4).
Les messages de type Threshold indiquent que des violations de seuil ont été franchi pendant lexécution des tests. Je peux voir la valeur seuil ainsi que la valeur de dépassement qui a été enregistrée pendant le test. Les règles prédéfinies de seuil permettre de surveiller lutilisation des ressources du système. Le principe des règles de seuil consiste à comparer la valeur du compteur de performance de notre application avec une valeur constante prédéfinie. Les règles de seuil ont deux niveaux dalerte possibles : Warning et Critical. Une violation de seuil indique quun compteur de performance a enregistré une valeur en « sur » ou « sous » performance eu égard aux règles de
seuil prédéfinies.
Longlet Logs fournit les logs provenant de lensemble des agents qui ont généré les tests. Ces logs disponibles au format .har (HTTP archive) permettent davoir le détail des erreurs rencontrées lors des échanges simulés entre le navigateur et lapplication. On peut visualiser le détail de chaque requête ainsi que la réponse à cette dernière.
Tests de charge avec paramètres
Je peux également effectuer des tests de charge avec des paramètres. Voici les étapes à suivre : - Allez sur lurl de son application - Cliquer sur F12 puis sur longlet Network (1) - Sur votre application cliquer sur la fonctionnalité que vous souhaitez tester - Dans la colonne Name (2) de la fenêtre F12, cliquer sur la fonction que vous souhaitez tester - Exploiter lensemble des informations sur la droite pour compléter les paramètres de test dans Azure DevOps
Exemple dune méthode Get Au niveau du navigateur
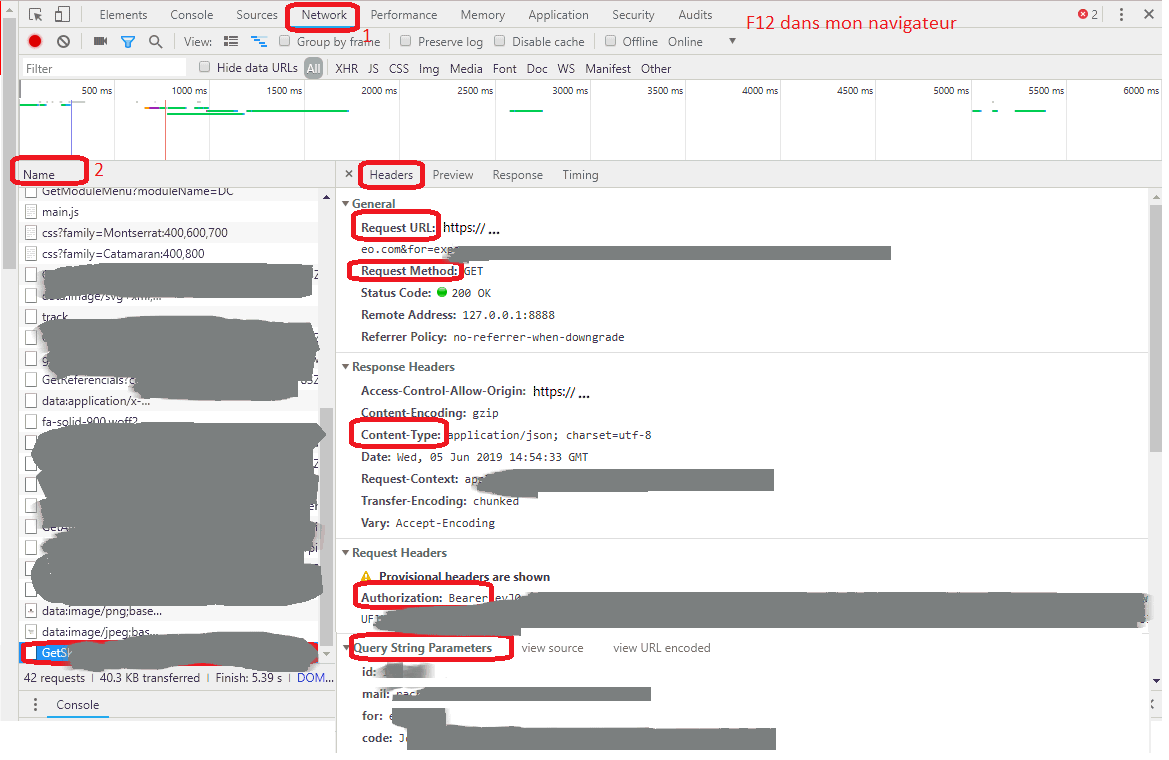
Au niveau d'Azure DevOps
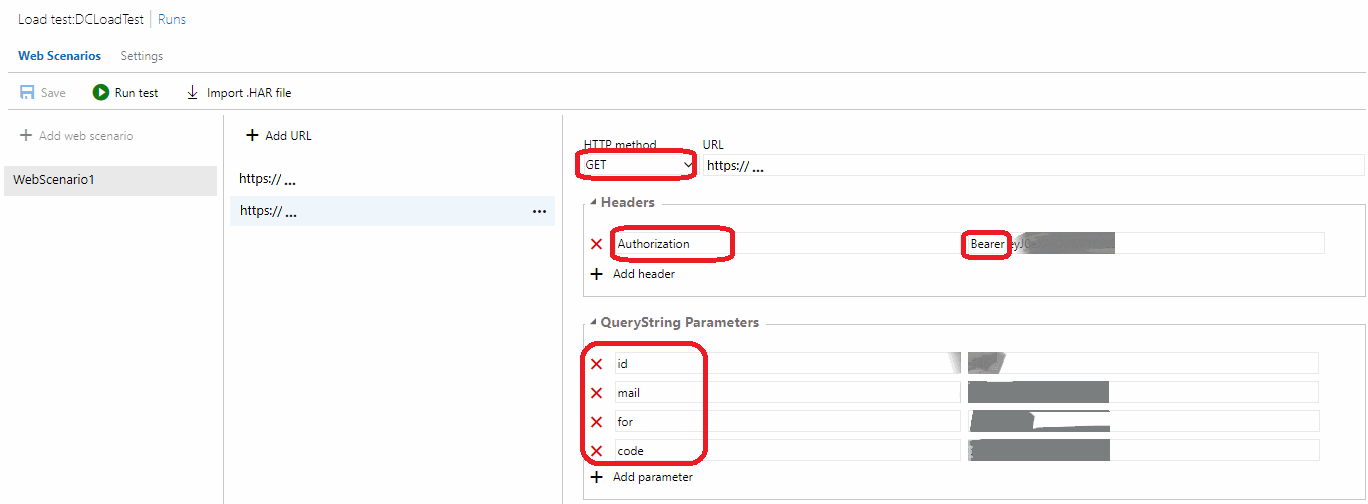
Exemple dune méthode Post
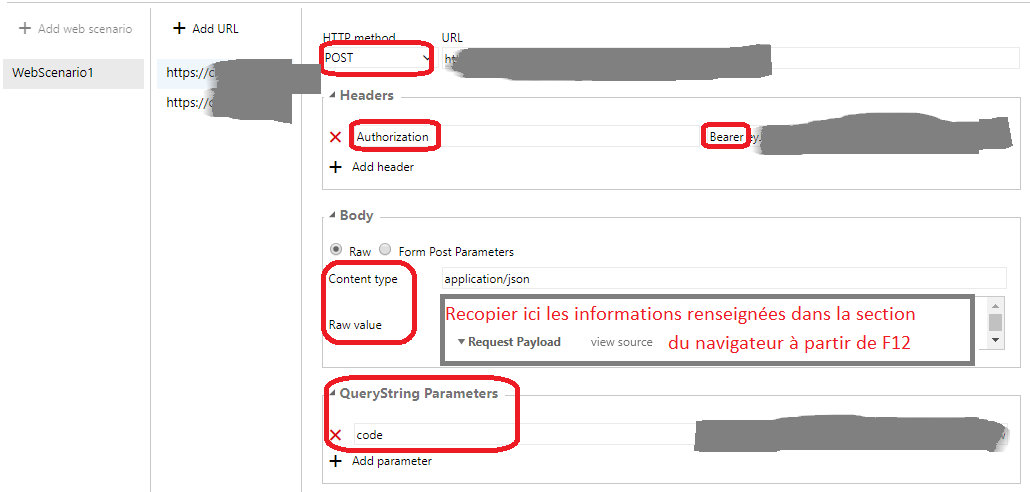
Lobjectif final de la mise en place de tests quels quils soient est didentifier des problèmes en amont pour éviter à tout prix que ce s oit lutilisateur final qui les remonte. Ensuite, il faudra définir un niveau de criticité pour les dysfonctionnements rencontrés. Ceci permettra de prioriser les actions à mettre en uvre pour les corriger. De manière générale, il est donc préférable de tester le site en cours de développement et non pas la version mise en production.
réf: test de charge
https://lesdieuxducode.com/blog/2019/6/tests-de-charge-et-de-performance-avec-azure-devops
---load-tests
1.13. Architectures micro-services
Les applications devenant de plus en plus riches en fonctionnalités et plus complexes, la maintenance de toute lapplication dans un seul block de code était pénible, ce qui a poussé les développeurs à adopter des best practices. Notamment écrire des petits modules chargés de faire quelques fonctionnalités, et construire lapplication à partir de ces modules. Un module indépendant peut être utilisé dans une autre application et ainsi de suite. La gestion de la complexité nétait plus un problème. Mais, on devait quand même tout compiler et installer sur une seule machine. La mémoire et la puissance de calcul dun seul ordinateur étant limité, les gens se penchaient de plus en plus vers les applications web, où on a besoin que d'un navigateur internet. Les développeurs devaient donc écrire les applications en plusieurs modules indépendants. Ils compilaient et déployaient le tout sur un serveur que lutilisateur peut joindre avec son navigateur. Cest ce quon appelle larchitecture monolithique.
La seule façon daccroître les performances dune application conçue en architecture monolithique, suite à une augmentation de trafic par exemple, est de la redéployer plusieurs fois sur plusieurs serveurs. Or, dans la majorité des cas, on a besoin daugmenter les performances dune seule fonctionnalité de lapplication. Mais en la redéployant sur plusieurs serveurs, on accroîtra les performances de toutes les fonctionnalités, ce qui peut être non-nécessaire et gaspiller les ressources de calcul.
Un micro-service est une application destinée à faire une seule fonctionnalité. Par exemple, une application qui envoie un texte à une adresse mail peut être un micro-service. Cest une seule brique de lapplication globale, une brique indépendante ayant une seule responsabilités indépendante. Une équipe peut travailler de façon libre et autonome sur un micro-service, le concevoir à leur choix, le coder avec un langage de programmation quils sélectionnent eux-mêmes et le déploient sur le serveur quils veulent. Puis ils fournissent le micro-service en tant quAPI par exemple. Lapplication globale sera par la suite la combinaison et lintégration de tous les micro-services.
Les bénéfices dune telle architecture
Chaque équipe peut travailler sur un micro-service séparément sans se soucier de larchitecture globale. Cela permet aux nouveaux arrivés de sintégrer facilement car ils nauront quà lire et comprendre le micro-service sur lequel ils travailleront au lieu de se documenter sur toute lapplication. Cela pouvant être pénible sil sagit dune application de grande taille. Lajout des nouvelles fonctionnalités devient très rapide ainsi que la localisation des
Larchitecture en micro-services permet daugmenter les performances dune façon efficace. Si on a besoin quune fonctionnalité soit plus performante, il suffit de répliquer le micro-service correspondant, et de le déployer sur plusieurs serveurs tout seul. Ainsi, on évitera de répliquer toute lapplication à chaque fois quun de ces composants est en manque de ressources.
Les difficultés
**Tests plus compliqués ** Comme tout micro-service doit être indépendant et séparé du reste de lapplication, les tests doivent lêtre aussi. Cela signifie que tout appel à un autre micro-service doit être moqué avec du code se comportant comme tel. Les moques doivent ainsi être maintenus au même comportement du micro-service tiers, et toute différence avec celui-ci peut laisser passer des bugs inaperçus en production.
Latence du réseau Les appels entre micro-service se font à travers le réseau ; des appels HTTP par exemple, ce qui est beaucoup plus lent que des appels de fonction dans des modules. Parfois on peut même faire face à des appels qui naboutissent pas ou qui échouent, cela est impossible en monolithique.
Partage des données En architectures micro-services, il faut faire très attention à la synchro des données entre les différents réplicas dun micro-service, car il y aura toujours
un accès concurrent aux données. Par ex, deux instances du service modifient une donnée en même temps, ou alors un changement de configuration traité par une instance doit être communiqué à tous les autres réplicas.
Monitoring Le monitoring est plus facile en monolithique quen micro-services. Il faut mettre en place un agent de monitoring sur chaque serveur hébergeant un micro-service et surveiller le trafic de chacun dentre eux. En passe de la surveillance dun seul processus monolithe à plusieurs.
Bonnes pratiques
Commencer en monolithique Il est très recommandé de commencer dabord par un design monolithique et de séparer les micro-services petit à petit, en fonction de notre vision des futures fonctionnalités et du trafic de la production. Cela permet de réduire le nombre de micro-services et de bien choisir les services à séparer.
Vérifier lindépendance des micro-services Pour minimiser la dépendance entre micro-services et par suite le partage des données entre eux, chaque micro-service doit avoir une seule responsabilité bien définie et ne contenir que les fonctionnalités liées à celle-ci.
