
________ __ __ _______
| | | | | | / |
| __ | | | | | | __|
| |__| | | |/\| | \_ |_
| __ | | | __\ \
| | | | | /\ | | |
|__| |__| |__/ \__| |_______/
DevOps avec amazon webservices
aws.md 28/01/2023
ultimecool.com
Sommaire
CHAPITRE 2 - Cloud AWS - Amazon Web Services
2.1. Introduction à AWS
2.2. Premiers pas dans la console AWS
2.3. Créer un serveur facilement avec Elastic Beanstalk
2.4. Introduction aux services d'Amazon EC2
2.5. Choisir le bon type dinstance
2.6. Lancer une instance
2.7. Héberger une application ASP.Net Core sur le cloud AWS via Docker
2.8. héberger une page web
2.9. Sauvegarder et restaurer une instance
2.10. Monter une base de données sur RDS
2.11. Lancer un serveur RDS
2.12. Sauvegarder et restaurer la base de données
2.13. utiliser RDS depuis son serveur web EC2
2.14. Simple Storage Service (S3)
2.15. Définir les droits d'accès à S3
2.16. TP S3 le Cloud Uploader
2.17. IAM
2.18. Déploiement continue avec AWS
CHAPITRE 2 - Cloud AWS - Amazon Web Services
Voici les grandes familles du cloud en allant du plus bas niveau au plus haut:
IaaS (Infrastructure as a Service) : un prestataire vous fournit un accès à tout ou partie de son infrastructure technique, cest-à-dire à ses serveurs.
on vous fournit non seulement un accès à linfrastructure, mais on soccupe aussi de gérer le nombre de machines nécessaires pour que votre application fonctionne bien quelle que soit la charge de trafic. On vous donne aussi accès à des fonctionnalités comme par exemple des bases de données, des serveurs de cache, des serveurs de-mail
PaaS (Platform as a Service) : on vous fournit non seulement un accès à linfrastructure, mais on soccupe aussi de gérer le nombre de machines nécessaires pour que votre application fonctionne bien quelle que soit la charge de trafic. On vous donne aussi accès à des fonctionnalités comme par exemple des bases de données, des serveurs de cache, des serveurs de-mail
SaaS (Software as a Service) : on vous fournit laccès à un logiciel sous forme de service. Avant, vous deviez installer le logiciel sur votre machine (ex : Microsoft Office). Aujourdhui, le logiciel se présente sous la forme dune application web (qui nest rien dautre quune sorte de super site web !). Vous devez juste vous rendre à une adresse et vous pouvez lutiliser (ex : Microsoft Office 365, Google Apps ).
Carractéristiques d'une plateforme PaaS comme AWS :
Le cloud vous permet de commencer gratuitement dans la plupart des cas. Dans le cas d'AWS, vous pouvez utiliser le service un an gratuitement si vous consommez peu de ressources. Vous devriez pouvoir suivre ce cours sans rien payer donc !
Vous navez rien à faire si le trafic de votre site grossit : vous utiliserez automatiquement plus de serveurs (et ferez chauffer votre CB).
Vous navez pas à gérer les problèmes techniques « bas niveau » comme la perte dun disque ou même dun serveur entier. Tout cela est transparent pour vous.
Vous bénéficiez de fonctionnalités très pratiques qui vous évitent davoir à installer et maintenir un serveur de base de données, de-mails, etc. Bref, vous allez gagner du temps dans vos développements !
En revanche :
Vous devez adapter votre site pour quil fonctionne avec les limitations et fonctionnalités offertes par votre PaaS. Il y a des règles à suivre quand vous développez : vous n'êtes par exemple pas censés stocker vos fichiers sur le même serveur que celui qui contient votre site. Il faut les stocker sur d'autres serveurs en faisant appel à un service de stockage.
Si vous voulez changer de prestataire, ça ne se fait pas en claquant des doigts. Il faut parfois recoder tout ou partie de votre site pour quil fonctionne sur un autre PaaS.
Les bugs techniques sont rares mais peuvent toujours survenir, quoique le service marketing veuille bien tenter de vous faire croire. Ne faites pas une confiance aveugle dans votre cloud et demandez des SLA (Service Level Agreement) pour garantir financièrement le bon fonctionnement du site si vous êtes une entreprise et que le site est critique pour vous. Avec des SLA, le fournisseur aura des pénalités si votre site ne fonctionne pas pendant plusieurs heures par sa faute.
2.1. Introduction à AWS
Le Cloud AWS est une plateforme de services cloud développée par le géant américain Amazon. AWS regroupe plus de 50 services répartis en diverses catégories telles que calcul, stockage, base de données, migration, mise en réseau et diffusion de contenu, outils pour développeurs, outils de gestion, sécurité et identité, analyses, intelligence artificielle, services mobiles, services applicatifs, messagerie, productivité dentreprise, streaming de bureau et dapplications, internet des objets, centres dappels, et développement de jeux. Amazon est devenu le leader mondial du cloud computing. Ses services Cloud sont utilisés par des millions dentreprises comme Spotify, Yelp, Shazam, AirBnB Ces ressources sont scalables en fonction des besoins des utilisateurs.
Chaque élément que vous voyez est une catégorie.... et chaque catégorie propose plusieurs services, qui font partie de l'offre globale d'AWS :
Amazon S3
Amazon Simple Storage Service (Amazon S3) permet de faciliter la collecte, le stockage et lanalyse de données à grande échelle. Les données peuvent être collectées à partir de nombreuses sources telles que des sites web, des applications mobiles, des applications dentreprises ou des capteurs dobjets connectés. De nombreux utilisateurs de ce service stockent des milliards dobjets et des exaoctets de données. S3 peut être utilisé comme Data Lake pour les analyses Big Data, comme cible de sauvegarde, ou comme stockage pour les applications de calcul sans serveur. Les données servent aussi lors de lapprentissage automatique avec dautres services AWS.
Amazon DynamoDB : la base de données NoSQL opérée
Amazon DynamoDB correspond à un service de base de données NoSQL réputée pour sa latence très faible de seulement quelques millisecondes. Entièrement gérée dans le cloud, cette base de données prend en charge les différents modèles de stockage de documents. Flexible, performante, dimensionnable en termes de débits et de capacité, cette base de données est adaptée au web, aux jeux, aux technologies publicitaires, à linternet des objets et bien plus encore.
Amazon Redshift : le service dentrepôt et danalyses de données AWS
Redshift est un service dentrepôt de données entièrement géré, réputé pour sa rapidité. Grâce à cette solution, les utilisateurs peuvent analyser de façon simple et économique toutes leurs données. Ainsi, lon exécute des requêtes analytiques complexes sur plusieurs pétaoctets de données structurées. Lon stocke des données en colonnes sur des disques locaux hautes performances. Lon procède à lexécution de requêtes massivement parallèle. Lutilisateur reçoit ainsi plus de résultats à la seconde. Ce service est également entièrement scalable. Avec Redshift Spectrum, il est également possible dexécuter des requêtes SQL sur plusieurs exaoctets de données non structurées dans Amazon S3.
Amazon CloudFront, service de diffusion de contenu
CloudFront est un réseau mondial de diffusion de contenu permettant de distribuer aux utilisateurs des données, des vidéos, des applications et des API de façon sécurisée, sans latence, à une vitesse de transfert élevée.
Amazon CloudSearch, le service de recherche géré
Amazon CloudSearch est un service AWS de recherche géré facilitant la configuration, la gestion et le dimensionnement dune solution de recherche pour un site web ou une application. Compatible avec 34 langues différentes, ce service a lavantage dêtre économique, et propose des fonctionnalités telles que la mise en surbrillance, le remplissage automatique ou la recherche géolocalisée.
Amazon Machine Learning, un service dapprentissage automatique
Ce service facilite lutilisation des technologies de Machine Learning pour les développeurs. Les outils et assistants de visualisation permettent de créer des
modèles dapprentissage-machine sans avoir besoin de maîtriser les algorithmes et technologies complexes. Amazon Machine Learning permet ensuite dobtenir facilement des prédictions pour une application sans avoir besoin dappliquer de codes de génération de prédictions personnalisés ou de gérer une infrastructure.
Parmi les autres services les plus utilisés dAWS, on compte les services de base de données relationnelle Amazon Aurora et Amazon RDS, les ressources de cloud isolées Amazon VPC, les services de gestion dapplications Amazon Elastic Beanstalk, le service de migration Amazon Migration Hub, ou encore le moteur de jeu 3D Amazon Lumberyard.
Amazon EC2 Elastic Compute Cloud : les serveurs virtuels
Amazon EC2 se présente comme un sevice basé web qui permet aux entreprises dexécuter leurs applications sur le Cloud public dAmazon Web Services par le biais de machine virtuelles exécutées sur les serveurs des Data Centers AWS.
Pour utiliser EC2, le développeur crée une Amazon Machine Image (AMI), contenant un système dexploitation, des applications et des paramètres de configuration. LAMI est ensuite téléchargée vers le service de stockage Amazon S3 et enregistrée avec Amazon EC2 pour créer un identifiant AMI .
Les données ne sont conservées que pendant que linstance EC2 est en cours dexécution. Cependant, un développeur peut utiliser un volume Amazon Elastic Block Store pour les conserver plus longtemps. Il est aussi possible de réaliser des backups avec Amazon S3.
Les utilisateurs peuvent contrôler leurs ressources informatiques avec précision et exécuter leur application sur lenvironnement informatique dAmazon. Amazon EC2 permet de lancer de nouvelles instances de serveurs en quelques minutes seulement, ce qui permet de redimensionner facilement la capacité en fonction des besoins.
Pour augmenter ou réduire la capacité, il suffit dutiliser linterface web ou l'API dAmazon EC2. Un développeur peut coder une application afin de redimensionner les instances automatiquement avec AWS Auto Scaling. Il est aussi possible de définir des règles dAuto Scaling et des groupes dinstancespour les gérer simultanément.
Les instances à la demande permettent au développeur de créer autant de ressources quil le souhaite et de payer à lheure. Les Instances Réservées permettent de profiter dun prix réduit à condition de sengager sur trois ans. Enfin, les Spot Instances sont des instances proposées aux enchères par Amazon pour les workloads dont les dates de début et de fin sont flexibles.
Les utilisateurs ne payent que pour la capacité quils utilisent. Amazon EC2 et Amazon S3 sont les deux principales Infrastructures en tant que Service (IaaS) utilisées par des développeurs dapplications cloud du monde entier.
Amazon Glacier : le service de stockage Cloud froid
C'est un service Cloud de stockage à moindre coût. il faut compter 3 à 5 heures pour extraire les données stockées sur Glacier. Les données sont stockées en archives et en chambres (vaults). Larchive prend laspect dun bloc de données pouvant être constitué dun seul fichier, ou de données agrégées sous la forme de TAR ou de fichiers ZIP. La taille varie entre 1 byte et 40 terabytes. Ladministrateur peut définir les autorisations et conditions daccès à chaque chambre au cas par cas. Luploading de données est gratuit, mais chaque requête dextraction vaut un peu plus de 5% du coût de stockage mensuel moyen. Le but est de dissuader les utilisateurs de s'en servir comme stockage ordinaire.
Amazon Drive
C'est une offre de stockage réservée aux particuliers.
Amazon Chime
C'est un outil de communication qui permet, de passer des appels vidéos entre collègue et avec des clients. C'est aussi une solution de data visualisation puisque lon peut peut partager des documents, notamment ceux en provenance des outils de Business Intelligence : des reportings financiers, des campagnes de publicité, etc. Il sagit également dune offre embarquée dans le nuage Amazon.
Amazon Chime est en fait un UcaaS, un service de communications unifiées dans le Cloud. On peut lutiliser sur lensemble des appareils : ordinateur, tablette ou smartphone (iOs ou Android).
Amazon FBA
Pour faire une boutique en ligne. Jungle Scout est un outil et une extension pour la recherche de produits, en particulier sur Amazon et aliexpress. Les débutants et les vendeurs établis sur Amazon utilisent cet outil pour déterminer quels produits rentables à vendre dans leur boutique en ligne. La technique du bundle, c'est quand on veut se différencier, on met 3 produits qui se vendent bien à l'unité sur amazon et qui sont packagé dans un seul produit.
Amazon PPC
Les publicités PPC Amazon sont des publicités faisant parties de lécosystème Amazon, comme les publicités Google Adwords sur google ou Facebook Ads sur Facebook. Ces annonces sont créées dans le backend Amazon Seller Central, Vendor Central et Amazon Marketing Services. Le prix de ces publicités amazon est fixé en fonction du nombre de clics (PPC). Le modèle fonctionne sur un modèle denchères où les annonces des vendeurs ayant fait loffre la plus élevée sont montrées au client. Lorsque le client clique sur les annonces sponsorisées et regarde le produit à vendre, le vendeur est facturé pour le clic même si le client nachète pas. (super seller academy)
réf: Cloud AWS - Tout savoir sur le cloud Amazon Web Services
https://www.lebigdata.fr/amazon-cloud-amazon-web-services
réf: Oseille TV
https://www.youtube.com/watch?v=Yc0n2m4n06I
2.2. Premiers pas dans la console AWS
il existe 3 méthodes d'administration de votre compte AWS :
La ligne de commande (CLI) : il s'agit de commandes que vous pouvez lancer depuis votre console pour faire tout ce que vous voulez sur AWS, comme lancer et arrêter des serveurs.
L'API : il s'agit d'une interface de programmation qui vous permet de faire tout ce que vous voulez sur AWS là aussi, comme lancer et arrêter des serveurs. Cela vous permet de créer des scripts personnalisés, si vous avez besoin de faire un usage avancé d'AWS.
l'interface web c'est la plus simple à utiliser pour des débutants. Il est important en revanche de retenir que ces autres méthodes d'accès à AWS existent.
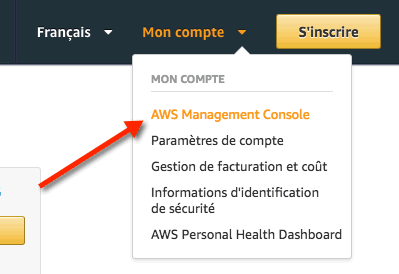
Sélectionnez "Mon compte", puis cliquez sur "AWS Management Console" :
Une fois connecté, vous arrivez sur l'accueil de la console AWS :
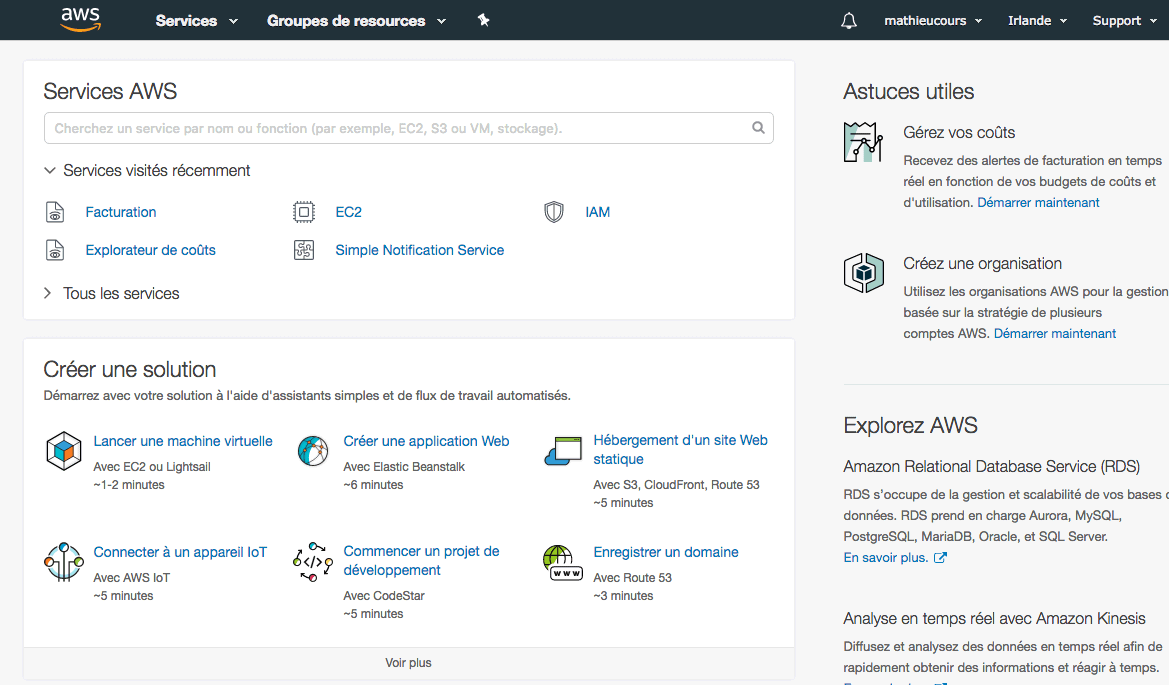
Ouvrez la section "Tous les services" (1):
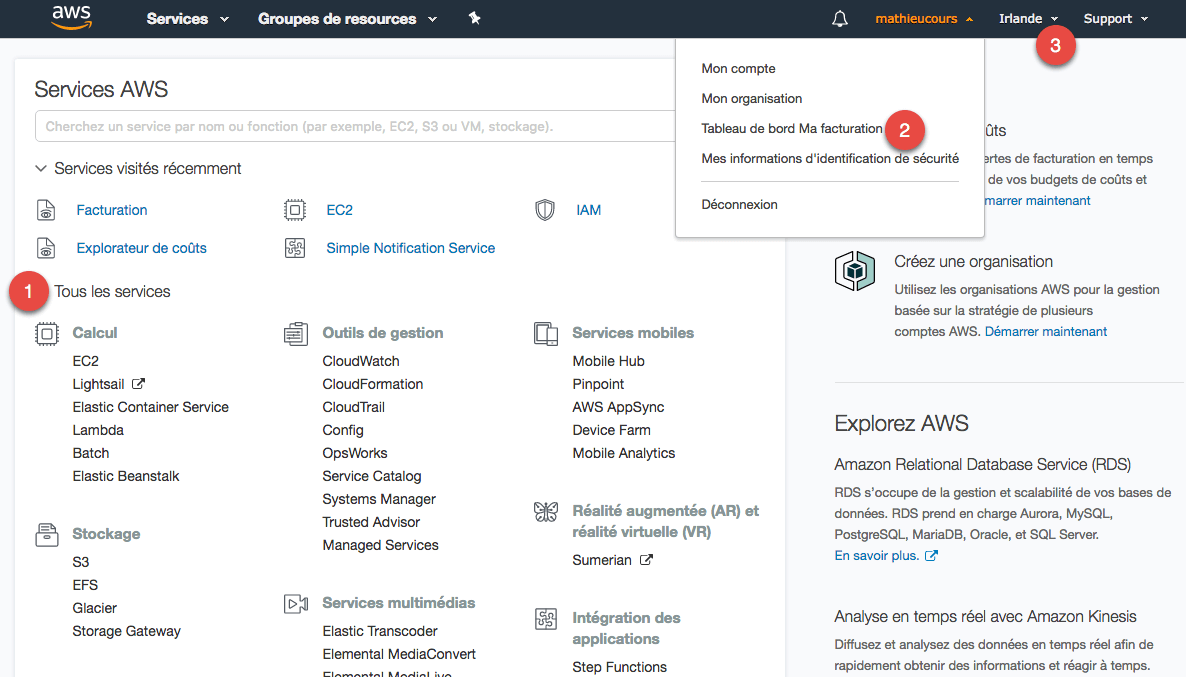
La section principale affiche tous les services d'AWS. Les plus populaires sont sans aucun doute : EC2, RDS et S3. Nous les découvrirons dans ce cours. Vous pouvez accéder à ces services depuis le menu "Services" tout en haut.
La section "Ma facturation" vous permet de connaître votre niveau de dépense actuel mais aussi de définir des alertes sur les dépenses.
La section "Région" permet de choisir depuis quel datacenter nous lançons nos services. Les prix peuvent légèrement varier d'une région à une autre. https://aws.amazon.com/fr/ec2/pricing/on-demand/
Certains nouveaux services pourraient ne pas être disponibles en même temps dans toutes les régions.
Vous pouvez définir un budget pour être averti dès que vous dépensez une certaine somme d'argent. Rendez-vous dans le "Tableau de bord Ma facturation" depuis le menu en haut à droite. L'accueil de la section facturation vous indique combien vous avez dépensé pour le mois en cours :
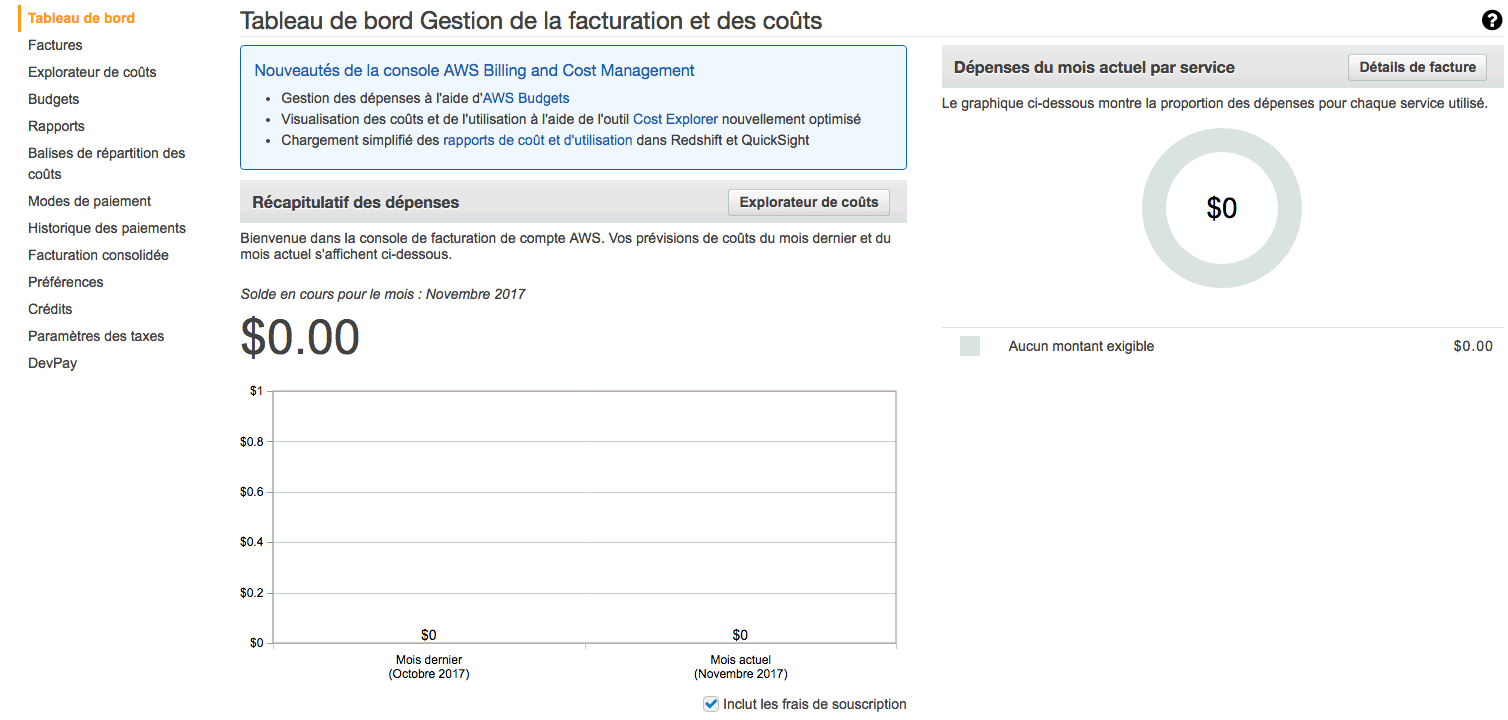
Rendez-vous sur "Budget" > "Créer un budget". Indiquez un nom à votre budget et un montant. Je propose 1$ :
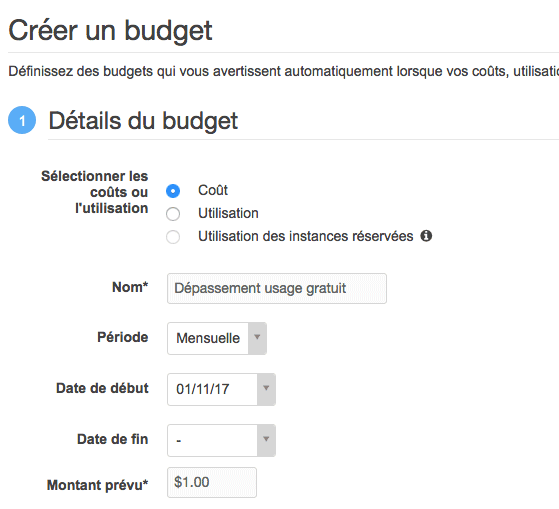
Rendez-vous plus bas dans la page pour configurer la notification. Il existe une autre solution encore plus simple pour être averti dès qu'on dépasse l'usage gratuit. Dans le "Tableau de bord Ma facturation", section "Préférences", cochez "Recevoir les alertes d'utilisation de l'offre gratuite".
2.3. Créer un serveur facilement avec Elastic Beanstalk
AWS est tellement riche et complexe qu'ils ont créé un service qui... simplifie l'usage d'autres services! Amazon Elastic Beanstalk est une interface simplifiée qui vous aide à créer vos serveurs Amazon EC2. Il existe une interface encore plus simplifiée : Amazon Lightsail. Cette interface est utile pour celles et ceux qui voudraient juste un serveur dédié sans avoir à se prendre la tête. C'est en gros comparable à louer un serveur dédié virtuel (VPS) chez OVH.

Création d'une application
L'état du serveur, avec un bouton "Causes" pour voir erreurs.
Le nom de l'application installée sur votre serveur. Ici une application de démo, mais il est possible d'envoyer le projet sous format ZIP.
Le type de serveur. Ici PHP, donc Elastic Beanstalk a lancé un serveur Linux avec PHP installé pour nous.
Les actions que vous pouvez faire. Par exemple redémarrer l'environnement, le cloner pour en faire une copie, ou bien le résilier pour le supprimer.
L'adresse web de votre serveur pour tester votre application.
Si on veut, on peut rediriger un nom de domaine vers ce serveur. Cela se fait depuis AWS Route 53, ou depuis le registrar chez qui vous avez acheté votre nom de domaine (ex : OVH, Gandi...). Enfin, sur le côté gauche de l'interface d'administration d'Elastic Beanstalk, vous avez quelques menus. Il est par exemple possible de configurer l'environnement pour changer la puissance du serveur et même d'y ajouter un serveur de base de données (ça utilise RDS
Sous le capot, Elastic Beanstalk a généré un serveur EC2 et fait un peu de configuration pour nous. Si vous retournez sur la liste des services, allez dans la section "EC2", puis dans "Instances" vous y verrez le serveur de test que vous venez de lancer.
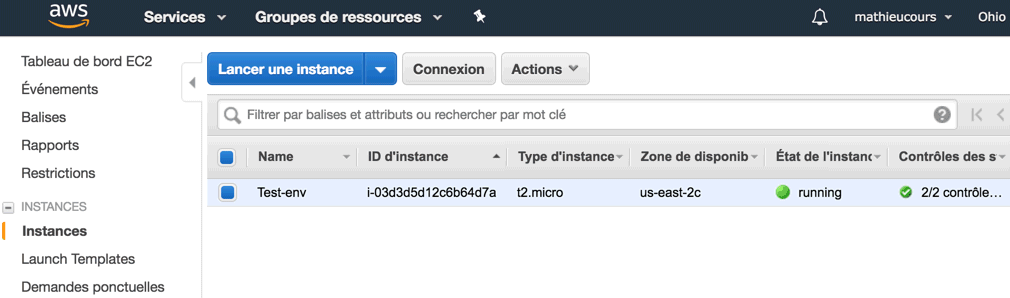
Comme je vous l'ai dit, Elastic Beanstalk ne fait que simplifier l'usage des autres services comme EC2 et RDS. Il est tout à fait possible ensuite d'ouvrir le capot de ces services et de les personnaliser...
2.4. Introduction aux services d'Amazon EC2
EC2 signifie "Elastic Compute Cloud". C'est le 1er et plus important service qui a été lancé historiquement avec AWS. De nombreux autres services créés depuis ont plus ou moins été montés "par-dessus" EC2. Par exemple, RDS n'est rien de plus qu'un serveur EC2 préconfiguré qui contient une base de données. Allez sur EC2 (menu "Services" tout en haut).
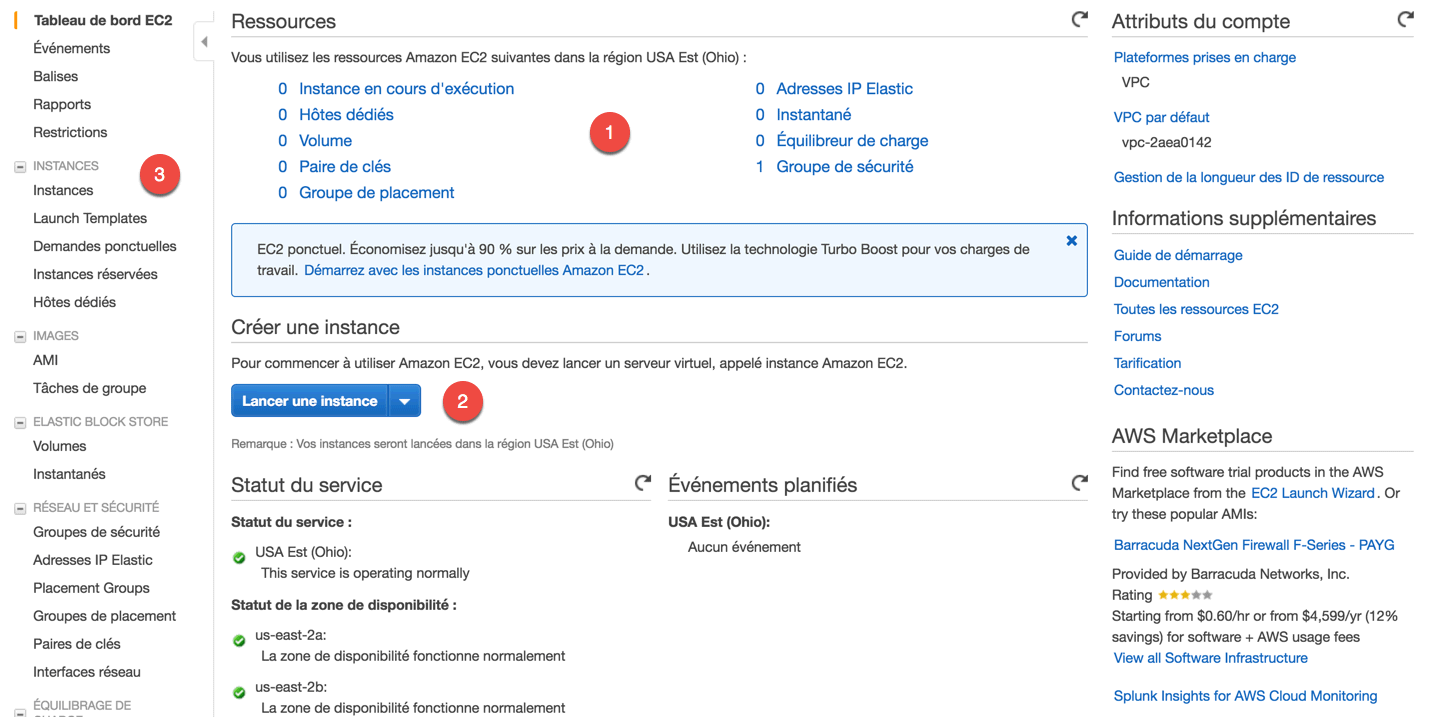
Sur cette page, il faut regarder :
La liste des ressources qui tournent dans EC2. Par exemple, "Instances en cours d'exécution" indique le nombre de serveurs qui tournent. Normalement, vous en avez 0 au début, sauf si vous en avez toujours un lancé par Elastic Beanstalk (retournez dans ce cas dans Elastic Beanstalk pour le supprimer et retomber à 0 instances en cours d'exécution).
Le bouton "Lancer une instance", si vous souhaitez lancer un nouveau serveur.
Le menu de gauche, présente tous les sous-services intégrés à EC2. On ne verra qu'un bout de ces sous-services, il n'est pas vital de tout connaître.
Les services EC2
AWS c'est un peu comme les poupées russes : quand tu rentres dans un service, il y a des sous-services, qui peuvent eux-même contenir des... Vous voyez l'idée...
Instances
La page Instances affiche la liste des serveurs EC2 qui tournent. S'il y a un écran à connaître, c'est celui-là.
Images
Le lien AMI (Amazon Machine Image) affiche les images de vos instances EC2. On se sert souvent d'un AMI au départ pour lancer un serveur EC2 préconfiguré. On récupèrera pour notre part un AMI proposé par Amazon ou par sa communauté sur le "Marketplace" (on y trouve des AMI gratuits et payants). Il est aussi possible de créer vos propres AMI à partir de vos serveurs. Ca vous permet de prendre un instantané (backup) de votre serveur. Vous en faites ainsi une sauvegarde, ce qui vous permet de lancer un nouveau serveur exactement dans le même état.

Elastic Block Store EBS
La section Volumes affiche tous les disques utilisés par vos serveurs. Avec AWS, on distingue en effet l'instance (juste la puissance de calcul du processeur en gros) et les disques. Les volumes EBS sont en quelque sorte des disques durs. Quant aux Instantanés, ce sont les sauvegardes des disques EBS de vos serveurs.
Réseau et sécurité
Les Groupes de sécurité constituent vos règles de sécurité pour gérer le trafic entrant et sortant de vos serveurs. C'est comme ça que vous pouvez mettre en place un firewall (pare-feu) pour protéger vos serveurs.
Les Adresses IP Elastic vous permettent d'affecter une IP statique à vos serveurs. C'est utile car, par défaut, un serveur que vous redémarrez va en général changer d'adresse IP. Grâce aux IP Elastic, vous pouvez faire en sorte que votre serveur garde la même IP (ce qui est indispensable si vous voulez héberger correctement un site web !).
Les Paires de clés affichent vos paires de clés créées pour accéder aux serveurs en ligne de commande avec SSH.
Equilibrage de charge
L'Equilibrage de charge (Elastic Load Balancing) vous permet d'envoyer le trafic vers plusieurs serveurs en choisissant automatiquement le serveur qui est actuellement le moins occupé.
Auto Scaling
Si vous avez un trafic qui augmente ou qui diminue, l'Auto Scaling vous permet d'ajouter ou de retirer des serveurs en fonction du trafic. Imaginez, si tout le monde veut voir votre site d'un coup, l'auto scaling va s'activer et lancer plus de serveurs (jusqu'à une limite que vous avez définie). Ainsi, votre site peut passer de 3 à 10 serveurs au besoin en quelques minutes pour gérer le trafic ! L'auto scaling peut être un bon complément à l'équilibrage de charge lorsque vous avez un gros trafic.
2.5. Choisir le bon type dinstance
il existe de nombreux types de serveurs plus ou moins puissants... et plus ou
moins chers. Commencez par regarder la liste des types d'instances proposés par
Amazon EC2 sur la page: https://aws.amazon.com/fr/ec2/instance-types/
Il y a tellement de types d'instances différents qu'on les a regroupés dans plusieurs catégories :
Usage général : ce sont des serveurs "équilibrés" qui ne privilégient ni le processeur, ni la mémoire vive, ni le disque dur. Ce sont ceux qu'on utilisera en général pour héberger des sites web. Oui mais voilà, EC2 ne sert pas qu'à héberger des sites web, c'est pour ça qu'on a aussi d'autres types.
Calcul optimisé : ces serveurs sont des monstres de calcul. Les processeurs sont capables d'avaler de nombreuses instructions par seconde. On peut les utiliser pour faire de la modélisation scientifique, de l'analyse distribuée. .. ou pour des serveurs web qui ont besoin de très hautes performances.
Mémoire optimisée : ces serveurs ont beaucoup de mémoire vive. Beaucoup beaucoup. Vous pouvez en réalité monter jusqu'à 3 900 Go de mémoire vive (soit près de 4 To !). Il faut avoir une application très gourmande en mémoire, comme une base de données stockée en mémoire vive, pour avoir besoin de ça.
Calcul accéléré : ces serveurs sont aussi des monstres de calcul, qui utilisent cette fois des cartes graphiques (GPU). On peut les utiliser pour faire de l'apprentissage machine, gérer des véhicules autonomes, faire de la reconnaissance vocale...
Stockage optimisé : ces serveurs proposent des disques durs très performants. Ce n'est pas tant le stockage qui est grand que la vitesse d'accès aux disques qui est rapide. On peut s'en servir pour faire du calcul distribué MapReduce ou Hadoop, ou encore gérer des systèmes de fichiers distribués.
Pour chacune de ces catégories, on vous propose des dizaines de types de serveurs différents plus ou moins puissants. L'instance t2.micro est celle qui est gratuite pendant 1 an. Vous pouvez laisser 1 serveur t2. micro allumé en permanence pendant un an sans payer. Pa rcontres la bande passante n'est pas illimitée. Si vous consommez beaucoup de bande passante, vous pourriez être amenés à payer un supplément. Ca ne devrait heureusement jamais arriver pour un usage normal.
Les différents types de tarification
Rendez-vous sur la page tarification EC2 pour voir ces types de tarification.
https://aws.amazon.com/fr/ec2/pricing/
On distingue :
Tarification à la demande : c'est ce que nous utiliserons, le plus simple. Il n'y a aucun engagement. Vous avez besoin d'un serveur ? Vous en demandez un. Vous n'en avez plus besoin ? Vous le rendez.
Instances spot : vous êtes radins ? Si vous êtes prêts à attendre les heures les moins chères, les instances spot sont pour vous ! C'est une enchère inversée qui vous permet de payer des serveurs uniquement lorsqu'ils sont peu utilisés, et donc pas chers. Vous ne pouvez pas vraiment vous en servir pour héberger un site web en revanche, car les instances spot démarrent uniquement aux moments les moins chers (par exemple entre 3h et 5h du matin). Avantage : vous pouvez faire jusqu'à 90% d'économie.
Instances réservées : vous savez que vous aurez besoin d'un serveur à coup sûr pendant 1 an ? Si vous êtes prêts à vous engager, les instances réservées vous permettent de payer moins cher (jusqu'à 75% moins cher). Elles sont ensuite à vous pendant la durée de votre engagement.
Hôtes dédiés : plutôt que de gérer des machines virtuelles, vous pouvez demander à avoir une machine physique entière. Vous pouvez en avoir besoin si vous avez des licences logicielles liées à des serveurs physiques (comme Windows Server) ou si vous êtes paranoïaque et ne voulez pas partager votre machine avec d'autres personnes.
Que faut-il utiliser ? C'est la tarification à la demande, la plus souple, qui est la plus adaptée dans la plupart des cas. Les instances sont facturées à la seconde près. on peut avoir quelques instances réservées de base, et le système
d'auto-scaling qui rajoute des serveurs en tarification à la demande en fonction du trafic.