Stabiliser le contrat dinterface Linterface API de chaque micro-service doit changer le moins possible afin de garder lindépendance et ne pas perturber le travail sur les micro-services dépendant de celui-ci. Alors si on se trouve obliger de faire évoluer linterface API, il est très recommandé de garder la compatibilité avec lancienne version ou alors de lancer et synchroniser les deux versions en parallèle pendant une durée suffisante. Cela permettra aux autres équipes de migrer vers la nouvelle version.
Exemple
Use case
Imaginons quon souhaite développer une application qui joue le rôle dun marché
de vente de produits en ligne. Pour simplifier, les produits sont disponibles
chez des fournisseurs, et leur manipulation seffectue par des appels API sur
leurs serveurs. Notre application (appelons la speedBuy) doit exposer les
produits aux clients par appel dAPI de voir les caractéristiques dun produit
et pouvoir lacheter. On aura donc besoin de fournir aux clients les trois
end-points suivants :
- GET speedBuy/catalog : lister le catalogue de tous les produits disponibles
- GET speedBuy/details/
La majorité des fournisseurs acceptent les mêmes end-points pour exposer et
vendre leurs propres produits avec json comme format de données. On décide donc
de fournir notre API en json aussi. Cependant le reste des fournisseurs
nacceptent que le format xml, les end-points sont comme suit :
fournisseurX/xmCatalog , fournisseurX/xmlDetails/
Exemples de réponses :
Requête : GET speedBuy/catalog Réponse :
{
"1": {
"nom": "Produit1",
"description": "caractéristique du produit 1",
},
"2": {
"nom": "Produit2",
"description": "caractéristique du produit 2",
},
"3": {
"nom": "Produit3",
"description": "caractéristique du produit 3",
},
...
}
Requête : GET speedBuy/details/3 Réponse :
{
"nom": "Produit3",
"fournisseur": "fournisseur10"
"description": "caracteristique du produit 1",
"prix": 50,
"devise": "EUR",
"note" : 4.5,
"nombre_avis" : 500
}
Requête : GET speedBuy/buy/3 "body" : { "nomAcheteur": "Bob Donut", "Payment": "CB 9999 9999 9999 9999", "adresse" : "123 rue Pierre Paul " } Réponse :
{
"Status": "CONFIRME",
"DelaiLivraison": 2
}
Pour les fournisseurs nacceptant que xml comme format, la dernière réponse par exemple sera comme suit :
Architecture
Si on commence par une architecture monolithique, notre application aura la forme suivante :
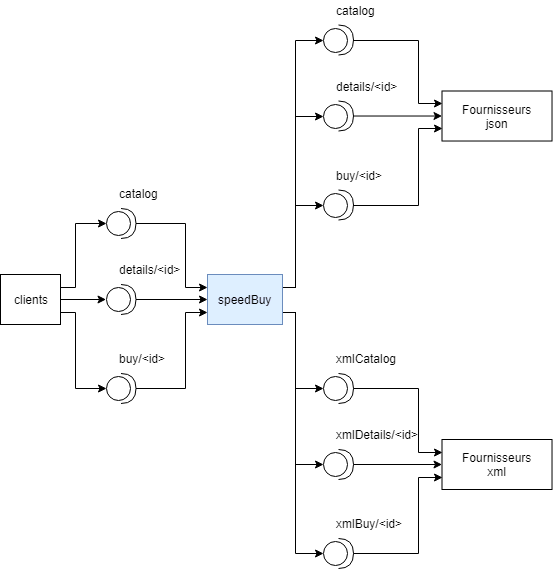
On remarque que le module faisant la transformation de json vers xml, vue sa simplicité, était stable depuis le début et on a dû à chaque fois le redéployer et lancer ses tests avec tout le déploiement de notre application. On décide donc de le séparer de notre application principale pour se contenter de gérer la logique du business sans se soucier de ce module. Commençons par séparer notre premier micro-service, appelons le xmlRouter. Il va être chargé de gérer tout ce qui est lié à la transformation vers xml et doit permettre à speedBuy de se comporter comme si tous les fournisseurs acceptaient json comme format et quil est lun dentre eux. Il fournira donc les mêmes trois APIs dun fournisseur json et se chargera dagréger dans sa réponse toutes les réponses des fournisseurs xml :
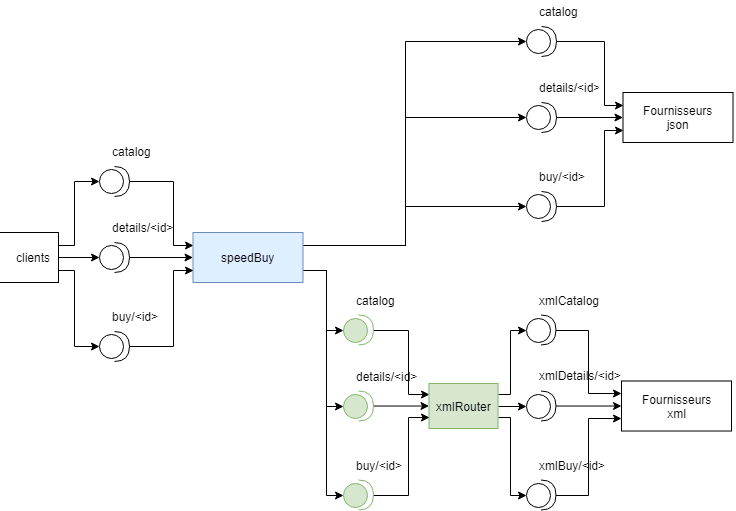
Plus de micro-services
Après quelques mois en production, on reçoit de plus en plus de demandes de
nouvelles fonctionnalités et le trafic dappel API augmente tellement que notre
serveur narrivera plus à absorber dans les mois prochains. Certes on peut
répliquer notre application sur plusieurs serveurs et répartir les charges entre
eux, mais, en analysant le trafic on remarque que le end-point catalog est
appelé trois fois plus que details/
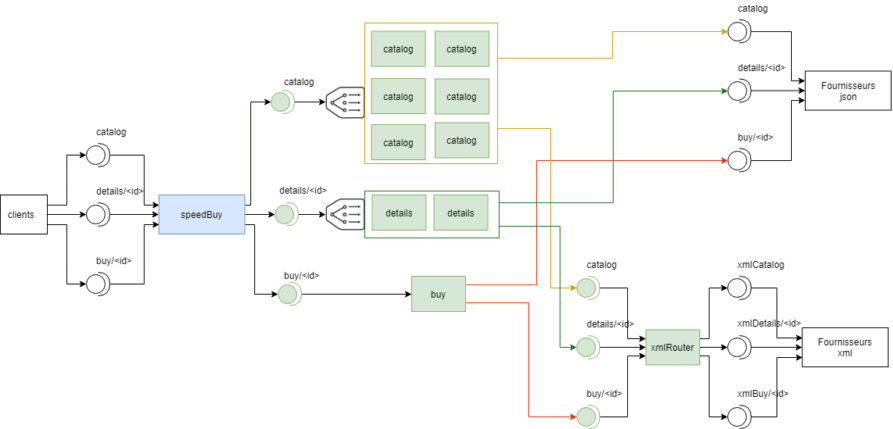
Plus doptimisation
On peut optimiser encore plus lutilisation des ressources physiques en rendant le nombre de réplications de chaque service élastique. Cela veut dire que les serveurs se multiplient au moment du peak et se libèrent quand le trafic diminue
Larchitecture micro-service consiste donc à décomposer lapplication globale en plusieurs composants responsables dune seule fonctionnalité et communiquant en réseau entre eux ainsi quavec les applications tierces. Elle permet un déploiement facile et une utilisation optimisée des ressources de calcul. Cest un modèle darchitecture adopté de plus en plus par les entreprises et continue d'évoluer chaque jour, parmi les évolutions on compte: le modèle Function as a Service ou encore Serverless.
réf: Introduction aux Architectures micro-services
https://blog.invivoo.com/introduction-aux-architectures-micro-services/
CHAPITRE 2 - Azure Fonctions
2.1. Introduction à Azure Functions
Une fonction Azure est déclenché par un évenement et s'execute a ce moment la. Il peux être codé dans le langage de son choix, en C# ou javascript. peut être :
une tache planifiée, que l'on pourrai utiliser pour executer des batchs sur la base de donnée.
une nouvelle donnée, comme un messages qui apparait dans une file d'attente. ou un nouveau fichier uploadé dans un blob storage. La fonction peut envoyer un email par exemple.
une requette http, a chaque fois qu'une url est appelé la fonction Azure est exécuté. Cela peux servir à obtenir une reponse d'un fournisseur de paiement comme stripe par exemple quand on vends un produit en ligne. Ou aussi on peux implementer une API REST.
C'est donc une manière différente d'exécuter du code que dans une VM. Avec une VM on installe ce que l'on veux dessus, on a un contrôle complet du serveur IaaS (Infrastructure as a service), mais ont doit avoir une personne dédié pour gérer les mises à jours, augmenter le nombre de VM, et équilibrer la charge, entre les VM, afin d'assurer le bon fonctionnement de l'application en production. Ce qui serai bien serai de confier cette responsabilité à Microsoft, et de lui demmandé de gérer notre service pour pouvoir se concentrer sur le développement.
Différence avec Azure App Service PaaS (Platform as a Service)
Contrairement au VM, le fournisseur cloud assume la responsabilité de la gestion et de la correction des serveurs, et il y a juste à fournir le code votre site ou des taches qui s'exécutent en arrière plan. Les applications Web Azure s'executent sur Azure App Service, et sont faciles à déployer. Elles sont faite dans une technologie au choix : .NET Core, Node.js ou PHP. Elles sont hébergés avec un plan d'hébergement, ce qui en gros permet d'heberger plusieur sites sur un seul serveur, ou utiliser un serveur dédié, et de pouvoir activer la mise à l'échelle automatique, si votre application est en forte demande. Azure App service permet d'executer des taches en arrière plan.
Azure Functions utilise le SDK des Web Jobs, et est hébergé sur la plate-forme App Service. Il a été créé en 2016 et maintenant, est en version 2. Azure Functions permet un modèle de programmation simplifié, sans avoir a coder le code standard pour connecter ses événements. Azure Functions offre un modèle de tarification en fonction de la demande que quand le code est exécuté, et avec mise à l'échelle automatique. Ce qui est plus economique que d'avoir a payer en permanance même s'il n'y a pas de demande. En effet au lieu d'utiliser le "App Service Plan", on peut choisir le "Consumption" plan, ou on paye selon le nombre d'executions, et le nombre de secondes que la fonction tourne multiplié par la quantité de RAM allouée. Les unités de facturation sont donc exprimées en GB/s secondes. La bonne nouvelle c'est que vous bénéficiez d'une subvention mensuelle gratuite, qui représente actuellement 1 million d'exécutions et 400 000 GB/s. Ainsi vous pouvez obtenir beaucoup avec Azure Functions sans rien payer du tout. Et même en dépassant la limite gratuite, le prix reste raisonnable.