2.6. Lancer une instance
Si vous avez déjà un serveur lancé, veillez à l'arrêter ou à le supprimer (résilier) avant d'en lancer un nouveau si vous ne voulez pas payer. En effet, l'offre gratuite ne permet d'avoir qu'un serveur allumé à la fois de type t2.micro. Si votre serveur avait été lancé par Elastic Beanstalk, retournez dans l'interface d'Elastic Beanstalk pour le supprimer.
Rendez-vous dans EC2, section "Instances". Cliquez sur "Lancer une instance" :
Lorsque vous cliquez sur "Lancer une instance", un assistant en plusieurs étapes s'ouvre. La première consiste à choisir l'AMI.
Sélection d'une image de départ (AMI)
Les AMI sont des images du disque. Elles représentent un serveur dans un état donné et servent de point de départ.

La première étape choix du système d'exploitation. Vérifiez que l'image est marquée "Admissible à l'offre" (ça signifie "Admissible à l'offre gratuite"). - Linux AMI : une distribution Linux optimisée pour Amazon EC2. - Ubuntu Server : la distribution Linux Ubuntu en version serveur - SUSE Linux : si votre truc c'est plutôt SUSE. - Red Hat : si votre truc c'est plutôt Red Hat. - Windows Server : si votre truc c'est plutôt Windows Server
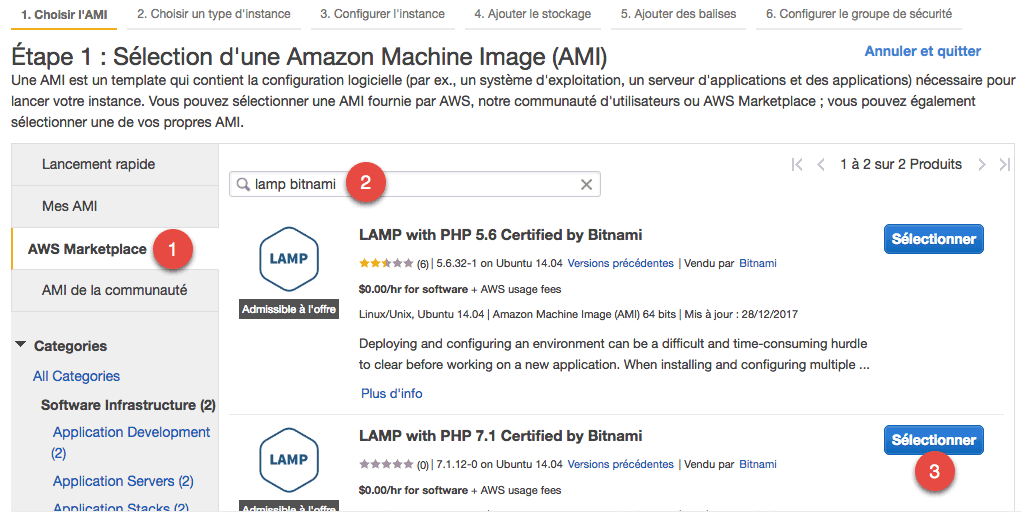
En plus de ces images, il existe de nombreux autres AMI préconfigurés. Il est possible d'installer tout ce qu'on veut sur un serveur EC2, y compris un moteur de bases de données comme MySQL. En revanche, il existe un autre service d'Amazon appelé RDS qui gère pour vous un serveur de base de données séparé. Je vous recommande d'utiliser plutôt RDS pour vos bases de données : ça vous épargnera toute la configuration et les mises à jour à faire.
Allez dans AWS Marketplace. Cherchez-y "LAMP bitnami" et sélectionnez "LAMP with PHP 7. 1 Certified by Bitnami". Il est lui aussi "Admissible à l'offre", donc utilisable gratuitement.
Choisir un type d'instance
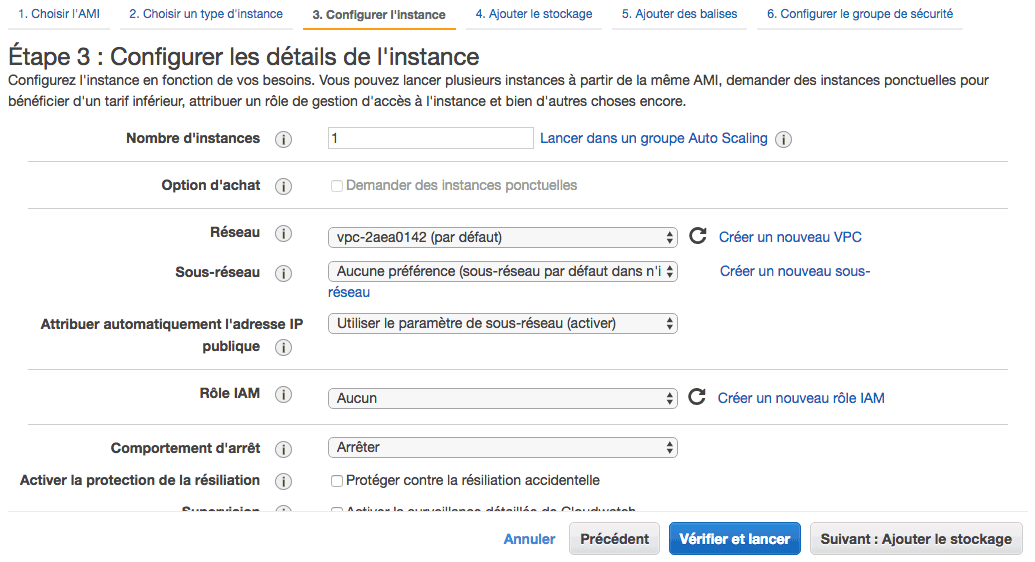
On vous demande en premier combien d'instances vous voulez lancer (1 dans notre cas). Vous avez une option pour créer un groupe "Auto Scaling" qui va automatiquement ajouter et retirer des serveurs en fonction du trafic.
Vous avez ensuite des options pour configurer le réseau qui permet à vos serveurs de communiquer entre eux.
Le rôle IAM est un système qui permet d'attribuer la gestion de ce serveur à un utilisateur précis. IAM est le service AWS qui permet de gérer plusieurs utilisateurs avec des droits différents.
Au final, ici... on ne va rien toucher.
Ajouter le stockage
EC2 sépare les choses :
- Il y a d'un côté le serveur (la puissance de calcul)...
- et de l'autre les disques. Il peut s'agir de disques durs ou de SSD (mémoire flash) selon le type d'instance que vous avez sélectionné.
Les disques sont gérés par un sous-service d'EC2 qu'on appelle EBS (Elastic Block Store). Par défaut, on nous a configuré ici un volume EBS de 10 Go :
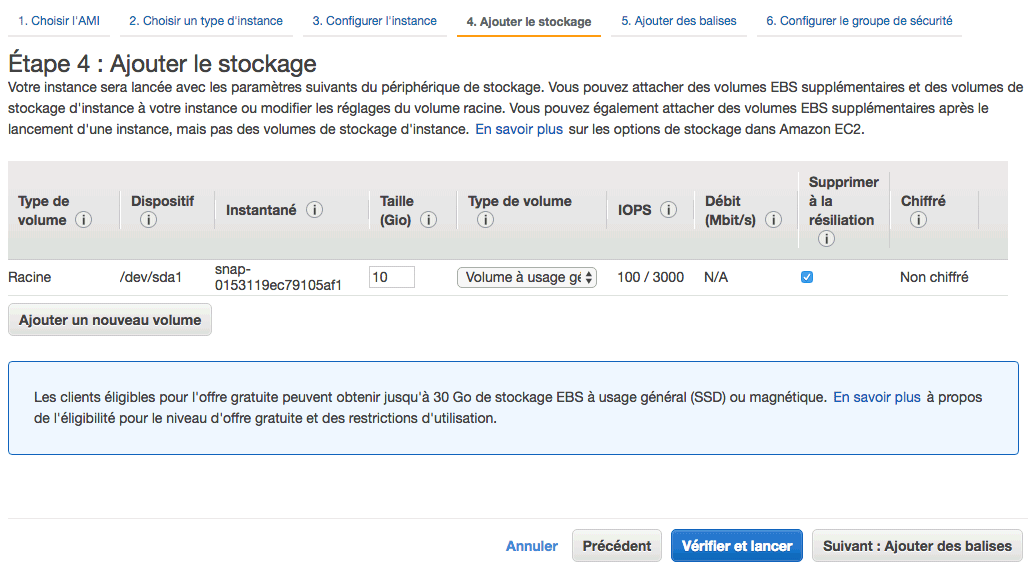
Vous changez le "Type de volume", avoir un SSD encore plus rapide, ou bien un disque magnétique (disque dur).
Ajouter des balises
Cette section permet de "tagger" le serveur pour pouvoir le retrouver plus rapidement ensuite :
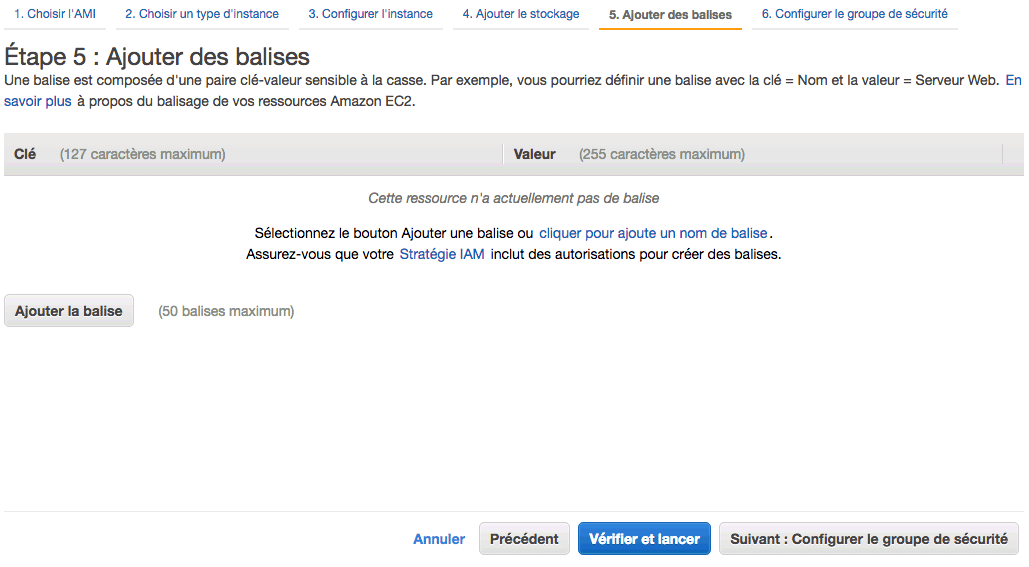
Cela fonctionne par un système de clé / valeur. Par exemple, si vous voulez, vous pouvez ajouter une balise site = openclassrooms . La clé est "site", la valeur est "openclassrooms". Ainsi, si vous faites une recherche par la suite, vous pourrez facilement retrouver tous les serveurs qui sont reliés au site OpenClassrooms.
Configurer le groupe de sécurité
C'est ici que vous configurez votre firewall (pare-feu). Nous allons créer un nouveau groupe de sécurité, et ouvrir les ports SSH (port 22) et HTTP (port 80) Les groupes de sécurité peuvent être partagés entre plusieurs serveurs. Donnez-leur un nom facile à retrouver (exemple : "Web server firewall config").
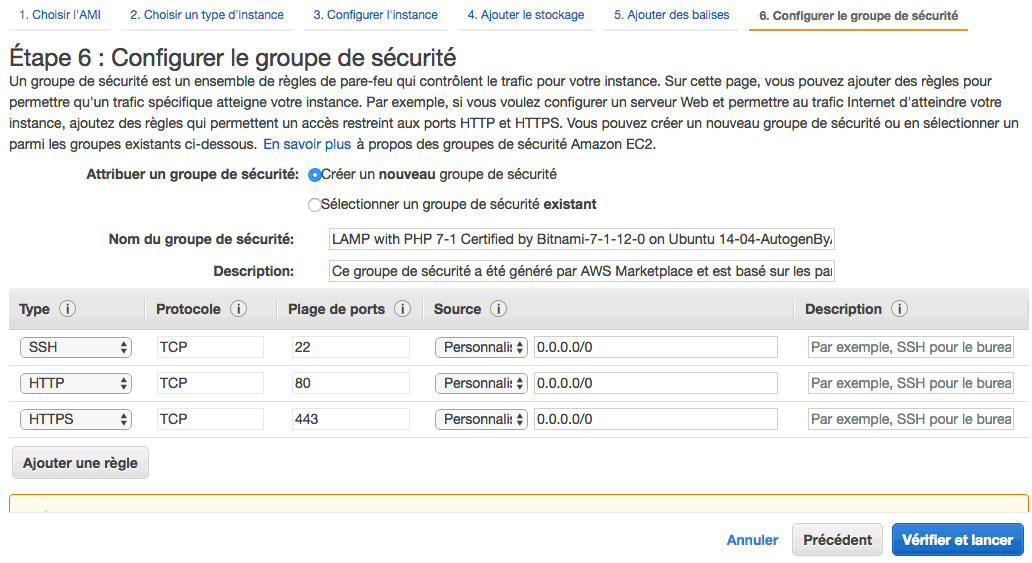
Lancement du serveur
Cliquez ensuite sur "Vérifier et lancer". Une popup apparaît vous demandant avec quelle clé SSH vous souhaitez vous connecter au serveur. Ici, nous allons créer une nouvelle paire de clés avec le nom que vous voulez:
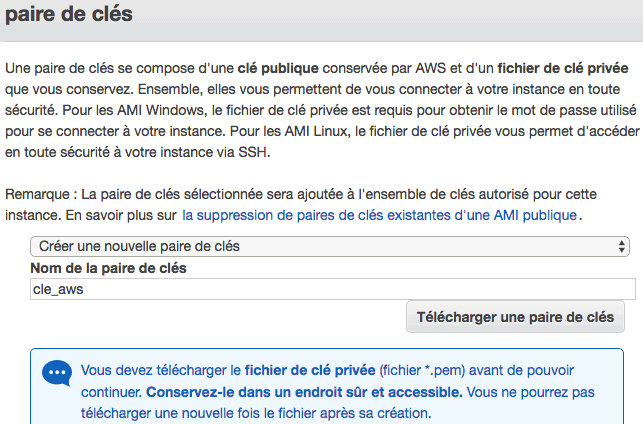
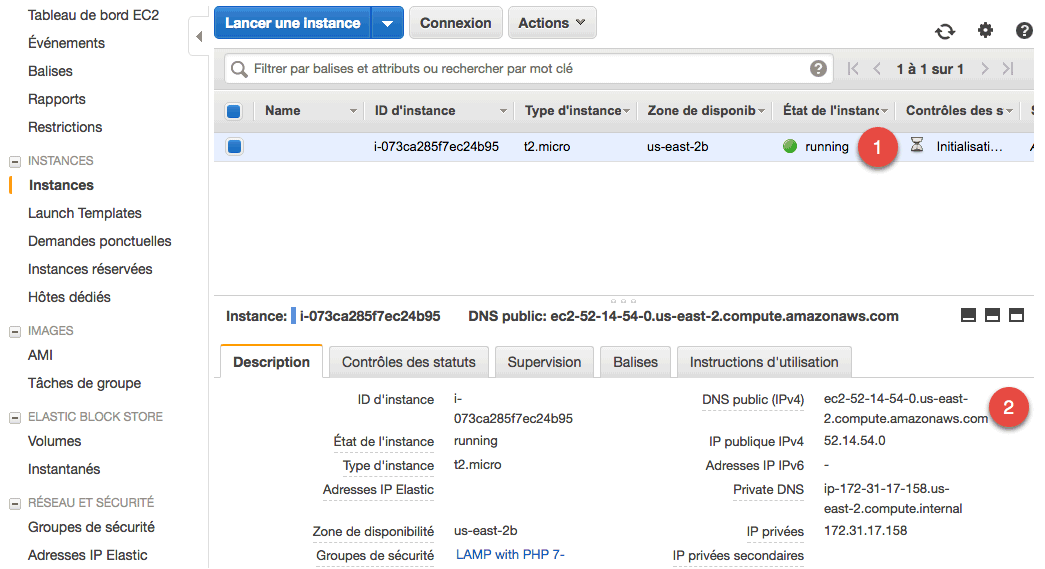
Le téléchargement de cette clé n'est possible qu'une seule fois, par mesure de sécurité. Une fois l'opération validée, vous pouvez cliquer sur "Lancer des instances". Après quelques instants, le serveur est démarré et apparaît désormais dans "Instances". Vous pouvez voir que l'instance de type t2.micro est en statut vert "running" (1).
Connexion SSH à la machine virtuelle sous Linux
Il faut placer la clé dans le dossier .ssh de votre dossier home. Il faut aussi donner des droits en lecture uniquement à notre utilisateur, sinon ça ne marchera pas. Configurez un chmod de 400 pour faire ça :
mv cle_aws_democours.pem ~/.ssh chmod 400 ~/.ssh/cle_aws_democours.pem
Ensuite, il faut se connecter en SSH à notre serveur en indiquant bien notre clé dans la commande. Pour ça, il faut connaître l'IP ou le DNS public du serveur.
ssh -i "~/.ssh/cle_aws_democours.pem" ubuntu@ec2-18-221-76-221.us-east-2.compute.amazonaws.com
ubuntu : c'est le nom de l'utilisateur avec lequel vous voulez vous connecter. Tout dépend de l'AMI que vous avez choisi. Il est rare qu'on se connecte en root directement en revanche : on passe par un utilisateur lambda comme "ubuntu" puis on passe ensuite en root si besoin avec la commande sudo. Attention : l'IP et le DNS public du serveur peuvent changer quand vous le redémarrez ! On verra comment configurer une "IP elastic" pour régler ce problème.
réf: Découvrer le cloud avec AWS
https://openclassrooms.com/fr/courses/4810836-decouvrez-le-cloud-avec-amazon-web-services
2.7. Héberger une application ASP.Net Core sur le cloud AWS via Docker
Docker est un logiciel libre permettant de déployer des applications de manière automatisée. Le principe de Docker est d'embarquer une application et toutes ses dépendances dans un conteneur. Ce dernier pourra être déployé et exécuté depuis n'importe quel serveur. Un conteneur se base sur une image, qui est la définition de ce dont l'application a besoin pour s'exécuter correctement. Il existe un grand nombre d'images, dont une pour ASP.NET Core. Techniquement, Docker étend le format de conteneur Linux standard (LXC) grâce à une API fournissant une solution de virtualisation qui exécute les processus de façon isolée. Pour cela, Docker utilise entre autres LXC, cgroups et le noyau Linux. LXC se concentre sur les conteneurs systèmes. Ceux-ci offrent un environnement aussi proche que possible de celui d'une machine virtuelle, mais sans le surcoût associé à l'utilisation d'un noyau séparé ou à la simulation de matériel. Tout ceci est possible grâce aux fonctionalités de sécurité du noyau telles que les "namespaces", le contrôle d'accès obligatoire (MAC), et les groupes de contrôle (CGroups).
Elastic Beanstalk est une solution permettant de déployer facilement des applications sur les serveurs Amazon Web Service. Il est possible de déployer des applications développées avec PHP, Java, .Net, Python, Docker, etc. Étant donné qu'ASP. NET Core est encore récent, il n'est pas aisé de déployer l'application directement sur Elastic Beanstalk, c'est pourquoi la meilleure pratique actuelle est de déployer un conteneur Docker contenant notre application web ASP.NET Core (à l'inverse d'ASP.NET MVC 4 par exemple).
Création d'une machine virtuelle
Nous allons créer une machine virtuelle AWS, nous permettant de créer le projet et le conteneur Docker. Il sera ensuite déployé avec Elastic Beanstalk.