Le plan d'execution limite le temps d'execution à 5 min. Il est aussi possible de définir un quota quotidien maximum. Mais selon vos besoin vous pouvez décider de rester sur le App Service Plan qui revient à un hebergement dédié sans limite de temps pour vos fonctions. Biensur les options tarifaire peuvent changer alors allez voir sur cette page:
réf: Consumption plan
https://azure.microsoft.com/en-us/pricing/functions/
réf: App Service Plan:
https://azure.microsoft.com/en-us/pricing/details/app-service/windows/
Avec les options FREE et SHARED de "App Service Plan", on ne peux pas héberger les applications Azure Functions. Il faut l'option BASIC ou supérieur.
Le runtime Azure Function est disponible en tant que conteneur Docker. Ce qui veux dire que vous pouvez exécuter une application azure sur n'importe quel ordinateur capable d'exécuter Docker. Y compris les centres de données sur site (On premises) ou chez d'autres fournisseurs de cloud. Et si vous choisisez cette
option le prix correspondra simplement à ce que vous payez pour votre hôte conteneur. Il est possible de créer des fonctions en codant directement sur le portail Azure. Azure Function comprend un ensemble très riche de fonctionnalités provenant de Azure Web Apps: intégration continue, le portail Kudu, easy auth, certificats SSL, nom de domaine personnalisés, paramètres d'application, mise à l'échelle automatique, et cela sans aucun serveur à maintenir avec l'option consommation.
C'est le concept de l'informatique sans serveur ou serverless en anglais. Des plateformes similaires sont proposé chez d'autres fournisseurs cloud comme AWS lambda. En fait le concept c'est de déléguer la gestion et la maintenance de nos serveurs à des tiers et ainsi vous vous fiez, dans la mesure du possible, à une plate-forme tierce ou aux offres Backent en tant que service. Par exemple utilisez "Azure Cosmos DB" pour votre base de données, au lieu d'utiliser votre propre serveur de base de données sur une VM, ou en utilisant Auth0 pour votre authentification. Et il existe un nombre croissant de services qui répondent à de nombreux besoins courants des applications cloud modernes; journalisation, envoi d'email, de recherche ou de paiement. Et vos fonctions en tanq que service appelé FaaS ou Fonctions en tant que service.
Fonctions en tant que service (FaaS)
Par exemple une petite application Web pour la vente de bougies; au départ le serveur générer les pages, et implémenter un web-hook, pour le fournisseur de paiement. Puis on rajoutte une demande d'avis sur la vente, puis on génére des statistiques, etc. L'application web peut vite grossir, et le jour on l'on souhaite changer le site avec wordPress par exemple, on se rend compte que l'on est avec une architecture monolithique difficile à adapter. Les applications serverless permettent de casser des morceaux de ce monolithe, en utilisant un ensemble de fonctions faiblement couplées. Cela fait penser à des microservices. Et comme avec les microservices nous avons la liberté de déployer et de les dimentionner indépendamment.
Azure Functions permet de regrouper des fonctions connexes dans une application, qui leur permet de partager des paramètres de configuration et des ressources locales.
Azure Functions est très utile pour expérimenter, automatiser les process, avoir une croissance indépendante, communication entre différents systèmes.
Il se pourrai que votre application web soit martelé par de grands volumes de demandes provenant probablement d'une IP en Europe de l'Est. Sans doute des botnets; des machines légitimes infectées par des logiciels malveillants agissant au nom d'une partie malveillante. Azure capture un petit instantané des fichiers journaux (format etendu W3C)
time c-ip cs-uni-stem sc-status user-Agent
07:37:29 95.85.69.64 /api/breachedaccount/Jilber@bk.ru 404 Mozilla
07:37:29 95.85.69.64 /api/breachedaccount/jolbur@bk.ru 404 Mozilla
07:37:29 95.85.69.64 /api/breachedaccount/jom@bk.ru 404 Mozilla
07:37:29 95.85.69.64 /api/breachedaccount/jolber@bk.ru 404 Mozilla
Le logiciel malveillant peux adapter activement les modèles de demande, pour éviter les mesures anti-abus. Ils proviennent tous de la même adresse IP russe, tous sur le domaine bk.ru qui redirige vers le service de messagerie mail.ru . On peux observer un trafic soutenu depassant les 60 000 rpm requêtes par minute. N'oubliez pas que chacun d'entre eux recherche 1,3 milliard d'enregistrements et que lorsque vous le faites mille fois par seconde, cela consommera beaucoup de frais généraux pour le prendre en charge. Cela nuisait aux performances, à mon portefeuille et à la disponibilité. Le trafic arrivait si fort et si vite, je n'ai pas pu évoluer assez rapidement. La raison en est que je configure l'infrastructure Azure pour une mise à l'échelle automatique quand le processeur dépasse les 80% et pendant 10 min. Lorsque vous êtes soudainement frappé par une charge qui nécessite de nombreux serveurs supplémentaires, certaines de ces requêtes entraînent des erreurs. Au plus fort, je voyais 125 000 requêtes par minute et lorsque ce volume de trafic est soudainement projeté à une échelle qui ne sert que "seulement" des milliers de requêtes par minute, vous allez avoir des problèmes. Et ce n'est pas cool.
J'ai fait quelques ajustements à différents points pour pouvoir absorber le trafic. Mais ce trafic n'est plus un abus d'API, c'est une tentative de DDoS. Une attaque en déni de service ou DDoS vise à rendre inaccessible un serveur afin de provoquer une panne ou un fonctionnement fortement dégradé du service. C'est pourquoi la limite de débit a été introduite tôt. En limitant les requêtes à une toutes les 1.5 s, puis en renvoyant HTTP 429 au-delà de cela, la limite de débit signifiait qu'il n'était plus utile de marteler le service. Cependant on voit avec CloudFlare qu'ils ont transmis 97% des demandes à mon site. L'un des avantages d'avoir CloudFlare devant le site est qu'il ouvre des options sur la façon de gérer le trafic en amont de votre serveur. Par ex, vous pouvez bloquer une adresse IP purement et simplement. Et ils ont une API pour le faire. Et bien qu'il y ait un tas d'adresses IP abusives, je peux les identifier par programme.
Utilisons une fonction Azure pour prendre des adresses IP abusives et les soumettre à CloudFlare pour qu'elles soient bloquées. Mon application Web décide déjà quand une adresse IP est abusive, puis la dépose dans une file d'attente de stockage Azure.
réf: Have I been pwned (HIBP)
https://www.troyhunt.com/azure-functions-in-practice/
2.2. Première fonction Azure
Fonction Azure CSharp
Nous allons choisir Webhook pour une fonction qui peut être déclenché par une requête http. Nous pouvons aussi choisir entre C# et javascript, qui sont les 2 langages les mieux supportés par azure functions (mais d'autres langages sont aussi pris en charge). Quand on clique sur Create this function on est redirigé vers une page qui affiche mon application qui contient la fonction que nous venons de créer.