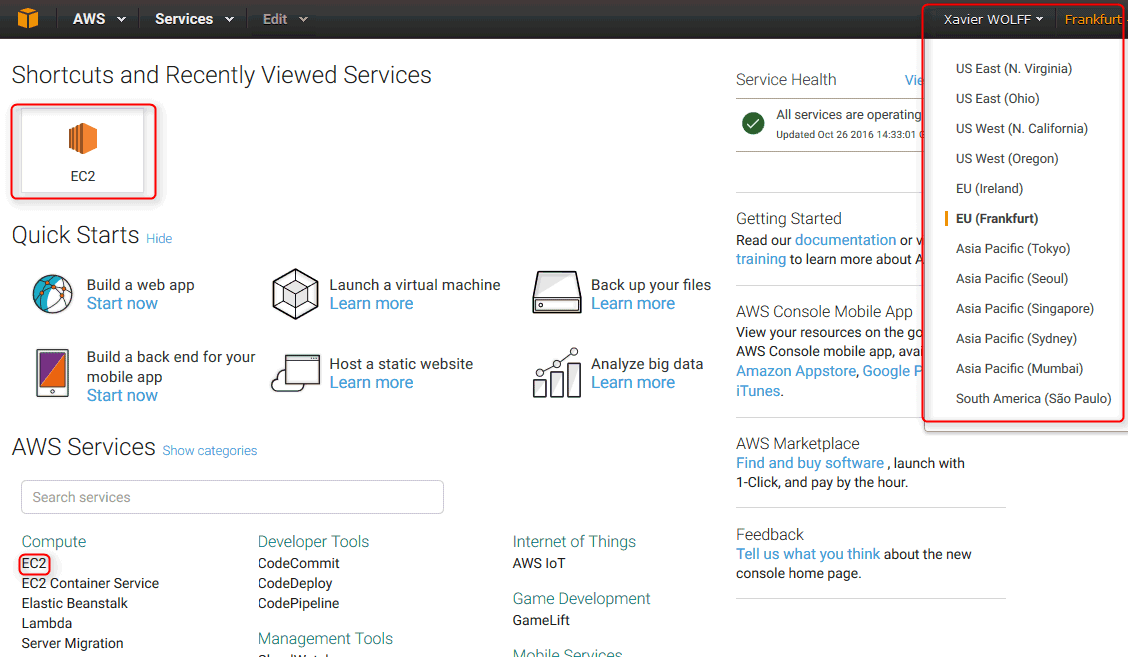
Depuis l'écran d'accueil, nous allons cliquer sur « EC2 », qui correspond à « Elastic Compute Cloud ». C'est avec cet outil que nous allons créer et manager nos machines virtuelles. En cliquant ensuite sur le bouton « Launch Instance », nous arrivons dans les écrans de création d'une machine virtuelle. Nous allons créer une machine virtuelle « Amazon Linux » :

L'ensemble des propriétés par défaut peut être sélectionné. Il est facilement possible de configurer votre machine selon vos envies. À l'étape 6, il est par contre nécessaire d'effectuer certaines opérations. Nous allons créer un nouveau groupe de sécurité, et ouvrir les ports SSH (port 22) et HTTP (port 80) :
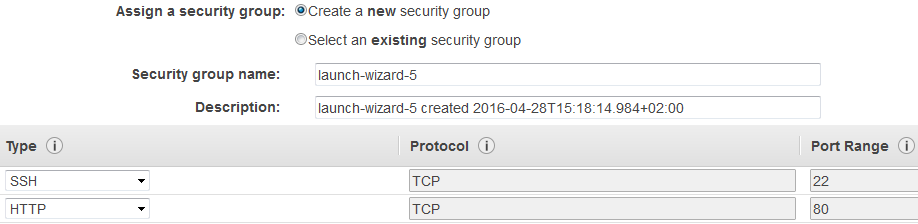
Le port 22 nous permettra de nous connecter en SSH à la machine dans le cloud, alors que le port 80 est nécessaire pour afficher le site web sur le navigateur. En cliquant sur le bouton « Launch », une popup apparaît vous demandant à quelle clé associer cette machine. Un couple de clés permet de générer le mot de passe nécessaire pour se connecter. Ici, nous allons créer une nouvelle paire de clés avec le nom que vous voulez. Le téléchargement de cette clé n'est possible qu'une seule fois, par mesure de sécurité. Une fois l'opération validée, votre machine virtuelle apparaît dans la liste des instances et est en cours de démarrage.
Connexion SSH à la machine virtuelle avec Putty
La première étape consiste à générer une clé privée, à partir de la clé obtenue lors de la création de la machine. Pour se faire, ouvrir « Putty Key Generator » (ou PUTTYgen). Une fois le logiciel ouvert, cliquez sur le bouton « Load » pour chercher le fichier précédemment téléchargé : La clé à générer doit être une clé SSH-2RSA privée de 2 048 bits. C'est cette nouvelle clé que nous allons utiliser dans Putty pour nous connecter. Lancez maintenant Putty, dans la partie « Host Name », renseignez la valeur suivante : ec2-user@dns Lorsqu'une machine virtuelle est créée sur AWS, un utilisateur « ec2-user » est automatiquement créé. La seconde partie à renseigner est le nom de votre machine
virtuelle. Il se trouve dans la liste des instances EC2 sur le site avec lequel vous avez créé la machine. Par ex : ec2-user@ec2-52-16-98-123.eu-west-1.com . La dernière opération à effectuer est d'ajouter la clé que nous avons générée précédemment dans "Connection, SSH, Auth, Private key file for authentication:". vous devriez avoir la connexion sur votre serveur :
Using username "ec2-user".
Authenticating with public key "imported-openssh-key"
ECZ Amazon Linux AMI
https://aws.amazon.com/amazon-linux-ami/2016.03-release-notes/
No packages needed for security; 1 packages available
Run "sudo yum update" to apply all updates.
[ec2-user@ip-172-31-24-152 ~]$
Libre à vous de mettre à jour votre machine avec la commande : sudo yum update .
Configuration de la machine virtuelle
Nous allons installer et démarrer Docker, et nous assurer qu'il redémarre si le serveur doit être redémarré :
sudo yum install -y docker sudo service docker start sudo chkconfig docker on
Installons Dotnet et Elastic Beanstalk :
sudo yum install libunwind libicu curl -sSL -o dotnet.tar.gz https://go.microsoft.com/fwlink/?LinkID=827529 sudo mkdir -p /opt/dotnet && sudo tar zxf dotnet.tar.gz -C /opt/dotnet sudo ln -s /opt/dotnet/dotnet /usr/local/bin sudo pip install awsebcli
Dotnet donne une méthode permettant de créer un projet de type web vide. Tout le squelette est construit et une page d'accueil est créée. exécuter les commandes:
mkdir helloweb && cd helloweb dotnet new -t web
Mise en place du conteneur Docker
Pour déployer un conteneur Docker, nous avons uniquement besoin de créer un fichier « Dockerfile » à la racine du projet (sans extension). La commande cat > Dockerfile permet de créer un fichier et d'y ajouter le contenu suivant :
FROM microsoft/dotnet:latest COPY . /app WORKDIR /app RUN dotnet restore ENV ASPNETCORE_URLS http://*:5000 EXPOSE 5000 ENTRYPOINT ["dotnet", "run"]
La première ligne signifie que Docker va utiliser la dernière version de l'image « Microsoft/dotnet », mise en place par leur équipe, permettant de déployer un projet ASP.NET Core.
Pour construire l'image Docker avec ce fichier de configuration, exécutez :
sudo docker build -t helloweb .
Cette opération va exécuter chaque ligne du fichier Dockerfile. Le paramètre -t permet de spécifier le nom de l'image. Attention la récupération des dépendances du projet peut prendre un certain temps. La commande "sudo docker images" liste les images créées par Docker.
REPOSITORY TAG IMAGE ID CREATED SIZE helloweb latest 2f9ccaaf3e32 8 seconds ago 645.5 MB microsoft/dotnet latest dd62a1a4dba7 20 hours ago 537.4 MB
La commande "sudo docker images" liste les images créées par Docker. Pour lancer le conteneur associé à une image, il faut exécuter la commande suivante :
sudo docker run -d -p 80:5000 -t helloweb
Le port défini dans le fichier de configuration est à entrer à cet endroit-là dans le cas où vous avez précisé un autre. Le paramètre -d indique à Docker de faire tourner le conteneur en tâche de fond. -p permet de faire le lien entre le port 80 du serveur et le conteneur. Quand nous allons appeler l'URL du serveur sur le port 80, nous serons donc redirigés vers notre conteneur. -t permet à nouveau de spécifier de nom de l'image à utiliser.
sudo docker ps permet de lister tous les conteneurs actifs :
REPOSITORY IMAGE COMMAND CREATED STATUS PORT 2f9ccaaf3e32 helloweb "dotnet run" 16 secondsago Up 15 seconds 0.0.0.0:80->5000/tcp sick_jang
Les requêtes entrées par le port 80 sont redirigées vers le 5000, pour atteindre le conteneur que nous venons de déployer. Et comme nous avons ouvert le port 80, l'application Web s'affiche avec l'adresse DNS du serveur. Votre site ASP.NET Core est hébergé sur une machine virtuelle Linux depuis Docker dans le cloud !
Déploiement sous Elastic Beanstalk
On vat déployer ce conteneur Docker dans le service « Elastic Beanstalk » d'AWS.
Comme pour Docker, le service a besoin d'un fichier de configuration à la racine du projet portant le nom Dockerrun.aws.json. Les commandes suivantes permettent de créer et remplir le fichier Dockerrun.aws.json avec la configuration minimale
cat > Dockerrun.aws.json { "AWSEBDockerrunVersion": "1" }
La commande suivante va initialiser une instance d'Elastic Beanstalk. Attention, il est possible qu'on vous demande la clé d'accès et la clé d'accès secrète du compte AWS (parce qu'on va automatiquement créer une machine virtuelle en dehors du panel d'administration). Ces clés sont récupérables depuis la console AWS
eb init
Un ensemble de choix va vous être proposé pour initialiser l'environnement :
- Choix de la région : la même que celle du serveur utilisé précédemment ;
- Nom de l'application ;
- Utilisez-vous un multiconteneur Docker ? Non ;
- Plateforme Docker ;
- La version la plus récente ;
- Ne pas mettre en place le SSH sur la nouvelle machine.
Ensuite, lancez le déploiement avec la commande :
eb create helloweb-prod
Cette opération dure entre 7 et 10 minutes. Pendant ce temps, AWS va créer une nouvelle machine virtuelle, mettre en place le service Elastic Beanstalk sur cette dernière, et déployer le conteneur Docker. Vous verrez apparaître la nouvelle machine utilisée par le service pour héberger votre application dans la liste des instances EC2.
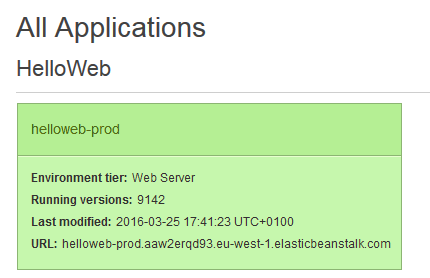
Vous pouvez ensuite, depuis la console AWS, suivre les étapes de déploiement en cliquant sur le service Elastic Beanstalk . Une fois le déploiement effectué, vous aurez un bloc correspondant à votre application. En cliquant sur le détail, vous aurez des informations complémentaires dont lURL publique mise en place par Elastic Beanstalk lors du déploiement de votre conteneur.
réf: Héberger une application ASP.Net Core sur le cloud AWS via Docker
https://soat.developpez.com/tutoriels/aspnet/heberger-application-aspnet-sur-le-cloud-aws-via-docker/
https://blog.soat.fr/2016/06/aws-heberger-une-application-asp-net-core-sur-elastic-beanstalk-via-docker/
2.8. héberger une page web
Nous avons maintenant un serveur web LAMP qui est prêt à faire tourner des pages PHP. Nous avons utilisé pour cela l'AMI fourni par Bitnami, même si nous aurions très bien pu tout installer à la main.
Souvent, les fichiers du site web sont stockés dans un dossier /var/www/, avec l'AMI de Bitnami, les fichiers sont dans le dossier : /home/bitnami/htdocs. Pour manipuler des fichiers, il faut utiliser SFTP: c'est le FTP de SSH. Ex FileZilla 1. Cliquez sur Nouveau site 2. Copiez l'IP ou le nom d'hôte de votre serveur 3. Sélectionnez bien le protocole SFTP 4. Type d'authentification : Fichier de clé 5. Identifiant : ubuntu (ou un autre identifiant, selon l'AMI utilisé) 5. Fichier de clé : indiquez le chemin vers le fichier de votre clé privée
Le problème est que l'IP des instances EC2 peut changer ! Mais il est possible d'obtenir une IP fixe avec Elastic IP. Pour ce qui est d'utiliser un domaine à la place de l'IP, comme monsite.com, c'est un peu plus de travail. 1. Configurez ce nom de domaine pour qu'il pointe vers l'IP Elastic de votre instance. Il faut créer un champ A dans la configuration du DNS dans Route 53. 2. Configurez Apache sur votre instance EC2 avec un Virtual Host pour qu'il réponde à ce nom de domaine. Dans le cas de l'AMI Bitnami, la doc explique tout.
Configurer une IP élastique
Si vous redémarrez votre serveur EC2, rien ne garantit qu'il aura la même IP! En effet, AWS prend une machine libre pour lancer votre serveur virtuel. Il se pourrait très bien que votre serveur ait changé de place au prochain démarrage ! Une adresse IP élastique (ou statique) associée à un serveur EC2 qui tourne est gratuite (tant que vous associez une seule IP au serveur). Rendez-vous dans la section "Réseau et sécurité", section "Adresse IP Elastic". Cliquez sur "Allouer une nouvelle adresse". Et une nouvelle IP vous est fournie. Il faut maintenant associer cette IP à notre instance.
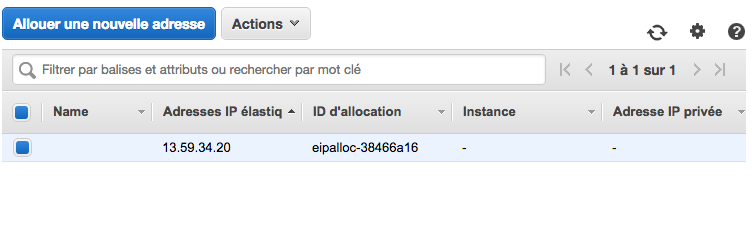
Allez dans "Actions" > "Associer l'adresse" :
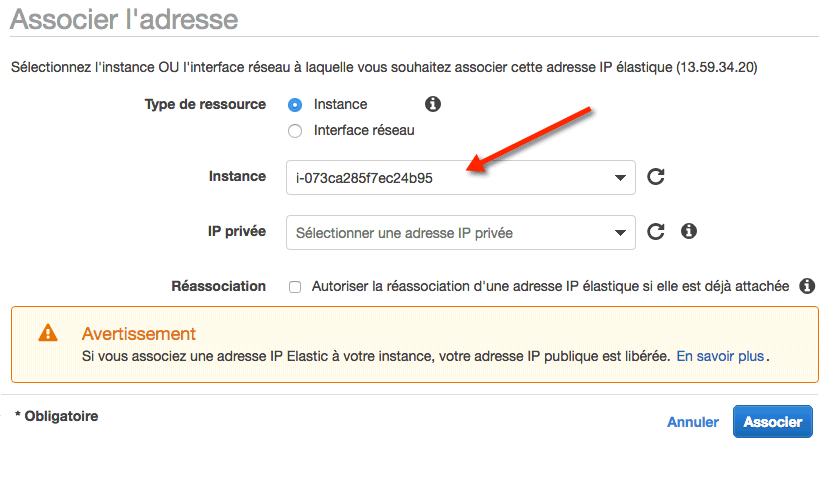
Là, vous indiquerez que vous voulez associer votre IP Elastic à une instance. Dans le menu déroulant "Instance", sélectionnez l'instance EC2 à laquelle vous voulez la rattacher. Une fois que c'est fait, vous devriez voir que votre instance est attachée à un serveur. Et si vous allez sur la liste des instances, vous verrez que l'IP et le DNS du serveur ont changé. Votre serveur a maintenant une IP fixe !
2.9. Sauvegarder et restaurer une instance
Il est très facile de faire des sauvegardes et des restaurations de nos serveurs AWS. C'est l'avantage d'utiliser des machines virtuelles dans le cloud ! Par défaut, AWS ne fait pas de sauvegarde de vos instances EC2 pour vous. Il va donc falloir que vous anticipiez. Vous avez 2 solutions pour sauvegarder une instance EC2. Chacune a ses avantages et ses défauts.
Créer un AMI depuis votre serveur est le plus simple. Tout le disque et toute la configuration du serveur seront copiés. En revanche, chaque AMI prend de la place (et peut finir par coûter de l'argent), car tout le contenu du serveur est copié à chaque fois.
Créer un instantané EBS (du disque) est le plus économique. Les sauvegardes sont incrémentielles : la première sauvegarde d'un disque de 10 Go prendra 10 Go, mais la seconde ne prendra que 1 Go si seulement 1 Go a changé depuis la dernière fois. L'instantané est un peu plus compliqué à manipuler, car il faut rattacher le disque au serveur (rien de très complexe pour autant).
Sauvegarde avec un AMI
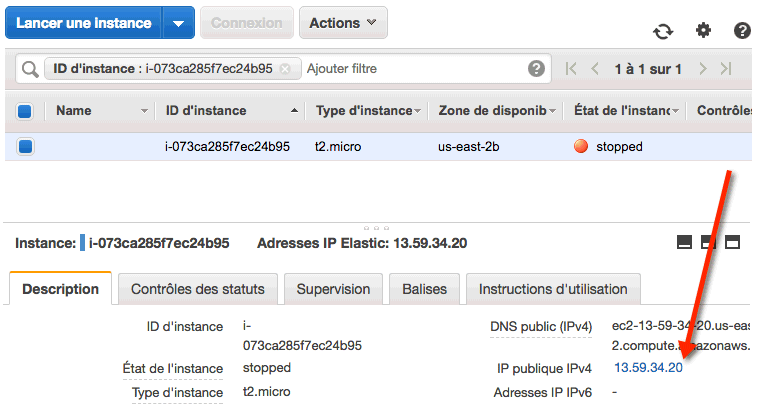
l vous suffit de sélectionner votre instance EC2, puis d'aller dans "Actions" > "Image" > "Créer l'image".
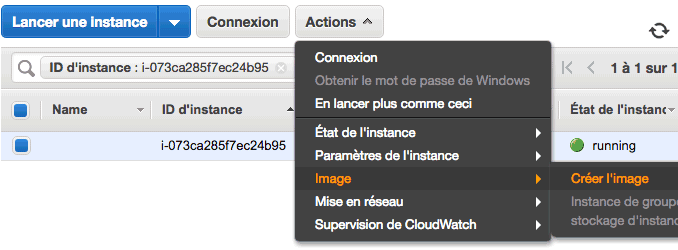
On vous demande alors de donner un nom à votre image (par exemple MyBackup), puis cliquez sur "Créer l'image".
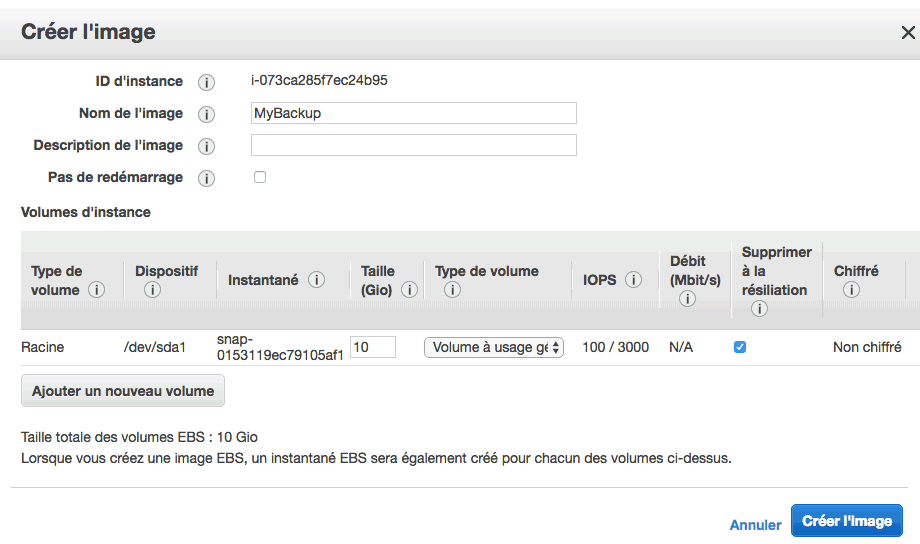
Vous retrouverez votre image dans le menu "Images" > "AMI".
La création de l'image va provoquer la création d'un instantané EBS. En effet, notre image contient l'instantané EBS. Vous pouvez aller dans le menu "Elastic Block Store" > "Instantanés" pour voir que vous avez bien un instantané EBS.
Restauration avec un AMI
Cela crée un nouveau serveur. Pensez à supprimer ou à arrêter celui qui est "cassé" si vous ne voulez pas payer un second serveur. Aller dans "Images" > "AMI" (voir capture plus haut), sélectionner la sauvegarde et de cliquer sur "Lancer". Un nouveau serveur sera alors lancé à partir de cet AMI, ce qui restaurera votre serveur dans l'état où il était au moment de la sauvegarde. Si vous aviez créé une IP Elastic pour votre serveur, il vous suffit simplement de l'associer au nouveau serveur.
Supprimer les vieux AMIs
Pour ne pas dépasser l'usage gratuit d'AWS, le mieux est de faire le ménage régulièrement dans vos vieux AMIs. Faites "Actions" > "Annuler l'inscription" pour supprimer l'AMI. Votre instantané EBS ne sera pas automatiquement supprimé. Rendez-vous ensuite dans les instantanés EBS puis faites "Actions" > "Supprimer". Ce sont les instantanés EBS qui prennent vraiment de la place, donc n'oubliez pas cette étape !
Sauvegarde avec un instantané EBS
Rendez-vous dans le menu "Elastic Block Store" > "Volume". Sélectionnez le disque qui correspond à l'instance que vous voulez sauvegarder. Ici ça sera facile, vous n'avez qu'un seul volume normalement.
Cliquez ensuite sur "Action" > "Créer un instantané". On vous demande de donner un nom à cet instantané :
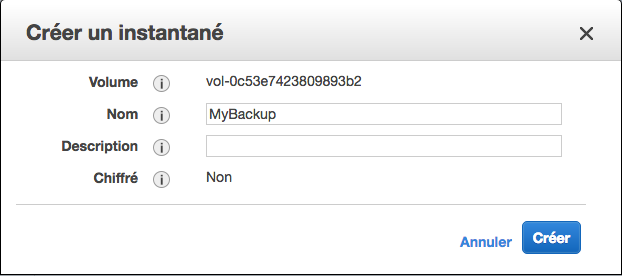
Une fois l'instantané créé, il apparaît dans "Elastic Block Store">"Instantanés"
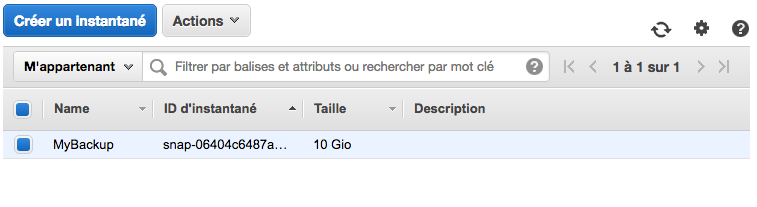
Restauration avec un instantané EBS
C'est là que ça se corse. Commencez par sélectionner votre instantané EBS puis cliquez sur "Actions" > "Créer un volume" :
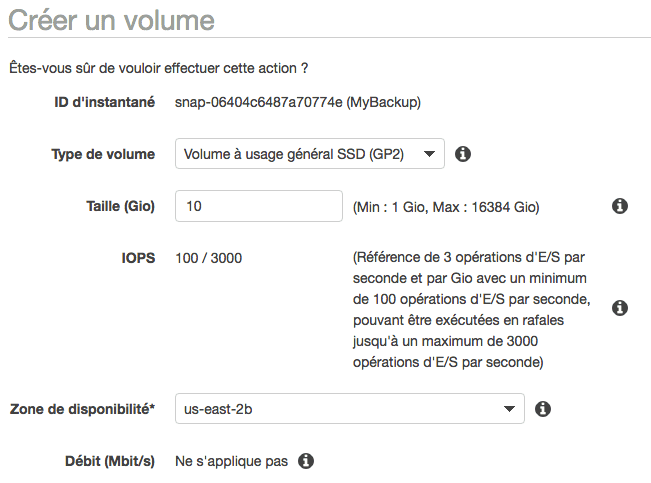
Les régions AWS sont divisées en sous-zones de disponibilités. Vérifiez que vous créez bien le volume dans la même zone de disponibilité que votre instance. Au bout d'un moment, un nouveau volume EBS est créé à partir de votre instantané.
Ce n'est pas fini. Il faut maintenant :
Arrêter l'instance EC2.
Détacher le volume EBS "cassé" actuellement associé à l'instance. Depuis les volumes EBS, faites "Actions" > "Détacher un volume".
Attacher le volume EBS "propre" issu de la sauvegarde. Depuis les volumes EBS, faites "Actions" > "Attacher un volume".
Démarrer l'instance EC2.
Supprimer le volume EBS "cassé" qui ne sert plus à rien.
Supprimer les vieux instantanés EBS
Si vous ne voulez pas stocker trop de sauvegardes (ce qui peut finir par coûter de l'argent), vous pouvez supprimer les anciennes sauvegardes dans la page "Instantanés". Comme les sauvegardes sont incrémentielles, celles-ci ne prennent heureusement pas trop de place en général.
2.10. Monter une base de données sur RDS
Pourquoi faire tourner un serveur RDS à part alors qu'on peut installer un logiciel de base de données (comme MySQL) directement sur le serveur EC2 où on peut tout faire ? Amazon RDS est une forme particulière de PaaS qu'on appelle... DBaaS (Database as a Service). Plutôt que d'installer et configurer vous-mêmes le serveur de base de données, vous commandez un serveur spécifique et optimisé pour votre base de données.
Vous n'avez pas à installer le logiciel de base de données (MySQL, PostgreSQL, MariaDB, Oracle...). C'est déjà fait pour vous !
Vous n'avez pas à configurer le moteur de base de données. La configuration de base est déjà optimisée pour vous.
Vous n'avez pas à choisir le matériel de vos serveurs. Amazon a déjà choisi des serveurs optimisés pour la gestion des bases de données.
Vous n'avez pas besoin de mettre à jour le logiciel de base de données. C'est fait pour vous par Amazon. Cela vous fait une source de stress en moins : les patchs de sécurité sont régulièrement installés pour vous.
La sauvegarde et la restauration des bases de données peut se faire en quelques clics. Et rien que ça, ça n'a pas de prix.
Vous pouvez augmenter la puissance du serveur si nécessaire, en fonction de votre trafic (comme EC2).
Vous pouvez lancer facilement plusieurs serveurs de base de données en réplication (la base de données est copiée en temps réel sur plusieurs serveurs). Cela vous sera très pratique si votre site devient gros !
Il y a quand même des rares cas où vous voudrez peut-être gérer vous-mêmes le serveur de base de données (par exemple en l'installant sur votre instance EC2). C'est le cas si vous voulez faire très simple et tout mettre sur un seul serveur, ou au contraire si vous avez des besoins de configuration extrêmement spécifiques. Quand vous utilisez RDS, vous avez le choix de votre moteur de base de données. Les plus connus sont disponibles : - MySQL - MariaDB (qui est un fork de MySQL) - PostgreSQL - Oracle - SQL Server - ... et Amazon Aurora
Amazon Aurora est un moteur de base de données spécifique conçu par Amazon: - Compatible avec MySQL et PostgreSQL. Peut s'administrer avec phpMyAdmin. - Propriétaire. Le code source d'Aurora n'est pas ouvert. En revanche, vous pouvez normalement importer/exporter les données à tout moment si nécessaire. - Plus rapide. Amazon indique qu'il est 5x plus rapide que MySQL et 3x plus rapide que PostgreSQL. Il est surtout optimisé pour le cloud d'Amazon.
Amazon propose aussi une base de données NoSQL : DynamoDB. Il s'agit d'une base de données propriétaire spécifique à Amazon, sur le même principe qu'Aurora. Le service DynamoDB est proposé à part. Il ne fait donc pas partie de RDS (qui est réservé aux bases de données relationnelles). Si vous avez déjà une base de données qui tourne sur un autre serveur, sachez qu'il existe un service d'aide à la migration vers RDS : AWS Database Migration Service.
2.11. Lancer un serveur RDS
Rendez-vous sur la section Relational Database Service (RDS) sur votre console AWS.

Voici quelques-un des menus à connaître : - Instances : la liste de vos serveurs RDS. - Clusters : si vous avez un gros trafic et que vous voulez copier votre base de données en temps réel sur plusieurs serveurs, vous aurez besoin de créer un cluster pour regrouper vos serveurs. C'est une fonctionnalité plus avancée. - Instantanés : les sauvegardes de vos bases de données.
Il y a d'autres sections comme vous le voyez : groupes de sous-réseaux, de paramètres, d'options, évènements. . . On peut s'en servir pour faire une configuration plus poussée de nos serveurs et suivre leur utilisation.
Lancer une instance RDS
La 1ère question qu'on nous pose est celle du choix du moteur de base de données

Comme promis, il y a du choix ! Aurora est optimisé pour RDS et compatible avec MySQL et PostgreSQL, mais il n'est pas open source et n'est pas disponible dans l'offre gratuite. Nous allons donc utiliser MySQL ici.
On nous demande ensuite ce que nous comptons faire de la base de données :
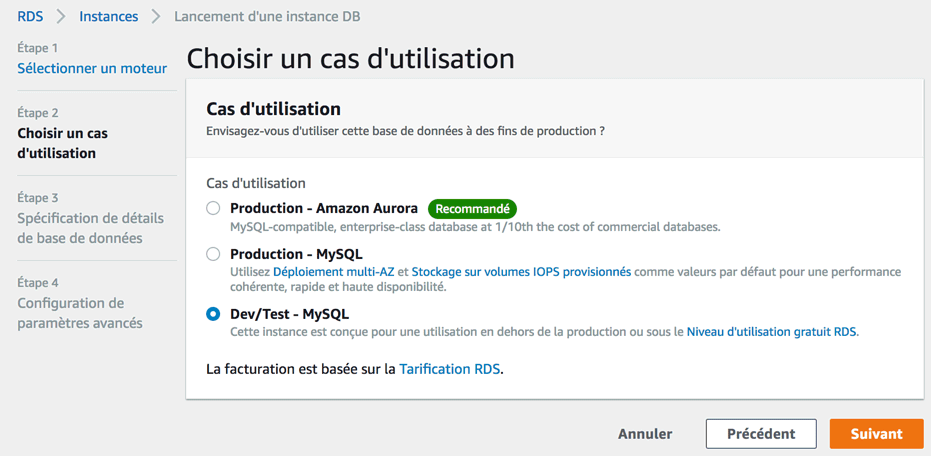
En fait, vous avez surtout le choix entre le mode "production" et le mode "Dev/Test". Le mode production est optimisé : le serveur est répliqué et il est plus puissant. C'est effectivement conseillé pour un gros site qui tourne.
Pour nos besoins de test, le mode "Dev/Test" ira très bien. D'ailleurs, c'est la seule option qui soit gratuite.
On vous demande ensuite de faire quelques choix importants pour configurer votre serveur :
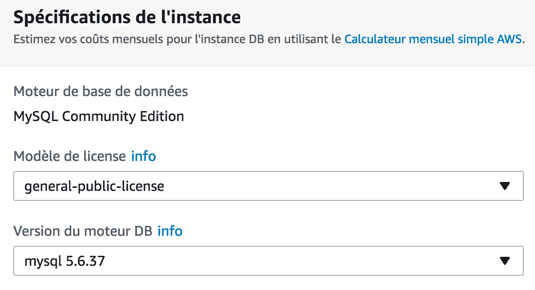
On vous demande tout d'abord quelle version de MySQL vous souhaitez utiliser. A moins que vous ayez un besoin précis, laissez la valeur par défaut.
Plus bas sur la même page, vous trouverez de nombreuses autres options :
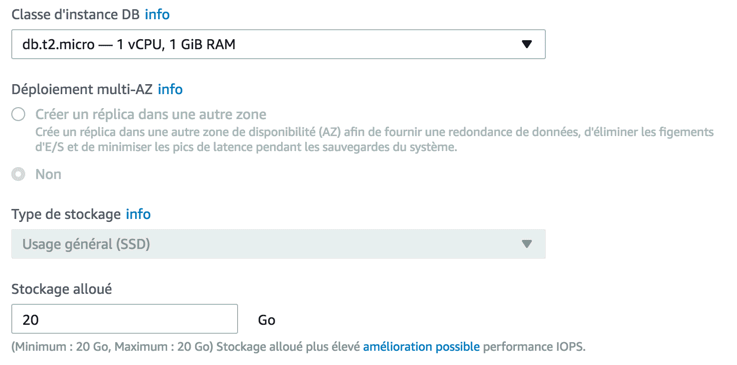
Choisissez le type de serveur et la taille de la base. Une option permet d'afficher uniquement les choix compatibles avec l'usage gratuit. Il vous faut ensuite donner un nom à votre instance (appelez-la comme vous voulez). Vous devrez aussi indiquer un nom d'utilisateur pour vous connecter à la base et un mot de passe :
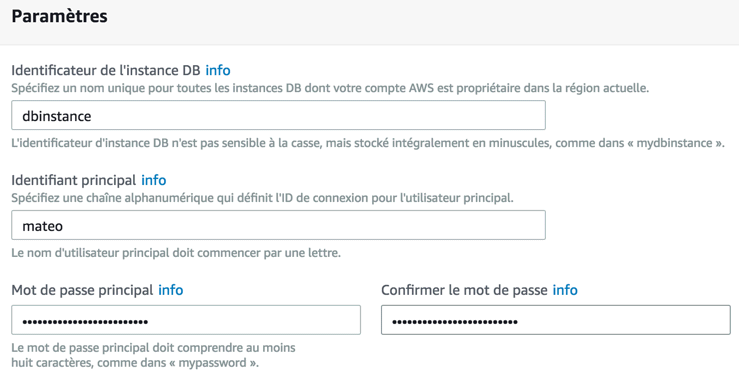
Configuration des paramètres avancés
Le choix du VPC ou vous souhaitez lancer votre serveur est une option importante Le VPC est un sous-réseau qui vous permet de "regrouper" vos serveurs entre eux, pour qu'ils communiquent plus facilement et en toute sécurité.
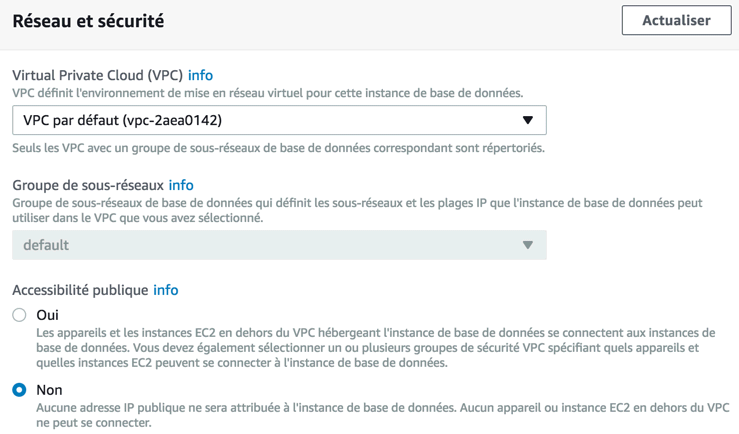
Avec la bonne configuration, votre serveur RDS est "protégé" du monde extérieur.
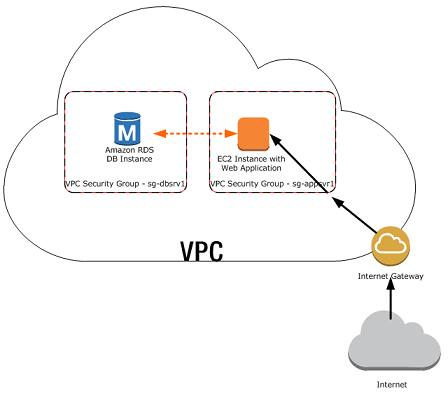
Si vous désactivez bien "Accessibilité publique" dans les options, alors votre serveur RDS n'aura même pas d'IP publique; il ne sera pas accessible depuis Internet, et c'est une bonne chose. Une autre option vous permet de choisir la durée de sauvegarde (par défaut : 7 jours). Nous pouvons maintenant voir que notre instance est lancée et tourne, si nous allons dans la section "Instances" de RDS.
Si vous cliquez sur le nom de l'instance, vous aurez tous les détails sur celle-ci. L'un de ceux qui vous sera le plus utile est le point de terminaison de l'instance (son adresse). Prenez-en note, vous en aurez besoin pour indiquer où se trouve votre serveur SQL afin de vous y connecter dans vos scripts !

Avec la console: mysql -h dbinstance.cmo5fnknxzqh.us-east-2.rds.amazonaws.com -umateo -p
2.12. Sauvegarder et restaurer la base de données
Pour lancer une sauvegarde manuellement, il vous suffit de sélectionner le serveur et de demander à "Prendre un instantané" :
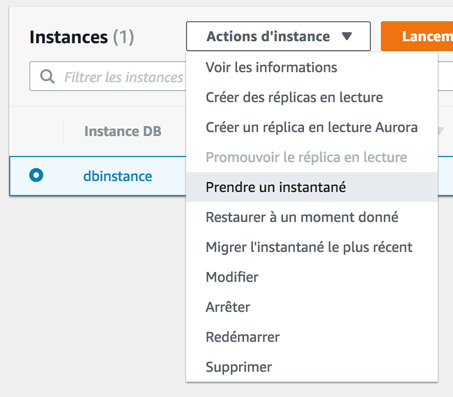
On vous demandera juste de nommer votre instantané, pour que vous puissiez le retrouver facilement. Aller dans le menu... "Instantanés" pour les retrouver.
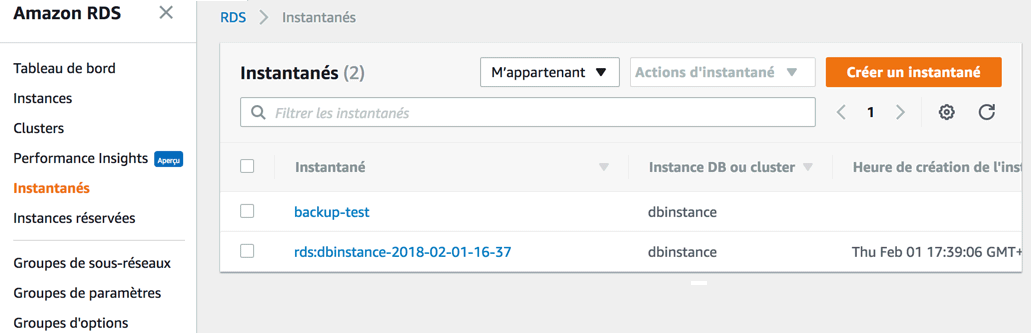
Pour restaurer un instantané, vous avez plusieurs choix :
Dans "Instantanés", sélectionnez un instantané, allez dans le menu déroulant et cliquez sur "Restaurer l'instantané". Votre serveur sera alors restauré dans l'état dans lequel il était au moment de la prise de l'instantané.