En haut à gauche on peut voir le nom de l'application qui a été généré aléatoirement. Cette application ne possède qu'une seule fonction appelé HttpTriggerCSharp1.
Et à droite on voit le corp de la fonction qui se trouve dans un fichier run.csx . L'essentiel est que cette méthode sera exécuté à chaque fois que notre fonction sera déclenchée. Et lorsque la fonction sera déclenché elle essaie de trouver un paramètre de chaine de requête appelé "name". Et si cela n'a pas été fourni, il va voir si le corp de la requête contient un "name". Ensuite si aucun nom n'a été trouvé une réponse HTTP 400 incorrecte sera renvoyée. Mais si vous avez fourni un nom, nous renvoyons 200 OK avec un message Hello dans le corp de la réponse. Si nous voulions, nous pourrions éditer cette fonction ici. Evidemment vous ne voudriez pas écrire votre code de production sur le portail Azure, mais comme moyen rapide d'essayer Azure Functions, c'est vraiment
pratique.
Si je développe cet onglet Afficher les fichiers à droite, je peux voir les fichiers qui composent cette fonction. Le fichier function. json est important car il défini que fonction Azure dans une application de fonctions. Il définit des choses importante comme évènement qui va déclenché la fonction ("type": "httpTrigger"), les méthodes prises en charge (get et post), et il dit que cette fonction a un niveau d'autorisation "function". Ce qui signifie que seules les personnes connaissant un code secret spécial peuvent l'appeler. Normalement vous n'avez pas besoin de générer l'un de ces fichier function.json vous-même.

L'éditeur nous permet ajouter du code avec +Add. Nous pourrions donc mettre plus de fichiers C# si nous le voulions. Bien que l'esprit d'Azure Functions consiste à garder votre code de fonction aussi petit et léger que possible.
Il existe également une fenêtre de test très pratique, ce qui nous permet de déclencher notre fonction très facilement. Et de voir le log.


Bien sur, puisqu'il s'agit d'une fonction déclenchée par HTTP, je n'ai pas à utiliser cette fenêtre de test, il me suffit de cliquer sur Get function URL pour pouvoir l'appeler de n'importe où. Le domaine de l'url est composé du nom d'application de la fonction généré de manière aléatoire, suivi de azurewebsites. net, /api, nom de la fonction, et avec en paramètre le code de sécurité que nous devons fournir, ou nous obtiendrons une réponse 401 non autorisé.

en copiant l'url suivi du paramètre &name=aname, dans le navigateur, on obtient la même réponse.
Fonction Azure Javascript
Une application de fonction Azure peut contenir de nombreuses fonctions. Dans le menu de gauche sélectionner Functions, une icone plus apparait. Cliquez dessus pour créer une nouvelle fonction. Et vous pouvez voir qu'il y a une foule d'options pour différents types de fonctions que nous pouvons créer.