Dans "Instances", sélectionnez votre instance, puis dans le menu déroulant cliquez sur "Restaurer à un moment donné". Plus précise, cette méthode vous permet de retrouver votre serveur à la seconde près. RDS fait en effet des backups continus.
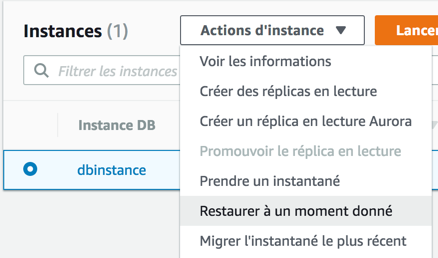
La restauration du serveur RDS aura pour effet de créer un nouveau serveur.
2.13. utiliser RDS depuis son serveur web EC2
Nous avons maintenant: un serveur web EC2, un serveur RDS. l'AMI LAMP de Bitnami fournit un serveur MySQL intégré. Pour accéder à votre base de données sur RDS ? Selon la configuration de l'accessibilité publique au lancement du serveur :
Si vous avez autorisé l'accessibilité publique : vous pouvez administrer votre serveur depuis votre ordinateur avec un logiciel comme MySQL Workbench.
Si vous avez interdit l'accessibilité publique : vous ne pouvez pas toucher au serveur RDS depuis votre machine. Vous devez passer par EC2.
Notez que vous pouvez changer l'accessibilité publique du serveur à tout moment, en cliquant sur "Actions d'instance" > "Modifier" depuis RDS.
Se connecter au serveur RDS depuis sa machine
Pour pouvoir vous connecter depuis votre machine, vérifiez :
- Que votre serveur RDS autorise l'accessibilité publique
- Que le groupe de sécurité utilisé par votre serveur RDS autorise bien les connexions à MySQL sur le port 3306 depuis votre IP. Les groupes de sécurité peuvent être configurés dans l'interface EC2 d'AWS.
Créer sa base de données
Depuis votre machine, ouvrez un client SQL comme MySQL Workbench. Créez une nouvelle connexion en indiquant le point de terminaison (nom d'hôte) de votre serveur RDS. Je vous rappelle que cette information peut être trouvée si vous cliquez sur votre serveur RDS.
Point de terminaison Port Accessible publiq. dbinstance.cmo5fnknxzqh.us-east-2.rds.amazonaws.com 3306 Oui
Indiquez aussi le nom d'utilisateur et le mot de passe que vous aviez définis pour le serveur (il faudra faire "Store in Keychain" pour stocker le mot de passe). Si vous cliquez sur "Test Connection", vous devriez avoir confirmation que cela fonctionne. Cliquez ensuite sur la connexion nouvellement créée pour vous retrouver sur l'administration du serveur MySQL. Vous pouvez faire tout ce que vous voulez à partir de là. Workbench est un outil très complet. Vous pouvez créer autant de bases de données que vous voulez, y créer des tables, etc.
Accèder à la base depuis PHP
Envoyez les fichiers php sur EC2 avec un logiciel SFTP comme FileZilla.
2.14. Simple Storage Service (S3)
Amazon Simple Storage Service (abrégé S3) est un service de stockage de données. Il s'agit d'un moyen de stocker des fichiers sur Internet. Il s'agit du service le plus célèbre d'AWS avec EC2. Il y a un usage gratuit de 5 Go de stockage. En temps normal, vous payez pour l'espace nécessaire, mais aussi pour le nombre d'envois et de téléchargements des fichiers, ainsi que la bande passante utilisée. Bref, ça a un coût, mais raisonnable si vous n'en avez pas un très gros usage. Il sert à stocker toutes sortes de fichiers sur Internet. Par ex : les fichiers vidéo, les images, les backups de bases de données.
Voici une petite liste d'avantages que S3 vous apporte : - Vous pouvez configurer facilement les droits d'accès pour chaque fichier. Qui peut lire, modifier et supprimer chaque fichier.
Vous pouvez chiffrer toute une partie du contenu sur S3 si vous le souhaitez pour des raisons de sécurité.
Vos fichiers peuvent être versionnés : vous pouvez revenir à une version précédente à tout moment !
Vos fichiers peuvent avoir une date d'expiration et être supprimés automatiquement au bout d'un moment.
Vos fichiers peuvent être répliqués automatiquement sur plusieurs datacenters AWS. Ainsi, vous diminuez le risque de perdre des données importantes.
Il n'y a pas de limite de place. Vous ne risquez pas d'être bloqués par un disque dur rempli.
Amazon S3 propose de stocker des données dans des buckets (littéralement des... seaux). Ce sont des sortes de gros conteneurs qui peuvent stocker autant de fichiers que l'on veut (répartis dans des dossiers à l'intérieur s'il le faut).
A l'intérieur de chaque bucket, vous pouvez déposer des fichiers (on parle d'objets) et y associer des métadonnées. Vous pouvez indiquer ce que vous voulez dans ces métadonnées (l'auteur du fichier par exemple).
Rendez-vous sur S3 (Simple Storage Service) dans votre console AWS. Vous devriez voir qu'il n'y a pour l'instant aucun bucket (compartiment) :
Si la page n'est pas vide et que vous voyez des buckets, ce sont probablement des buckets créés précédemment par Elastic Beanstalk. N'hésitez pas à les supprimer. Si ça ne fonctionne pas, il faut modifier les droits du bucket pour pouvoir les supprimer.
Création d'un bucket
Cliquez sur "Créer un compartiment".
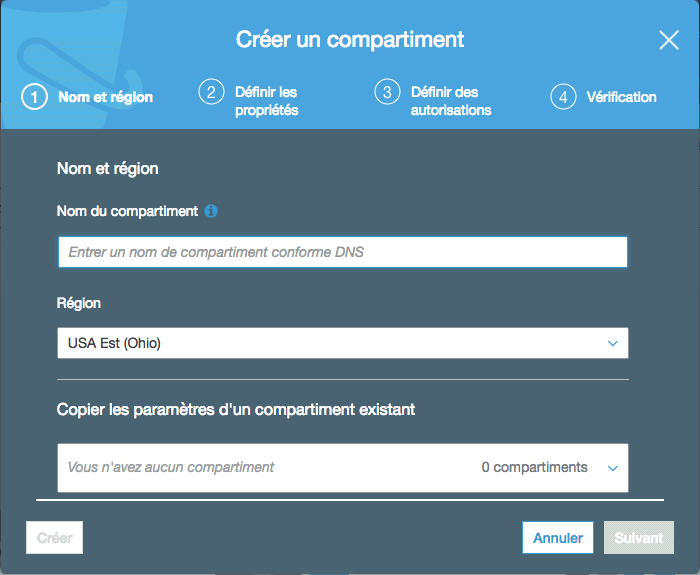
Il vous faudra donner un nom unique à votre bucket. Ce nom ne doit jamais avoir été utilisé par quelqu'un d'autre (un peu comme les noms de domaine ! ). Je vais appeler le mien "mateotestbucket", celui-là n'est pas pris ! Vous pouvez aussi indiquer ici la région où le bucket sera créé.
Passez à l'étape suivante :
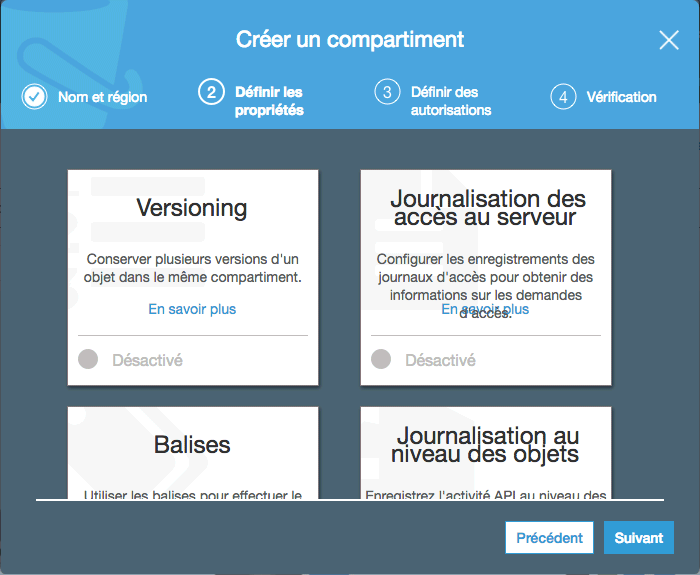
Nous n'allons utiliser aucune de ces options, mais pour information en voici quelques-unes qui pourraient vous intéresser dans le futur :
Versioning : permet d'activer le versioning des fichiers. Si vous écrasez un fichier par une nouvelle version, l'ancienne version reste sauvegardée au cas où en ayez besoin.
Balises : comme pour les serveurs, les balises permettent de "marquer" les fichiers pour les retrouver plus facilement par la suite. C'est une façon de les regrouper par thème.
Journalisation : conserve une trace de ce qu'il s'est passé dans le bucket.
Chiffrement : chiffre les données, si ce sont des données sensibles.
L'étape suivante, vous demande quelles autorisations vous voulez définir :
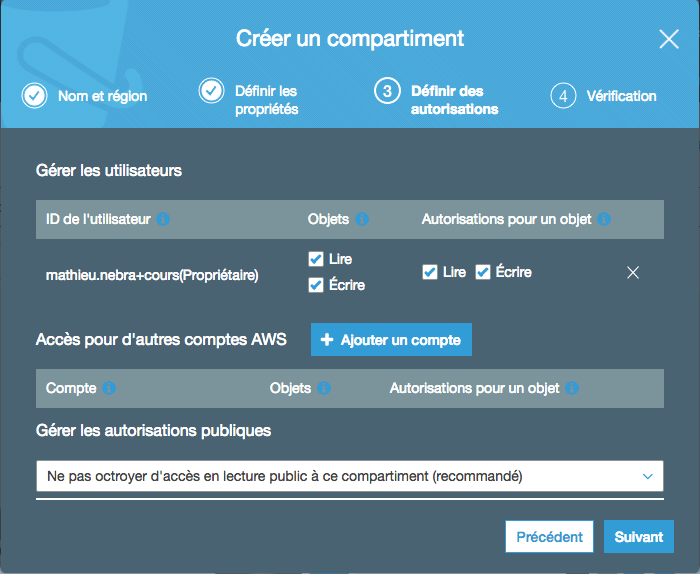
Ici, par défaut :
Votre utilisateur pourra lire et écrire des objets dans le bucket, et il pourra ensuite lire et écrire par-dessus chaque objet. En gros, vous pouvez tout faire.
Le bucket n'est pas accessible publiquement (c'est "recommandé"). En gros, à part vous, le reste du monde ne peut rien faire, même pas lire les fichiers.
A la fin, on vous fait un récapitulatif et vous n'avez qu'à valider :
Après quelques instants, votre bucket est créé :
Ajouter et modifier des objets dans le bucket
Cliquez sur le bucket pour rentrer à l'intérieur. Pour l'instant, il est vide.
Les onglets tels que "Propriétés" et "Autorisations" vous permettent de modifier le fonctionnement de votre bucket après sa création. Si vous allez dans "Gestion", vous pouvez aussi avoir accès à des statistiques d'utilisation, mettre en place la réplication des données entre datacenters, ou définir une expiration des objets après un certain temps. Ici nous allons charger un fichier dans le bucket. Cliquez sur "Charger" :
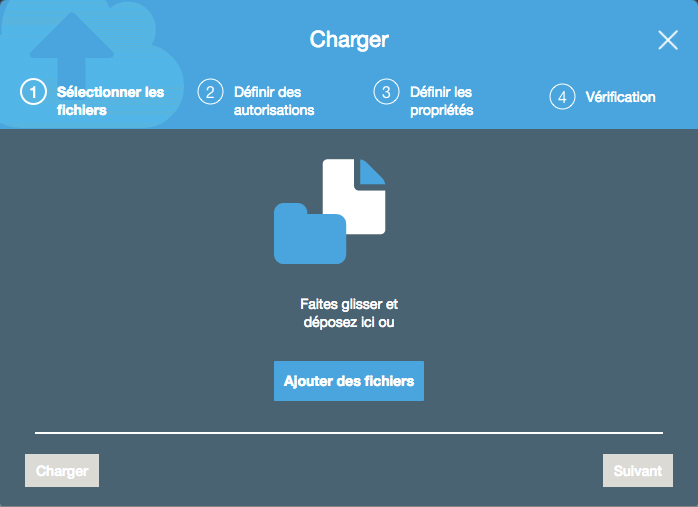
Déposez ce que vous voulez : ça peut être une image, une vidéo, un fichier ZIP.. L'assistant vous propose, de définir des autorisations et propriétés spéciales pour cet objet. Ce n'est pas obligatoire : par défaut l'objet va prendre les autorisations configurées dans le bucket. Vous pouvez donc vous contenter de cliquer sur "Charger".
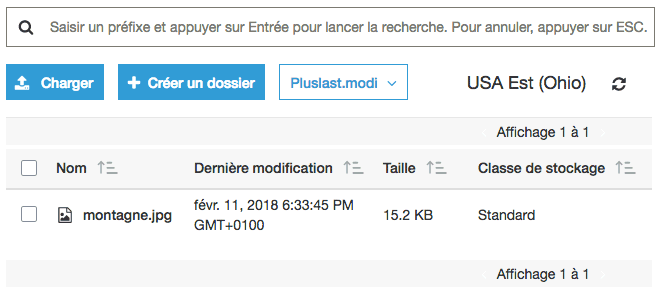
Il ya plusieurs classes de stockage dans les trois, donc la classe par défaut, c'est ce qu'on appelle la classe standard. Il ya une classe qui s'appele "IA" (infrequent access) qui est moins cher à condition que vous n'accédiez pas aux fichiers. Donc pour des fichiers que vous voulez garder en ligne mais dont vous n'avez pas besoin souvent (peut-être une fois par mois). Eh bien ça peut valoir la peine d'utiliser cette classe de stockage afin de faire des économies.
On peut faire ça avec les APIs AWS, en ligne de commande (après avoir installer AWS CLI). Par exemple aws s3 ls s3://mateotestbucket/
Si vous cliquez sur le fichier uploadé, vous verrez plus d'informations :
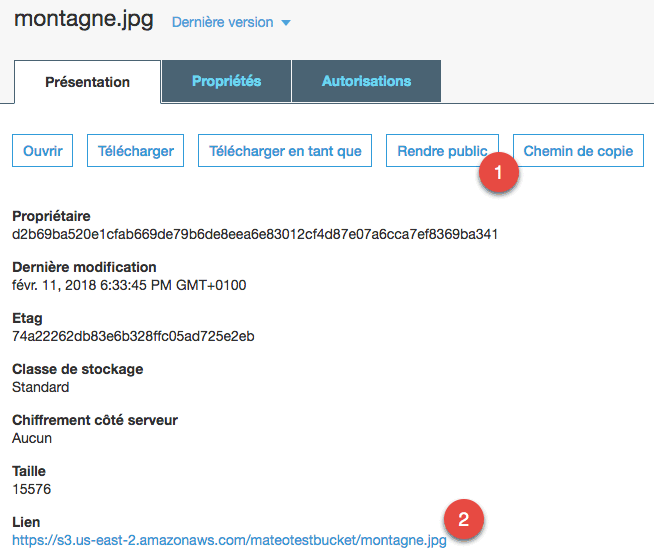
D'ici, vous pouvez le télécharger, modifier ses propriétés, etc. Deux éléments me semblent particulièrement intéressants :
"Rendre public" vous permet de rendre ce fichier public. Si vous ne le faites pas, aucune personne extérieure ne pourra télécharger le fichier.
Le "lien" qui vous permet d'accéder au fichier. Si celui-ci n'est pas public, vous verrez un message d'erreur XML à la place.
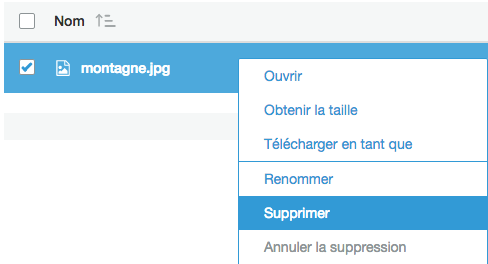
Une fois le fichier rendu public, vous pouvez le rendre privé à nouveau en allant dans les autorisations, puis en décochant le droit "Lire l'objet" pour "Everyone". Si vous souhaitez au contraire supprimer le fichier, faites un clic droit dessus depuis la liste des fichiers et choisissez "Supprimer" :
L'interface d'AWS est pratique, mais en fait on passe généralement par une API. Les API d'AWS sont très bien faites. Celle de S3 peut être utilisée pour charger des fichiers depuis votre site web, comme nous le verrons plus tard.
2.15. Définir les droits d'accès à S3
Les droits d'accès à un bucket et ses fichiers sont déterminés par un processus assez complexe de policies (règles). Je vais tenter de vous le simplifier.
Il y a 2 types de règles :
User policy : définit ce qu'un utilisateur a le droit de faire. Ex: Jennifer a le droit de lire et modifier tous les fichiers dans le bucket A, ainsi que d'ajouter des fichiers PNG dans le bucket B
Resource-based policy : définit ce qu'on a le droit de faire sur un bucket ou un fichier. Ex: Dans le bucket A, Jennifer a le droit de lire et modifier tous les fichiers, tandis que Patrick a le droit uniquement d'ajouter des fichiers.
Les utilisateurs dans AWS sont créés via le service IAM. L'utilisateur principal dont vous vous servez actuellement est appelé "root". Il est recommandé de créer des utilisateurs IAM, plutôt que de passer par le compte root.
Structure d'une resource-based policy
Voici une policy très simple. Elles sont écrites au format JSON :
{ "Version":"2012-10-17", "Statement": [ { "Effect":"Allow", "Principal": "", "Action":["s3:GetObject"], "Resource":["arn:aws:s3:::examplebucket/"] } ] }
Version : c'est le numéro de version de la policy. Ne mettez pas la date du jour, copiez la même date que moi (ça revient en gros à dire "j'utilise la version 3 du système de policy").
Statement : ce sont les règles de la policy. Ici, il y en a une seule. Voyons ce que ça dit à l'intérieur :
Effect : Allow (autoriser) ou Deny (refuser). Par défaut, tout est refusé par sécurité. Il faut donc explicitement autoriser des choses.
Principal : le nom de l'utilisateur à qui on donne le droit. Ici, "*" signifie "tout le monde, y compris le grand public sur internet sans compte AWS".
Action : c'est l'action qu'on veut autoriser (ou plusieurs). Ici, s3:GetObject permet de télécharger un objet (un fichier). La liste des actions peut être retrouvée dans la doc. Oui, il y en a beaucoup ! Parmi les plus importantes, citons : - s3:DeleteObject: autorise la suppression des fichiers - s3:GetObject: autorise la lecture des fichiers et leur téléchargement - s3:PutObject: autorise l'ajout de fichiers - s3:ListBucket: autorise la récupération de la liste de fichiers dans le bucket - s3:ListAllMyBuckets: autorise l'affichage de la liste de tous les buckets.