Voyons maintenant quelques-uns des types de déclencheurs les plus courants disponibles dans Azure :
Timer Trigger: Ce déclencheur est appelé selon un calendrier prédéfini. Il permet de définir l'heure d'exécution de l'Azure Function.
Blob Trigger: Ce trigger est déclenché lorsqu'un nouveau blob ou un blob mis à jour est détecté. Le contenu du blob est transmis en tant qu'entrée à la fonction.
HTTP Trigger: Ce déclencheur est utilisé pour l'instrumentation des applications, l'expérience utilisateur, le traitement des flux de travail et l'Internet des objets (IoT). Ce déclencheur est déclenché lorsqu'un événement est transmis à un Azure Event Hub.
Déclencheur HTTP : Ce déclencheur est activé lorsqu'une requête HTTP est émise.
Queue Trigger : Ce déclencheur est déclenché lorsque de nouveaux messages arrivent dans une file d'attente Azure Storage.
Generic Webhook : Ce déclencheur est activé lorsque les requêtes HTTP du Webhook proviennent de n'importe quel service prenant en charge les Webhooks.
GitHub Webhook : Ce déclencheur est activé lorsqu'un événement se produit dans vos dépôts GitHub. Le référentiel GitHub prend en charge des événements tels que Branch created, delete branch, issue comment et Commit comment.
Service Bus Trigger : Ce déclencheur est activé lorsqu'un nouveau message provient d'une file d'attente ou d'un sujet du bus de service.
Prenons un exemple simple : nous devons afficher un message "Bonjour" à l'écran toute les 5 min. Cette situation est liée au temps, et nous devons donc utiliser un déclencheur d'horaire. Commençons par créer une fonction avec le Timer Trigger, pour cela cliquer sur le langage que vous souhaitez utiliser.

Une chose importante est que si nous avons pu créer une fonction Javascript a
coté d'un C #, c'est que l'on est toujours sur la version 1 de Azure Funtions, ce qui vous permet de combiner plusieurs langues dans la même application de fonction. Avec la version 2 d'Azure Functions, le mode d'extensibilité de la langue a été réécrit, ce qui offre de meilleurs performances, mais au prix coutant que vous devez choisir un seul runtime pour votre application de fonction. Sur la page de ce lien vous pouvez voir les différences entre les différentes version d'Azure Functions:
https://learn.microsoft.com/fr-fr/azure/azure-functions/supported-languages

Ici nous pouvons définir une expression cron, et ci dessous le code de la fonction. Lorsque la minuterie se déclenche, notre fonction est appelée.
module.exports = function (context, myTime) {
var timeStamp = new Date().toISOString();
if(myTimer.isPastDue)
{
context.log('Javascript is running late !');
}
context.log('Bonjour', timeStamp);
context.done();
}
Cette fonction est capable de détecter si l'appel de la fonction était en retard pour une raison quelconque. Dans les fonctions javascript vous recevez un objet de contexte que vous pouvez utiliser pour consigner des messages. Et vous appelez done sur le contexte lorsque votre fonction est terminée. Cette fonction a également un fichier function.json
{
"bindings": [
"name": "myTimer",
"type": "timerTrigger",
"direction": "in",
"schedule": "0 */5 * * * *"
],
"disabled": false
}
Fonction Azure avec le portail Azure
Cliquer sur le bouton plus "Create a ressource"

Sélectionner la catégorie "Compute" et cliquer sur "Function App"

Choisir le système d'exploitation Windows ou Linus, le plan d'hébergement;
Consumption Plan : qui utilise le modèle de facturation sans serveur.
App Service Plan : qui permettrait d'héberger cette application fonctionnelle sur tous les services d'applications que j'ai déjà créés dans cet abonnement.
Nous allons utiliser les machines virtuelles déjà affectées au plan de service d'application pour exécuter les fonctions en amont. Cependant, dans la plupart des cas, le choix du plan de consommation a beaucoup de sens car vous pouvez tirer parti de la subvention gratuite, de toute la puissance et de la flexibilité du modèle sans serveur. Si je choisis le plan de consommation, je dois choisir un emplacement, situé dans la même région que toutes les ressources que je prévois d'utiliser dans la fonction.
L'option suivante est quelle pile d'exécution nous allons utiliser. Il est attendu que vous utilisiez le même langage pour toutes vos fonction. Donc si j'écris des fonctions C# ou F#, je choisis alors .NET, sinon JavaScript ou Java.
Enfin un compte de stockage sera créé pour vous. Ceci est destiné à Azure Functions pour stocker les informations relatives à votre application de fonction. Il permet d'utiliser un compte de stockage existant, mais je vous recommande de le laisser créer un nouveau compte de stockage.
Pous pouvez également voir qu'il est proposé de créer une "Application Insights", qui stockera les informations de journal et de diagnostic.
Après avoir créer la fonction nous recevons une notification nous informant que le déploiement est terminé. Lorsque nous cliquons dessus, sur le bouton "Go to ressource" il nous redirige sur la fonction

Nous voyons des informations de base sur notre application de fonction, y compris l'URL qui sera l'adresse de base de toutes les fonctions déclenchées par HTTP que nous créons.
Commençons par naviguer dans notre groupe de ressources en haut à droite (Ressource group) et voir ce qui a été créé.

Il y a 4 ressources ici:
- funcs1234 l'application de fonction
- funca3fa un compte de stockage
- funcs1234 une instance Application Insights
- WestEuropPlan le plan de service d'application qui régit la tarification, et il s'agit du plan de consommation
Revenons sur notre application de fonction et examinons certains des paramètres. Si je visite l'onglet "Platform Features" vous constaterez qu'il y a un très grand nombre de choses que nous pouvons configurer ici concernant le développement, la mise en réseau, la surveillance, etc.

Comme nous l'avons dit, Azure Functions est basé sur Azure App Service, ce qui signifie que la majorité des fonctionnalités que vous pouvez utiliser avec les applications Web Azure sont également disponibles pour les applications fonctionnelles. Allons voir les paramètres de l'application de fonction.

Cela nous permet d'accéder à certains paramètres clés liés à l'application de fonction dans son ensemble.
Nous avons la possibilité de définir un quota d'utilisation quotidienne, ce qui peut vous protéger contre le versement accidentel d'une facture importante. Et le mode de modification de l'application de fonction, qui s'affiche ici en lecture / écriture, ce qui signifie que nous pouvons créer et modifier des fonctions dans le portail si nous le souhaitons. Mais nous allons écrire notre code de fonction dans un outil d'édition de code standard, puis nous le transmettrons à Azure lorsque nous serons prêts.
Dans cette vue nous pouvons également accéder aux clés secrètes pouvant être utilisées pour appeler nos fonctions ou les renouveler.
Passons aux paramètres de l'application ensuite.

Il y a des paramètres PHP même si ce n'est pas pris en charge, car ces paramètres proviennent de la même plate-forme sous-jacente que les applications Web et prennent en charge PHP. Vous n'avez pas besoin de modifier la plupart des paramètres. La partie la plus pertinente de cette page est la sous section intitulée Paramètres de l'application.

Elle contient les paramètres utilisés par le runtime Azure Functions. Vous pouvez également y ajouter vos propres paramètres, auxquels vous pouvez accéder depuis vos fonctions. Et tout ce qui est défini ici apparaîtra sous la forme de variables d'environnement auxquelles vous pourrez accéder dans votre code. Et ces paramètres incluent des éléments tels que la clé Application Insights, la version du runtime (~2), et le paramètre FUNCTIONS_WORKER_RUNTIME est défini sur dotnet. Vous allez écrire les fonctions C# pour cette application. Et vous verrez également que la chaîne de connexion au compte de stockage que nous avons créé est également présente.
Compte de stockage
Jetons un coup il à ce qu'il y a dans le compte de stockage créé pour notre service d'applications. Et juste pour rendre les choses un peu plus intéressantes, j'ai créé deux fonctions; l'une est déclenchée par HTTP, l'autre est une fonction planifiée et les deux sont en C#
fonction HttpTrigger1
#r "Newtonsoft.Json"
using System.Net;
using Microsoft.AspNetCore.Mvc;
using Microsoft.Extensions.Primitives;
using Newtonsoft.Json;
public static async Task<IActionResult> Run(HttpRequest req, ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
return name != null
? (ActionResult)new OkObjectResult($"Hello, {name}")
: new BadRequestObjectResult(
"Please pass a name on the query string or in the request body");
}
fonction TimerTrigger1
using System;
public static void Run(TimerInfo myTimer, ILogger log)
{
log.LogInformation($"C# Timer trigger function executed at: {DateTime.Now}");
}
Nous allons donc naviguer vers le compte de stockage associé à notre application de fonction. Pour cela cliquer sur l'application, puis cliquer sur le groupe de ressources, et enfin cliquer sur le compte de stockage lui même.

Et il existe une nouvelle fonctionnalité vraiment intéressante dans le portail Azure appelée Storage Explorer, qui nous permet de consulter un compte de stockage.

Nous pouvons constater qu'il existe deux conteneurs d'objets blob, qui sont utilisés par le moteur d'exécution Azure Functions pour la conservation de verrous, de minuteries et de secrets.
Il y a aussi un partage de fichiers qui contient dans site/wwwroot, le code de notre application de fonction.

Ce compte de stockage ne contient actuellement aucune file d'attente et aucune table. Mais certaines des fonctionnalités les plus avancées d'Azure Functions, telles que les fonctions durables, peuvent les utiliser.
2.3. Les triggers et les liaisons
Il existe des types de déclencheurs supplémentaires pris en charge dans Azure Functions, telles que la réponse à des messages de file d'attente ou de nouveaux éléments apparaissant dans le stockage d'objets blob, et même l'ajout de nouveaux documents à une base de données Cosmos DB.
Outre les déclencheurs, Azure Functions fournit des liaisons d'entrée et de sortie, ce qui facilite la connexion de vos fonctions à toutes sortes de ressources externes.
Que votre fonction ait besoin de poster un message dans une file d'attente ou d'écrire un fichier sur le stockage d'objets blob ou d'envoyer un courrier électronique, les liaisons peuvent réduire considérablement la quantité de code que vous devez écrire pour atteindre cet objectif. Nous allons créer une série de fonctions qui fonctionneront ensemble en tant que pipeline de traitement des commandes, et voir les outils principaux de l'API Azure Functions, qui constituent un ensemble d'outils en ligne de commande multi plate-forme nous permettant de développer nos fonctions Azure sur n'importe quelle plateforme.
Cette page de documentation sur learn. microsoft.com donne une idée de tous les différents déclencheurs et liaisons pris en charge par Azure Functions.
https://learn.microsoft.com/fr-fr/azure/azure-functions/functions-triggers-bindings?tabs=csharp
Si on descend jusqu'à la section Supported bindings ou Liaisons prises en charge en francais, nous constatons qu'il existe de nombreux déclencheurs et liaisons pris en charge. Certains de ces déclencheurs, tels que HTTP et EventGrid, ont un caractère très général, vous permettant ainsi une intégration aisée avec la plupart des systèmes externes, même si ce n'est pas Azure de manière native. Depuis cette page vous pouvez explorer individuellement chacun de ces différents types de liaison et découvrir toutes les options disponibles pour votre langage de préférence, si j'accède à la liaison de base de données CosmosDB, nous verons qu'une page explique comment les liaisons fonctionnent avec les versions 1 et 2 d'Azure Functions. Et si nous regardons la page de la version 2, nous verrons que des exemples sont fournis, non seulement en C#, mais également pour les autres langages pris en charge. C'est donc une référence très complète.
Nous allons réaliser une fonction d'un cas réél, ou un fournisseur de paiement a mis en ligne un point d'accès au Web qui a posté un message dans une file d'attente. Et lorsque ce message a été traité, il a déclenché la création d'un fichier de licence.