Resource : le nom de la ressource qui est autorisée. Il y a un format un peu spécial. Ici, arn: aws: s3: : : examplebucket/* indique qu'on effectue l'autorisation sur tous les fichiers ( * ) du bucket nommé examplebucket .
Exemple 1 :
{ "Version": "2012-10-17", "Id": "ExamplePolicy01", "Statement": [ { "Sid": "ExampleStatement01", "Effect": "Allow", "Principal": { "AWS": "arn:aws:iam::Account-ID:user/Dave" }, "Action": [ "s3:GetObject", "s3:GetBucketLocation", "s3:ListBucket" ], "Resource": [ "arn:aws:s3:::examplebucket/*", "arn:aws:s3:::examplebucket" ] } ] }
Cette policy autorise l'utilisateur Dave (créé sur AWS IAM) à lire un objet, connaître la localisation d'un bucket et à lister le contenu du bucket. Si vous vous demandez comment je connais la signification des actions, c'est parce que j'ai lu la doc, moi). Les ressources qui sont affectées sont examplebucket et tous ses fichiers à l'intérieur.
Exemple 2 :
{ "Version":"2012-10-17", "Id":"ExamplePolicy02", "Statement":[ { "Effect":"Allow", "Principal":{ "AWS":"" }, "Action":"s3:GetObject", "Resource":"arn:aws:s3:::my-brand-new-bucket/public/" }, { "Effect":"Allow", "Principal":{ "AWS":"arn:aws:iam::Account-ID:user/Dave" }, "Action":[ "s3:PutObject", "s3:DeleteObject" ], "Resource":"arn:aws:s3:::my-brand-new-bucket/*" } ] }
Cette policy autorise tout le monde à lire les objets dans le dossier "public" de "my-brand-new-bucket". Cela veut dire que n'importe quel internaute pourra télécharger les fichiers du dossier "public" de ce bucket, s'il connaît son URL. Si vous hébergez les images de votre site sur S3, vous aurez sûrement besoin de donner ce genre de droit.
Cette policy donne aussi d'autres autorisations (vous pouvez voir qu'il y a 2 statements). Elle dit que Dave peut ajouter et supprimer des fichiers partout dans ce bucket.
En résumé : tout le monde peut lire les fichiers dans "public", mais seul Dave peut en ajouter ou en supprimer.
Activer une policy
Si vous voulez ajouter une policy au format JSON pour un bucket, comme on vient de le voir, il faut aller dans le bucket, onglet "Autorisations" / "Stratégies de compartiment" :
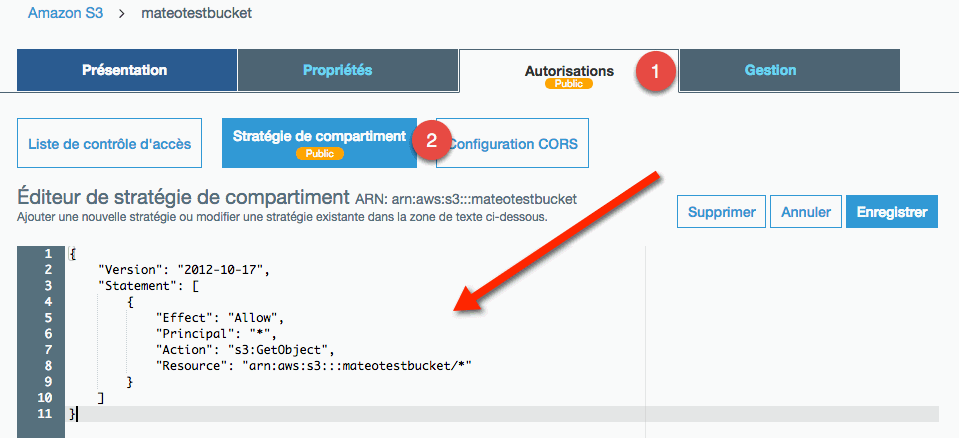
La policy ci-dessus autorise la lecture de fichiers par tout le monde dans le
bucket. Elle rend donc le bucket public. Une fois la policy enregistrée, elle
est immédiatement activée (s'il n'y a pas d'erreurs). S3 m'avertit que du coup
le bucket est public et qu'il faut être prudent de ne pas y partager de données
confidentielles. Il existe un générateur de policies en ligne, pour vous aider à
les écrire. https://awspolicygen.s3.amazonaws.com/policygen.html
2.16. TP S3 le Cloud Uploader
Nous allons créer un bucket qui permet de stocker tous les uploads de nos visiteurs sur notre site. Pourquoi ne pas stocker les uploads du site sur le serveur EC2 ? Parce que ce n'est vraiment pas pratique. Si vous changez de serveur, il faudrait sauvegarder les données et les transférer. Et si vous avez 2 serveurs, parce que votre trafic a augmenté, sur quel serveur laisseriez-vous les uploads ?
Installation du SDK
Pour accéder à S3, je vous invite à télécharger le SDK d'AWS, qui simplifie l'accès à AWS depuis votre code source. Le SDK est disponible pour de nombreux langages : C++, Go, Java, JavaScript, Python, Ruby... et PHP. Je vais ici partir sur PHP qui est le langage que je pratique le plus couramment, mais vous verrez que la méthode est pratiquement la même si vous utilisez un autre langage.
Télécharger le SDK AWS pour PHP. On vous propose plusieurs méthodes : Composer, Phar ou... ZIP. Si vous avez l'habitude de Composer, utilisez cette méthode car elle facilite grandement la gestion des bibliothèques.
Pour utiliser le SDK, il faudra se connecter avec une clé API. Pour obtenir cette clé, il faut impérativement créer un utilisateur avec le service IAM. IAM permet de gérer les utilisateurs qui ont accès à son compte AWS. Rendez-vous sur IAM pour créer un nouvel utilisateur :
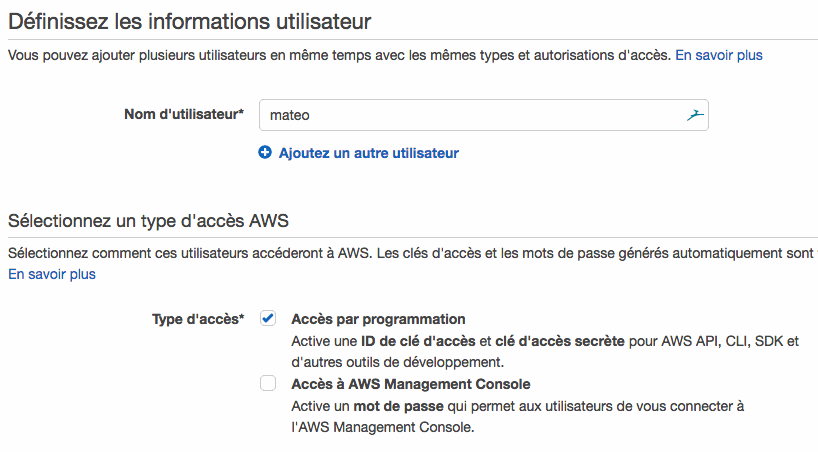
Donnez un nom à cet utilisateur et autorisez-le au moins à accéder à AWS par programmation (vu qu'il ne nous servira qu'à ça, pas besoin de lui ouvrir un accès web à la console) :
Ensuite, il faudra donner des droits à cet utilisateur. Pour cela, on vous propose de le rattacher un groupe. Pas de bol, vous n'en avez pas. Il va falloir en créer un :
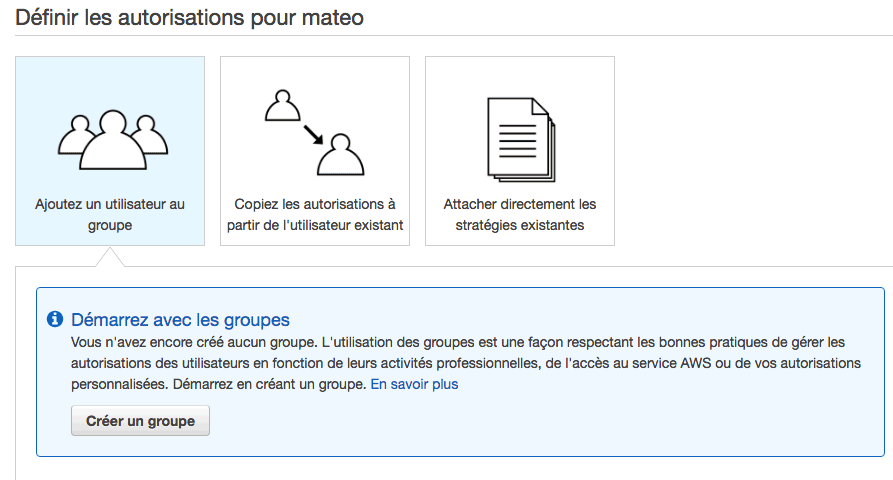
On va rester très simple ici et créer un groupe "admin" avec des droits d'admin. Cet utilisateur peut donc tout faire.
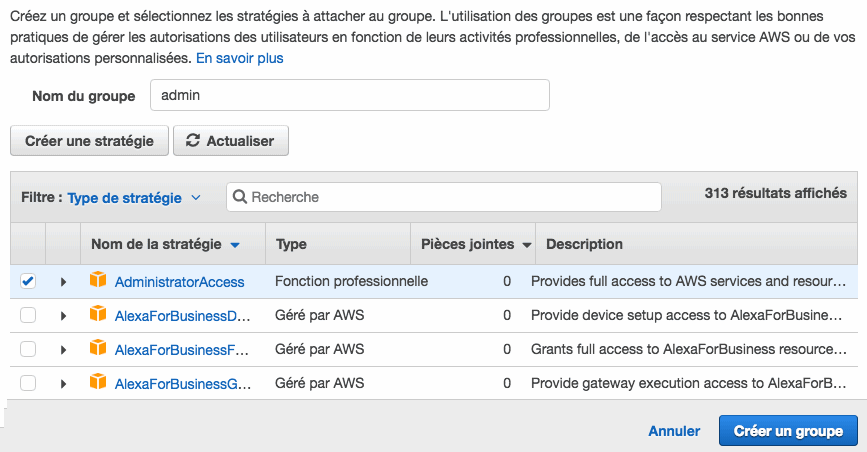
Enfin, l'utilisateur est créé et vous pouvez afficher les informations qui nous intéressent :

L'ID de clé d'accès et la clé d'accès secrète sont les 2 informations dont vous avez besoin pour vous connecter à AWS depuis votre programme.
Il y a plusieurs façons de stocker ces identifiants pour vous connecter. La plus pratique et la plus sûre, à mon sens, consiste à créer un fichier ini placé dans votre dossier home à l'emplacement suivant : ~/.aws/credentials . Ce fichier contiendra vos clés comme ceci :
[default] aws_access_key_id = VOTRE_ACCESS_KEY aws_secret_access_key = VOTRE_SECRET_ACCESS_KEY
Le fichier est prêt ? Super ! On va pouvoir commencer à programmer !
Développement du projet
index.php
<!DOCTYPE html>
<html>
<head>
<meta charset="utf-8" />
<title>Cloud Uploader</title>
</head>
<body>
<h1>Bienvenue dans le Cloud Uploader</h1>
<p>Qu'allez-vous uploader aujourd'hui ?</p>
<form method="post" action="upload.php" enctype="multipart/form-data">
<p><input type="file" name="uploadfile" /></p>
<p><input type="submit" value="Uploadez-moi !" /></p>
</form>
</body>
</html>
upload.php
<?php
require 'aws/aws-autoloader.php';
use Aws\S3\S3Client;
// TODO : indiquez le nom de votre bucket
$bucket = 'mateotestbucket';
// TODO : les accès à AWS doivent déjà être configurés dans un fichier .ini
// Voir : https://docs.aws.amazon.com/aws-sdk-php/v3/guide/guide/credentials.html#credential-profiles
$s3 = new S3Client([
// TODO : indiquez le nom de la région de votre bucket S3
'region' => 'us-east-2',
'version' => '2006-03-01'
]);
// Envoi du fichier
$result = $s3->putObject(array(
'Bucket' => $bucket,
'Key' => time() . '_' . $_FILES['uploadfile']['name'],
'SourceFile' => $_FILES['uploadfile']['tmp_name'],
));
echo '<p>Fichier uploadé !</p>';
echo '<p><a href="' . $result['ObjectURL'] . '">' . $result['ObjectURL']
. '</a></p>';
echo '<p><img src="' . $result['ObjectURL'] . '" alt="" /></p>';
Voici ce que fait ce code :
Il charge le SDK de AWS (qui doit ici être dans un sous-dossier "aws").
Il se connecte à S3, sur la région us-east-2 (là où j'ai créé mon bucket). Notez que les identifiants de connexion ne sont pas dans le code source pour des raisons de sécurité. Ils sont dans le fichier "credentials" que je vous ai fait créer tout à l'heure.
Il envoie le fichier dans le bucket indiqué. La clé "Key" indique le nom qu'aura le fichier sur S3. J'ai choisi pour ma part de prendre le timestamp actuel (via time() ) puis de lui ajouter le nom de fichier d'origine. Cela évite que 2 fichiers aient le même nom. Vous pouvez évidemment changer ça si vous voulez.
Il affiche enfin un lien vers le fichier uploadé sur S3.
réf: Découvrer le cloud avec AWS
https://openclassrooms.com/fr/courses/4810836-decouvrez-le-cloud-avec-amazon-web-services
6.17. IAM
IAM (Identity and Access Management) est le service qui permet de gérer les utilisateurs. Il va servir essentiellement à 2 choses il va vous servir à gérer les utilisateurs humain donc les utilisateurs qui ont le droit de se connecter à la console, et les utilisateurs qui accèdent par programmation aux APIs AWS. Il est possible de créer des groupes d'utilisateurs, et y associer des permissions. Ou on peut attacher directement des permissions existantes aux utilisateurs. Il y en a une centaine, par exemple: - AdministratorAccess - AmazonEC2ReadOnlyAccess - AmazonEC2FullAccess
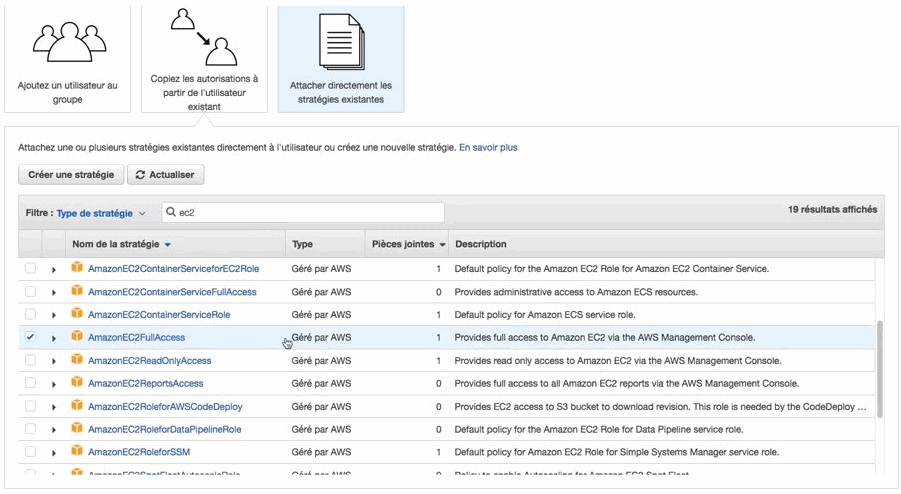
On peut regarder ce qu'il y a dedans. Donc on va retrouver à l'intérieur de cette politique qui s'appelle donc EC2 Full Access, et on voit l'accès complet au load balancing, l'accès complet à d'autres fonctionnalités de EC2.
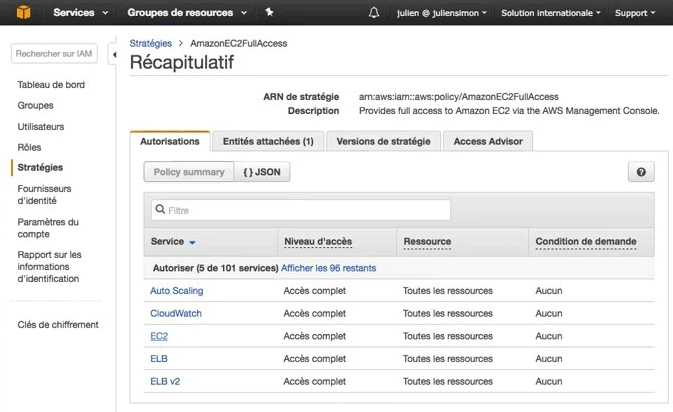
Si on zoume encore un petit peut on devrai voir la liste des permissions et l'ensemble des APIs d'EC2 qui sont autorisés.
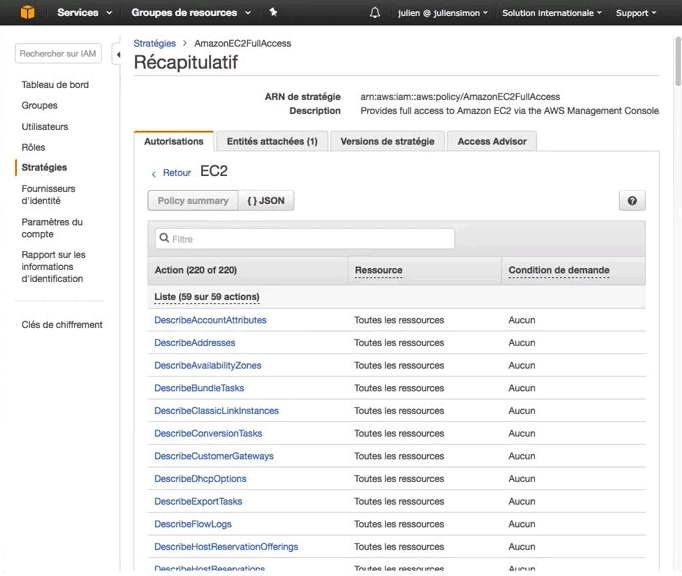
Donc l'approche de sécurité de AWS est de permettre aux clients d'autoriser ou d'interdire chaque API, et d'autoriser ou d'interdire l'accès à chaque ressources. Donc vous pourrez aller très très loin et dire j'autorise un utilisateur à accéder à une seule instance ec2 et pas aux autres, ou au contraire on pourrait dire il a le droit de modifier toutes les ressources EC2 sauf celle-là.
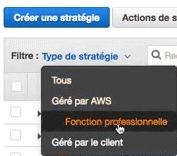
Une autre façon de le faire c'est qu'au lieu d'utiliser les policy par service on a des politiques qui sont par fonctions. AWS a défini un ensemble de politiques qui regroupe les permissions sur les services concernés. Libre à vous ensuite de spécialiser ses stratégies et de les affiner.
Pour faire des tests d'intrusion, il suffit de remplir un formulaire sur le site d'AWS. Habituellement la réponse et l'aide est apporté, sous 1 ou 2 jours ouvrés pour pouvoir faire les tests. Pour des tests d'intrusion de manière un peu plus automatisée et plus simple que d'avoir à redéclarer ces tests. En travaillant avec la marketplace et typiquement avec des fournisseurs tels que Qualis qui est un grand fournisseur de sécurité qui est un partenaire amazon. Si vous utilisez qualys dans vos data centers, vous pouvez travailler avec qualis, et lancer des instances qualys directement sur AWS via le marketplace, et ses instance là sont prêts validé pour faire des tests d'intrusion, et vous n'avez plus à faire de déclaration préalable. Juste le fait que ce soit une instance validé par AWS, et que ce soit certifiés par qualys comme étant une de leurs machines, ça vous permet de le faire directement.
Pour faire une boutique en ligne Amazon FBA et Jungle Scout
réf: démarrer avec Amazon EC2, IAM, Lightsail
https://www.youtube.com/watch?v=gOeFzkiqOF4
2.18. Déploiement continu avec AWS
AWS dispose de différents outils dont le premier apollo. Apollo c'est le déployeur utilisé par les équipes de développement amazone. C'est un déployeur qui marche sans aucun downtime qui va être capable de déployer en continu des changements sur une infra en production sans créer de problèmes. C'est un service qui évidemment va surveiller la qualité de qui va surveiller, la qualité du déploiement en vérifiant que les instances sur lesquels on déploie continuent à fonctionner. On va gérer des versions et bien sûr on va être capable de gérer les roll back pour revenir à un état stable si jamais on a un problème.
Le deuxième outil qui a été déployé c'est un outil qui s'appele pipeline, et comme son nom l'indique c'est un outil de déploiement de livraison continus qui va permettre aux équipes de développement de construire les process de développement complètement automatisée, qui du commit jusqu'au déploiement prod; et bien vont passer les étapes de validation du 'pipeline', une par une toujours dans le même ordre, donc sans intervention humaine sans risque d'erreur humaine et de manière complètement automatisée plus vite que ce qu'une équipe humaine pourrait faire.
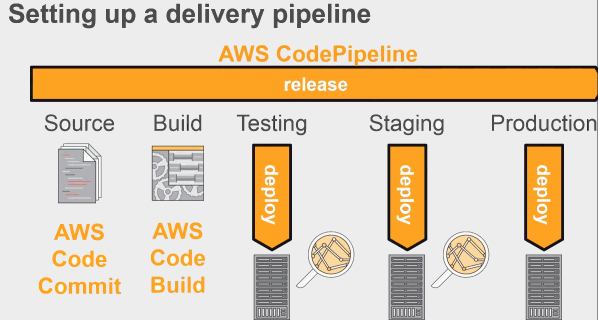
AWS Code pipeline
Il existe d'autres outils d'intégration continue, pas forcément intégré à 100 % comme gitHub, jenkins, circle ci, etc. Et tous ces outils sont intégrables dans les pipelines de déploiement de Code pipeline. Si vous avez déjà des serveurs d'intégration et de déploiement continue, vous pourrez les intégrés.
AWS Code Commit
C'est tout simplement un environnement git managé. Vous pouvez créer des repositories git à l'intérieur de votre infra AWS. Les données et les objets vont être stockés dns S3. Ils vot être chiffré avec KMS. Et vous disposez de la scalabilité, de la haute dispo, et de la durabilité de S3.
AWS Code Build
AWS CodeBuild prend en charge maintenant les générations pour la plate-forme Microsoft Windows Server, incluant un environnement de génération pré-intégré pour .NET Core 2. 0 sous Windows. Auparavant, CodeBuild prenait en charge le.NET Core sous Linux. Si votre application utilise le framework .NET, vous pouvez inclure les bibliothèques de classes du framework propriétaire de Microsoft dans une image Docker personnalisée.
Vous pouvez récupérer vos sources dans GitHub, dans S3, dans Code Commit, ou directement en fichier zip.
Vous pouvez builder dans différents environnements qu' AWS fournit, comme Java. Si cette image ne vous convient pas et vous avez un process de build particulier vous pouvez fournir un container docker, que code build va utiliser pour construire votre application. Il est possible de lancer les commandes de build, soit en ligne de commande, soit dans un fichier de configuration que vous allez commiter dans vos sources et qui être lu par Code Build. c'est un service managé ou le prix se fait à la minute de build. On commence à 1/2 cents par minute. Il y a différentes tailles d'environnement.
AWS Code Deploy
Il va prendre des applications versionés. On verra comment on les intègre dans le pipeline tout à l'heure, des artefacts versionés, et puis il va les déployer sur ce qu'on appele des groupes de déploiement qui vont être un ensemble d'instances OC2. Qui peuvent être sous linux ou Windows. Et on peut également faire le déploiement sur des serveurs extérieurs à AWS, sous réserve d'y avoir installé l'agent. Supporte l'auto scaling. Code Deploy vat trouver toutes les instances qui font partie du groupe et il vat les déployés, qu'il y en ai 2 ou qu'il y en ai 50.
AWS est capable de faire des déploiement green blue; c'est une technique de déploiement asser populaire qui consiste en gros à dupliquer le groupe de déploiement. Donc on va créer un deuxième groupe de déploiement qui fera la même taille, on va déployer sur ces instances la nouvelle version. On va vérifier que tout marche, et si tout marche, eh bien on basculera finalement la production
vers ce nouveau groupe, et on détruira l'ancien monde.
AWS Code pipeline
Il va permettre de relier toutes les étapes qu'on a vus auparavant. Vous allez écrire un pipeline avec des différentes étapes. Une étape source qui va récupérer les sources et qui va les copiées dans S3, dans un bucket que Code Pipeline va créer automatiquement. Puis une étape de build qui va compiler l'application ou la packager. Et puis dérouler les tests et remettre cet artefact de build dans S3. Et puis code deploy, ou votre environnement de build va être déployé sur un environnement beta ou de test. On peut ajouter une étape d'approbation manuelle. Puis on pourrait faire un déploiement en prod sur un groupe qui compose votre production. On peut aussi appeler des fonctions lambda pendant le pipeline. Ca coute 1$ par pipeline par mois.
Pipeline simple AWS
Source: CodeCommit repository - C sources (library for generic data structures) - buildspec.yml: fichier de configuration pour CodeBuild - appspec.yml: fichier de configuration pour CodeDeploy Build: CodeBuild 'base' environnement - installation des dépendances - construction des librairies - dérouler l es tests unitaires (Cunit) Deploy: CodeDeploy - un groupe de déploiement avec une seule instance
Le repo est dans codeCommit
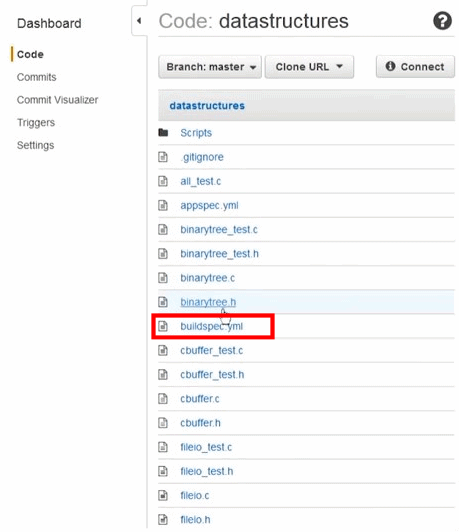
buildspec.yml
version: 0.1
phases:
install:
commands:
- apt-get update -y
- apt-get install -y build-essential libcunit1-dev
build:
commands:
- echo Build started on `date`
- echo "*** Compiling the static library"
- make libcontainer.a
- echo "*** Compiling the shared library"
- make libcontainer.so
- echo "*** Compiling unit tests"
- make all_test
post_build:
commands:
- echo "*** Running unit tests"
- make test
- echo Build completed on `date`
artifacts:
files:
- libcontainer.a
- libcontainer.so
- appspec.yml
- Scripts/afterinstall.sh
Ici il s'agit d'un environnement de build de base linux ubuntu. On installe la librairie de test unitaires "libcunit1-dev".
Et puis on a une étape de build, qui va utiliser un makefile qu'il y a dans les sources. Elle va construire la librairie statique, la librairie dynamique, et compiler les tests unitaires.
Ensuite on a une autre étape post build qui va exécuter les tests.
Tous ce qu'il y a à fournir, c'est ce fichier de configuration et puis lui dire les artéfacts. C'est à dire que le résultat de ce build, c'est les 2 librairies; c'est ce qui doit être packagé et livré dans S3 pour code Deploy ensuite. Un fichier de configuration pour codeDeploy (appspec.yml). Et ce petit script qui est appelé par le déployeur et qui va servir à faire le déploiement (copie dans usr/local/lib).
Le codeBuild est paramétré sur ubuntu avec l'adresse du répository. On peut le lancer à la main:
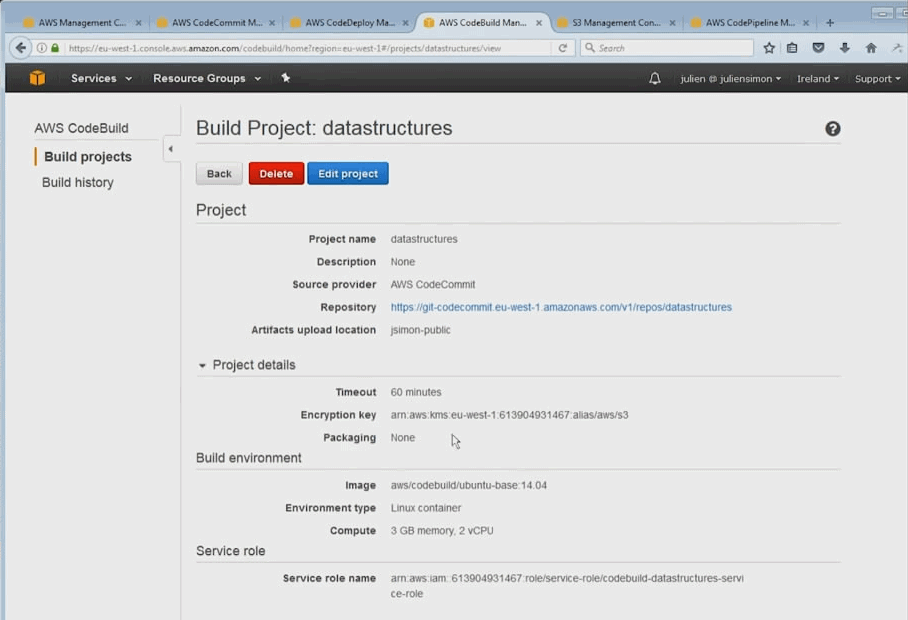
Voici le code pipeline. On a une étape source qui va aller dans mon repositoy codeCommit et qui va extraire la branche master et qui va stocker dans un bucket S3, un artéfact qui contient les sources et qui s'appelle myApp.
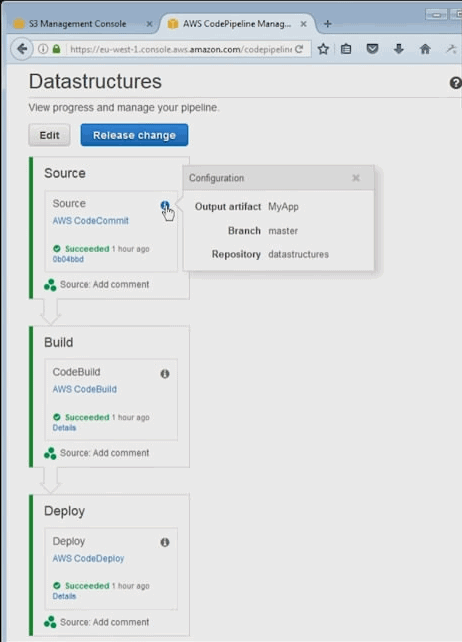
On peut le voir dans S3 Management Console le bucket, il y a la liste des fichiers zip qui contiennent ces sources. C'est tout simplement le résultat de git pool qui a été fait par codePipeline. Toutes les versions succéssives, qui correspondent à tous les builds successifs.
He bien ensuite j'ai une étape de build, qui est faite par codeBuild. On prend comme artéfact d'entrée MyApp. Et il va produire un artéfact de sortie qui s'appelle MyAppBuild et qui va être un zip avec le binaire qu'il a produit.
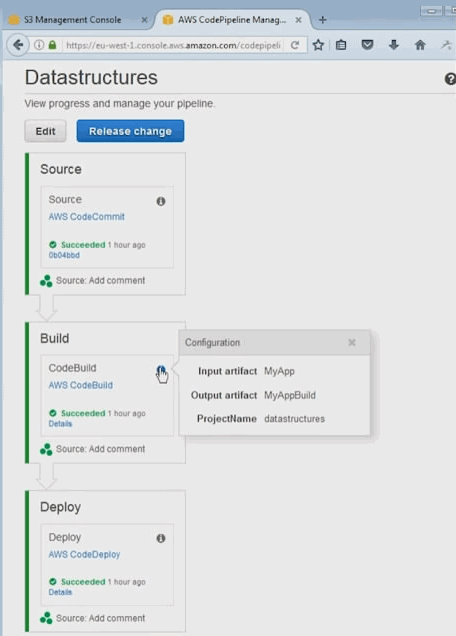
All Buckets / codepipeline-eu-west-1-305897873145 / Datastructures / MyApp All Buckets / codepipeline-eu-west-1-305897873145 / Datastructures / MyAppBuild
On a vu à l'instant myApp qui contient les sources zippés, et de manière symétrique on va avoir myAppBuild, c'est un fichier zip qui va contenir les artéfacts qui j'ai demandé à codeBuild de produire. Donc les deux librairies et puis les fichiers de configuration pour le déploiement.
Une fois que le build est terminé, il y a une étape de déploy, qui prend comme artefact d'entrée MyAppBuild, et qui va le déployer sur un groupe de déploiement que j'ai appelé datastructuresEC2 qui est configuré dans codeDeploy. Et donc c'est ça qui va faire la livraison de ma librairie.
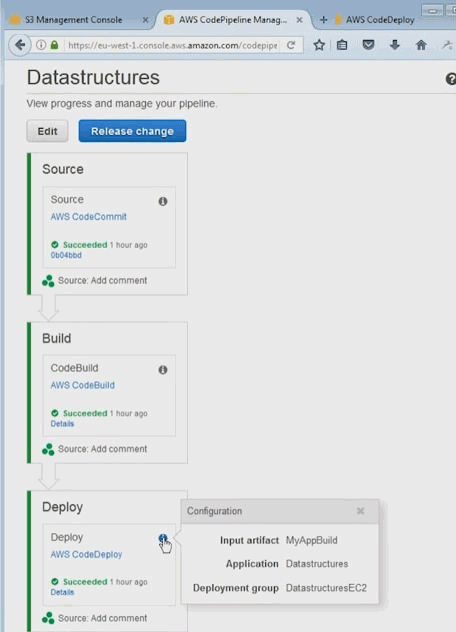
Si je vais dans codeDeploy, j'ai créé une application qui s'appelle datastructure et un groupe de déploiement qui s'appelle datastructureEC2
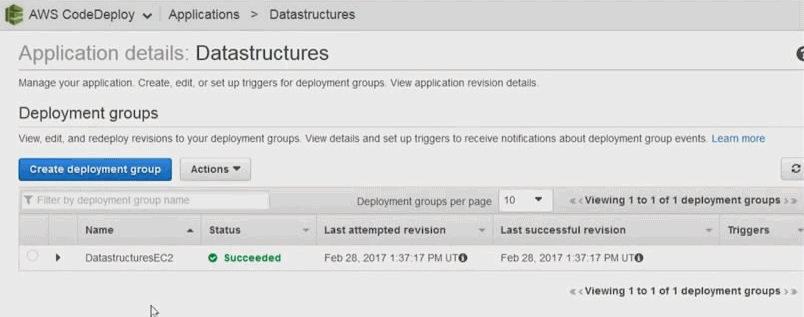
Le groupe de déploiement est un ensemble d'instances EC2 qui ont un tag déclaré. Pour qu'une instance EC2 soit dans ce groupe de déploiement, il faut qu'elle ai un tag DeploymentGroup, et qui ai la valeur Datastructures. Cette configuration permet d'ajouter ou d'enlever facilement des instances dans un groupe de déploiement.
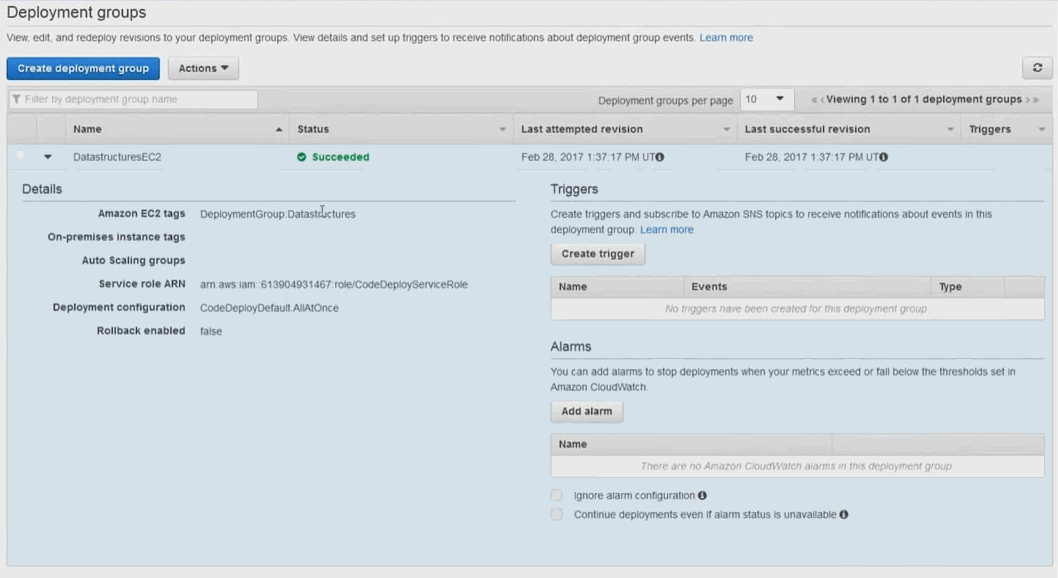
Il est possible d'exécuter des taches en parallèles dans un block. Il est aussi très facile d'éditer le pipeline. Par ex pour ajouter une action de déploiement:
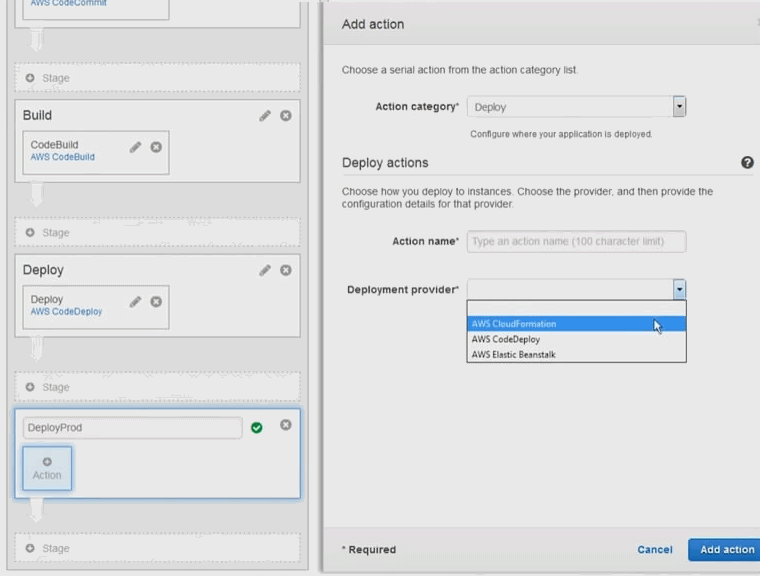
Le fournisseur de déploiement AWS CloudFormation, permet d'avoir un template cloudFormation qui va déployer les conteners sur ECS, et on va mettre à jour dans le template cloudFormation, la référence de l'image docker qui est associé au container, et on va donc ré-appliquer le template avec cette mise à jour. On met toutes les informations dans des template cloudFormation. On les met à jour dans le build et on ré-applique pour refaire le déploiement.
Après un commit, le pipeline est déclenché. Il est ensuite possible de voir le log pour débuguer son build.
réf: Configurer un pipeline de déploiement en continu
https://aws.amazon.com/fr/getting-started/hands-on/continuous-deployment-pipeline/