2.4. Développer des fonctions Azure
Il existe 2 manières d'écrire des fonctions C#. Avec une bibliothèque de classe C# et un script C# comme nous avons fait jusqu'à maintenant. Les fichiers de script C# sont compilés à la volée et se prêtent bien à la programmation dans le
portail. Cependant ce n'est pas l'approche la plus efficace pour exécuter des fonctions C#. Il est préférable de précompiler vos fonctions dans une DLL, et c'est l'approche de la bibliothèque de classes.
Avec cette approche vos fonctions sont créées dans un projet C# standard compilé dans une bibliothèque .NET Core. Et avec cette approche un fichier function.json sera automatiquement créé pour chacune de vos fonctions et pointera sur la méthode de la DLL qui implémente votre fonction. C'est cette approche que nous allons utiliser pour le reste de ce cours. Pour cela vous avez besoin de Visual Studio 2017 ou plus récent avec la charge de travail développement Azure. Vous pourrez ensuite créer un projet Azure Functions exécuter et le déboguer localement..
https://learn.microsoft.com/fr-fr/azure/azure-functions/functions-dotnet-class-library?tabs=v4%2Ccmd
Le développement d'Azure Functions peut également être réalisé sur plusieurs plates-formes à l'aide des outils d'Azure Functions. Celles-ci vous offrent une expérience de ligne de commande qui simplifie la création de nouvelles applications avec des templates, ainsi que d'autres tâches utiles, telles que le déploiement de votre application. Et si vous envisagez d'utiliser ces outils pour développer des applications de fonctions C# de bibliothèques de classes, vous devez également vous assurer que vous avez installé le SDK .NET,
j'utiliserai également VS Code, un éditeur de texte multi-plateformes, qui propose un excellent support de développement de fonctions Azure. Une fois tous les outils installés vous pouvez vérifier leur fonctionnement en tapant "func version" dans la console. la commande "func" affiche les sous-commandes disponibles.
func version
dotnet --info
Dans le cas ou la commande dotnet n'est pas reconnue, vérifier que la variable d'environnement PATH contient bien le chemin "C: \Program Files\dotnet", et si besoin lancer dotnet directement depuis ce chemin pour qu'il s'initialise.
Utilisons les outils de Azure Functions pour créer une nouvelle application de fonction. Dans un nouveau dossier lancer la commande "func init" qui crée une nouvelle application de fonction.
C:\code\testfunc>func init
Use the up/down arrow keys to select a worker runtime:
dotnet
dotnet (isolated process)
node
python
powershell
custom
Le programme nous demande de sélectionner le runtime de travail que nous aimerions, et je vais donc choisir Dotnet, puis le langage C#.
Maintenant si nous examinons ce qui a été créé
/testfunc |- /.vscode |- /Properties |- launchSettings.json |- .gitignore |- host.json |- local.settings.json |- testfunc.csproj
- host.json permet de stocker certains paramètres de configuration de fonction,
- local.settings.json permet de stocker les paramètres que vous souhaitez utiliser lors de l'exécution locale.
Vous remarquerez qu'il existe également un dossier .vscode qui contient certains paramètres destinés à Visual Studio Code pour qu'il installe des extensions utiles au développement Azure Functions. Ouvrons donc ce dossier dans VSCode avec la commande "code . " VSCode propose alors d'installer les extensions recommandées (C# et Azure Functions).
Pour ajouter une nouvelle fonction à notre application de fonction, nous devons simplement taper "func new"
C:\code\testfunc>func new
Use the up/down arrow keys to select a template:
QueueTrigger
HttpTrigger
BlobTrigger
TimerTrigger
KafkaTrigger
KafkaOutput
DurableFunctionsOrchestration
SendGrid
EventHubTrigger
ServiceBusQueueTrigger
ServiceBusTopicTrigger
EventGridTrigger
CosmosDBTrigger
IotHubTrigger
Avec l'extension PowerShell appelé PoshGit, on peut voir les informations Git dans mon répertoire, telles que la branche ou je suis, et combien de fichiers sont actuellement modifiés.
Cela nous donne la possibilité de sélectionner un modèle de fonction. Ce qui nous donnera un aperçu rapide de la syntaxe nécessaire pour chacun de ces types de déclencheurs, et qui installera tous les packages NuGet supplémentaires nécessaires pour prendre en charge les déclencheurs. Maintenant pour cette fonction, nous avons juste besoin d'un déclencheur HTTP, que nous allons utiliser pour recevoir le raccordement Web de notre fournisseur de paiement. Je vais nommer cette fonction OnPaymentReceived. Une fois la fonction Azure créé un nouveau fichier OnPaymentReceived.cs est créé.
Attention C# pour VSCode (créé par OmniSharp) a tendance à s'embrouiller si nous restaurons les dépendances à partir de la ligne de commande plutôt qu'à partir de Visual Studio Code. Cela se traduit par le fait qu'il ne reconnais plus les dépendances comme "Using System", ou "Using Microsoft".
Pour corriger le problème, tapez ctrl + shift + P et taper "Restart Omnisharp", puis restaurez le projet.
namespace testfunc
{
public static class onPaymentReceived
{
[FunctionName("onPaymentReceived")]
public static async Task<IActionResult> Run(
[HttpTrigger(AuthorizationLevel.Function, "get", "post", Route = null)] HttpRequest req,
ILogger log)
{
log.LogInformation("C# HTTP trigger function processed a request.");
string name = req.Query["name"];
string requestBody = await new StreamReader(req.Body).ReadToEndAsync();
dynamic data = JsonConvert.DeserializeObject(requestBody);
name = name ?? data?.name;
string responseMessage = string.IsNullOrEmpty(name)
? "This HTTP triggered function executed successfully. Pass a name in the query string or in the request body for a personalized response."
: $"Hello, {name}. This HTTP triggered function executed successfully.";
return new OkObjectResult(responseMessage);
}
}
}
Nous pouvons voir ici que nous avons une classe statique appelée "OnPaymentReceived", et qu'il existe une méthode statique appelée "Run". Et nous pouvons voir la principale différence par rapport aux fonctions de script C# que nous avons créées sur le portail. Cette approche utilise des attributs pour stocker des informations sur les déclencheurs et les liaisons de la fonction. Il y a un attribut FunctionName. Et comme chaque fonction Azure doit avoir un déclencheur, un attribut HttpTrigger est défini pour le paramètre HttpRequest. Et cet attribut nous permet de configurer divers paramètres pour le déclencheur.
Nous pouvons choisir AuthorizationLevel. Nous allons le laisser comme Fonction, ce qui signifie qu'un code secret sera requis pour appeler cette fonction depuis Azure. Si nous ne le voulions pas et si nous voulions le rendre public, nous pourrions simplement utiliser le niveau anonyme, mais avec cette option nous aurions besoin de partager l'URL complète de cette fonction, y compris le code secret, avec notre fournisseur de paiement pour leur permettre d'appeler notre fonction.
Nous pouvons également spécifier les méthodes HTTP que nous voulons accepter,
https://www.serverless360.com/blog/azure-functions-triggers-and-bindings
https://www.youtube.com/watch?v=Rg8V7fDhfKU
https://www.youtube.com/watch?v=ESBWyBoD8Kc
https://www.youtube.com/watch?v=v72gdzFjXck
https://www.youtube.com/watch?v=rF1AdbeJTyc